This forum is disabled, please visit https://forum.opencv.org
| 2017-03-18 05:30:21 -0600 | received badge | ● Famous Question (source) |
| 2016-10-04 10:14:34 -0600 | received badge | ● Nice Answer (source) |
| 2016-04-17 08:10:18 -0600 | received badge | ● Notable Question (source) |
| 2015-10-09 08:02:29 -0600 | received badge | ● Nice Answer |
| 2015-10-08 19:54:33 -0600 | received badge | ● Student (source) |
| 2015-10-01 11:59:13 -0600 | received badge | ● Popular Question (source) |
| 2015-02-04 13:49:04 -0600 | commented question | List of available python bindings A colleague just pointed out you can use ipython as an interactive python shell and press cv2.<tab> |
| 2015-02-04 13:48:39 -0600 | commented question | List of available python bindings Thanks! Consider adding it as an actual "answer". |
| 2015-02-04 12:50:12 -0600 | asked a question | List of available python bindings Is there a file or some other way of quickly finding a list of all available python bindings, especially also the constants. This is both interesting to be answered for both cases with and without source code. |
| 2014-10-22 07:49:35 -0600 | received badge | ● Necromancer (source) |
| 2014-10-22 06:33:00 -0600 | answered a question | Image stitching - why does the pipeline include 2 times resizing? As far as I know there are different scales used in different stages of the pipeline. Initially there is something called work_scale, which resizes the images to a more convenient size (trade-off between quality/processing time). Then there is something called seam_scale, which is used right after feature detection/description. During "seam finding" the stitching pipeline finds the best seams where to cut off two overlapping images. In other words, it looks better to cut off where neighbouring pixels are similar instead of assuming that the pixels along the image boundary will look like the other picture. Finally there is something called compose_scale, which, I think, is used to control the final stitched image size. |
| 2014-10-22 06:10:59 -0600 | commented question | Adaptation of OpenCV stitcher Hi Manatttta, it would be great to catch up on progress. I also did some changes to estimate 1) a fundamental matrix F instead of a homography in the first place, 2) extract the essential matrix E from F, 3) extract rotation and translation from E. Unfortunately something is still wrong, but I am sure this is the way to go. It would be interesting to catch up, but I don't know how to contact you. |
| 2014-08-26 10:14:19 -0600 | asked a question | Theory behind estimating rotation in motion_estimators.cpp (CalcRotation) I am trying to understand the theory behind parts of the stitching pipeline in order to support not only camera rotation, but translation as well. The relevant part of the code is in /modules/stitching/src/motion_estimators.cpp (lines 60pp):
In this part of the code the stitcher tries to estimate the camera parameters between two views "from" and "to". (The input is a graph of matching images and estimated homographies are given). I understand the code assumes constant intrinsic parameters. Estimated calibration parameters are used to set up K_from and K_to, the intrinsic calibration parameters of the two views. Next, extrinsic parameters are estimated with the core assumption that cameras do not translate! In Szeliski - Computer Vision: Algorithms and Applications (9.1.3 Rotational panoramas) the relation between the extrinsic parameters and the homography between the two views is explained:
I try to derive the last two lines of the code based on this formula. For simplicity I (assume and) define
Here we go (starting with what the algorithm is doing)
Apparently I don't know whether Hxy = H01 or Hxy = H10. Intuitively I would assume the homography estimated is the one from the "from" camera to the "to" camera. So H01.inv would mean we are talking about R10. Continuing with the formula... Here's the problem. No matter how I look at it, I always end up questioning why R0 is multiplied from the left side and not the right side. Assuming Hxy = H10 does not solve the problem. It would be great if anyone could review the formula and verify some of the assumptions I made. In particular
|
| 2014-08-13 08:57:22 -0600 | commented question | Estimate camera pose (extrinsic parameters) from homography / essential matrix Thanks, that's good advice. I haven't completely tried it out yet, but at the core, where it estimates R|t from the essential matrix, it does so very much in the way it is explained in Hartley & Zisserman. There is a very detailed answer here with a python implementation: http://answers.opencv.org/question/27155/from-fundamental-matrix-to-rectified-images/. Based on the referenced python script, I now stick to the textbook implementation and assume that my essential matrix is still incorrect. I will have to review the way I compute it and hopefully the singular values won't be that far off each other anymore. I believe the reasons why the results with my implementation looked "useful" before are 1) the translation is almost zero anyway and 2) I ultimately only rotate/mirror the cams |
| 2014-07-31 03:07:42 -0600 | received badge | ● Necromancer |
| 2014-07-30 09:31:50 -0600 | commented answer | From Fundamental Matrix To Rectified Images Thank you very much, this explains a lot to me!! |
| 2014-07-30 09:16:11 -0600 | commented answer | opengl Triangulate Points Wow, look at this more detailed explanation: http://answers.opencv.org/question/27155/from-fundamental-matrix-to-rectified-images/ |
| 2014-07-30 08:57:28 -0600 | commented answer | opengl Triangulate Points It appears there is some code available in Chapter 4 of "Mastering OpenCV" book. See here: https://github.com/MasteringOpenCV/code/blob/master/Chapter4_StructureFromMotion/FindCameraMatrices.cpp |
| 2014-07-30 07:45:47 -0600 | received badge | ● Necromancer (source) |
| 2014-07-30 07:26:23 -0600 | answered a question | Stitching: how to get camera translation into bundle adjustment? The Stitcher class was originally designed for a camera that rotates around itself. Therefore no translation is supported. In summary, there are a number of stages in the pipeline affected by this. 1) Initially, homographies are estimated between pairs of matching images. The intrinsic camera parameters are estimated (focal length, aspect ratio, image center), then the extrinsic parameters (rotation, translation). Here translation is assumed to be 0. 2) During bundle adjustment, the translation is ignored and not updated. I have skipped this stage for now, but it is quite an important one. You could try out a different bundle adjustment library other than OpenCV, such as SBA. There exists an OpenCV wrapper for SBA. See also this thread. I have not tried any of this, but please let me know, if you succeed. 3) The warping stage supports rotation only as well. I've noticed that the PlaneWarper has functions, which accept camera translation as well, but I am not sure whether this is actually working. |
| 2014-07-30 06:13:24 -0600 | commented answer | Creating a panorama from multiple images. How to reduce calculation time? Here is a nice article https://software.intel.com/en-us/articles/fast-panorama-stitching |
| 2014-07-30 05:47:23 -0600 | received badge | ● Teacher (source) |
| 2014-07-30 04:52:47 -0600 | commented question | Adaptation of OpenCV stitcher You could look at the stitching detailed example, where each step of the pipeline is explicit. You have to skip estimating homographies and instead set all camera pose to [I|0]. You can calibrate the camera initially and set those values in CameraParams. I also found that PlaneWarper has an API slightly different from all other warpers. It accepts translation as well, although I am not sure what it exactly means. In my scenario I want it to tell that the camera is moving. In your scenario your camera is not moving, but your basically simulating a moving camera by moving the scene. So algorithmically you should pretend that your camera is moving and set the translation of the camera to the translation that you know. |
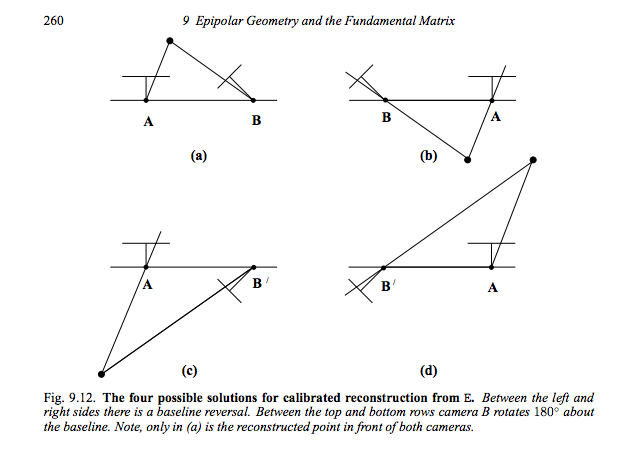
| 2014-07-29 12:50:57 -0600 | asked a question | Estimate camera pose (extrinsic parameters) from homography / essential matrix I am trying to estimate the camera pose from an estimated homography as explained in chapter 9.6.2 of Hartley & Zisserman's book. Basically, it says the following: Let Given an SVD decomposition of the essential matrix the extrinsic camera parameters [R|t] of the right camera are one of the following four solutions: Now I am struggling with a few main issues. 1) I only have access to an estimated homography the SVD decomposes into something like It's really weird that the singular values are not almost identical and that large. My first question is why this happens and what to do about it? Normalization? Scaling? 2) After a lot of thinking and more experimenting, I came up with the following implementation: This way I get four possible solutions Apparently, in W, I don't swap x/y coordinates and I don't invert the x-coordinate. Only the y-coordinate is inverted. I believe the swap can be explained by different image coordinate systems. So column and row might be inverted in my implementation. But I can't explain why I only have to mirror and not rotate. And overall I am not sure, if the implementation is correct. 3) In theory I think I need to triangulate a pair of matches and determine whether the 3D point is front of both planes. Only one of the four solutions will satisfy that condition. However, I don't know how to determine the near plane's normal and distance from the uncalibrated projection matrix. 4) This is all used in the context of image stitching. My goal is to enhance the current image stitching pipeline to support not only cameras rotating around itself, but also translating cameras with little rotation. Some preliminary results and a follow-up question will be posted soon. (TODO) |
| 2014-07-29 06:54:05 -0600 | received badge | ● Supporter (source) |
| 2014-07-29 06:50:22 -0600 | answered a question | opengl Triangulate Points
You are extracting the camera's extrinsic parameters from the essential matrix (homography between two calibrated camera planes). The first camera is assumed to be fixed at It would be interesting to know where you got the code from, because I am currently trying to find out as well how to project the points and test if they are in front of the cameras. Note, in Szeliski's book the assumption is made that the SVD decomposes the matrix into However, I got a related problem. My singular values are not equal at all and in summary I chose the following implementation: I am not sure about it, but maybe it helps you. I am also stuck at the point where I have to chose the correct matrix by triangulating a matching point and testing whether it is in front of both cameras.
Image from Hartley, R. I. and Zisserman, A. - Multiple View Geometry in Computer Vision, 2004 |
| 2014-07-22 02:24:00 -0600 | received badge | ● Necromancer (source) |
| 2014-07-21 11:32:23 -0600 | commented answer | Image Stitching with OpenCV One of the limitations of the stitching demos is that they assume a fixed camera that is rotating around its axis. |
| 2014-07-21 11:27:49 -0600 | received badge | ● Editor (source) |
| 2014-07-21 11:27:34 -0600 | answered a question | FeatureDetector vs. FeatureFinder FeatureFinder is a high-level class that abstracts feature detection + description. SIFT/SURF/ORB all describe a detection and a description scheme, but most of the time they are perceived as descriptors. Separating both will give you much more flexibility: |
| 2014-07-21 11:01:58 -0600 | answered a question | How can I add my own feature code into sticther pipeline of OpenCV? If you stick to the stitching_detailed example you can actually replace the FeaturesFinder part with a detector + descriptor combination of your choice. Here's an excerpt: .... |
| 2014-07-21 10:50:03 -0600 | commented question | Panorama stitching with very uniform images I've read a paper once called "Reconstructing Building Interiors". It uses Manhattan World assumption and computes the main three orthogonal axes of the scene. But it has quite a large pipeline, first computing a sparse 3d point cloud with, then a dense, then Manhattan World... But maybe you can take some ideas out of it. |
| 2014-07-21 10:36:51 -0600 | commented answer | How would you stitch those two images as if they are taken from single camera just from the mid side of the field? Problem 1 - too little overlap: I don't think the overlap is too little. The images seem of quite large resolution. However, you should restrict matching to a ROI of expected overlap. I think it's around 25% of the image. Problem 2 - using geometrical symmetry: I have the feeling there are plenty of corner features so point correspondences should work. You might want to look into large baseline stereo (numerical stability?). Did you try different feature detectors/descriptors and different scale space settings? I'd try to detect 20-30 stable features, if possible. Note, if you have tried the detailed_stitching demo of OpenCV only, it is assuming a fixed camera rotation. But your camera is translated and rotated. |
| 2014-07-16 06:27:49 -0600 | answered a question | Providing Panorama Stitcher with Camera Rotations Looking both at the high-level Stitcher class and the detailed demo in samples/stitching_detailed.cpp, you would have to work here: In a sense, you already have computed the homographies frame-by-frame. Therefore you can skip re-estimating homographies for all frames. When you set the cameras to you guesses, they are used by the bundle adjustment as initial guesses. However, it doesn't seem that the current stitching pipeline can update only the (k-)newest frame(s). So this approach would work if you record a video and stitch the images together finally. If you wanted to stitch continuously, you'd have to construct a more complex pipeline. |