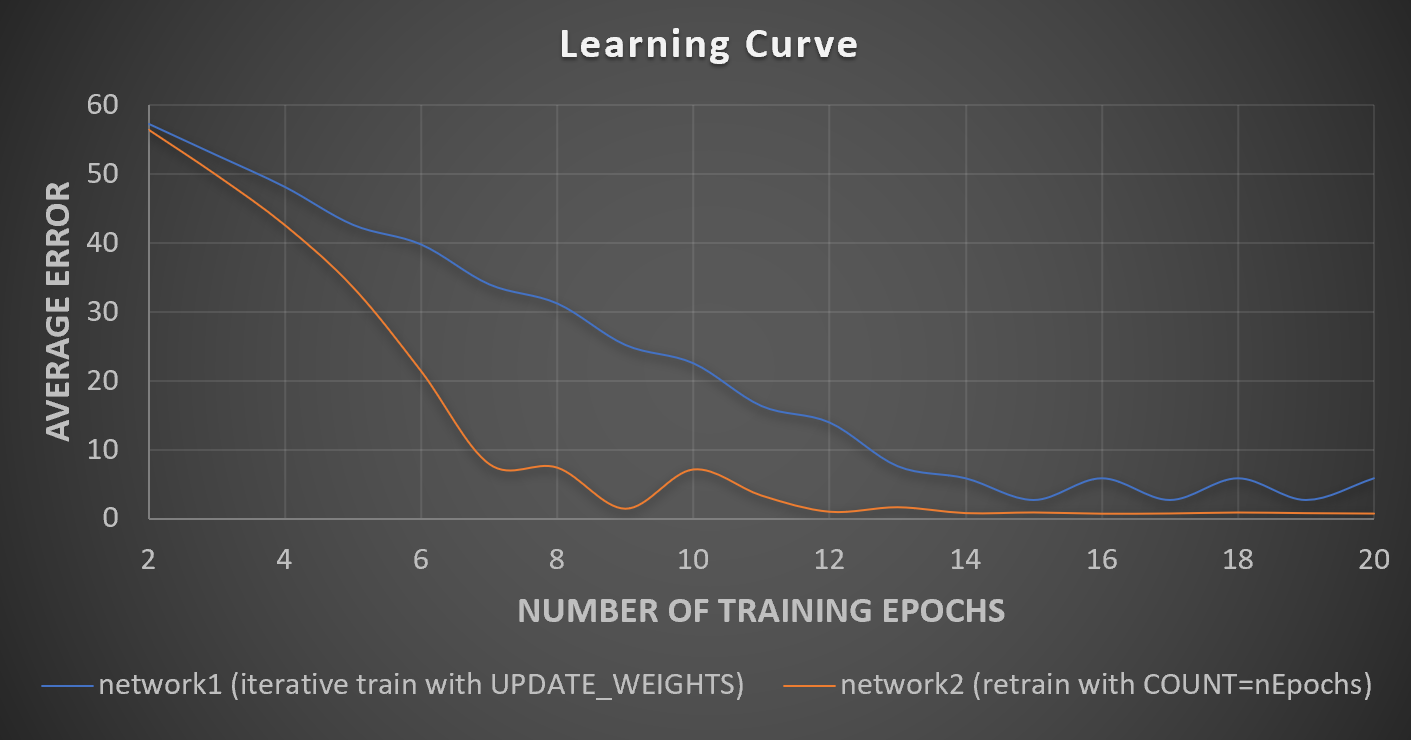
Doing some benchmarks and I want to make learning curves, showing error versus number of training epochs. The quickest way would be to output error after each epoch. I thought this could be accomplished using UPDATE_WEIGHTS, however the code is acting wonky. It works differently if you were to say specify the network to terminate after 10 epochs, or if you were to loop it and use UPDATE_WEIGHTS 10 times. These should be exactly the same thing though shouldn't they?
See code example below showing exactly what I mean. It is a simple application of an MLP that learns how to add two numbers.
OpenCV 4.0.1
MacBook Pro 64 bit
Eclipse C++
// make train data showing simple addition
int nTrainRows = 1000;
cv::Mat trainMat(nTrainRows, 2, CV_32F);
cv::Mat labelsMat(nTrainRows, 1, CV_32F);
for(int i = 0; i < nTrainRows; i++) {
double rand1 = rand() % 100;
double rand2 = rand() % 100;
trainMat.at<float>(i, 0) = rand1;
trainMat.at<float>(i, 1) = rand2;
labelsMat.at<float>(i, 0) = rand1 + rand2;
}
// make test data
int nTestRows = 1;
cv::Mat testMat(nTestRows, 2, CV_32F);
cv::Mat truthsMat(nTestRows, 1, CV_32F);
for(int i = 0; i < nTestRows; i++) {
double rand1 = rand() % 100;
double rand2 = rand() % 100;
testMat.at<float>(i, 0) = rand1;
testMat.at<float>(i, 1) = rand2;
truthsMat.at<float>(i, 0) = rand1 + rand2;
}
// initialize network1
cv::Ptr<cv::ml::ANN_MLP > network1 = cv::ml::ANN_MLP::create();
cv::Mat layersMat(1, 2, CV_32SC1);
layersMat.col(0) = cv::Scalar(trainMat.cols);
layersMat.col(1) = cv::Scalar(labelsMat.cols);
network1->setLayerSizes(layersMat);
network1->setActivationFunction(cv::ml::ANN_MLP::ActivationFunctions::SIGMOID_SYM);
network1->setTermCriteria(cv::TermCriteria(cv::TermCriteria::COUNT + cv::TermCriteria::EPS,1,0));
cv::Ptr<cv::ml::TrainData> trainData = cv::ml::TrainData::create(trainMat,cv::ml::ROW_SAMPLE,labelsMat,cv::Mat(),cv::Mat(),cv::Mat(),cv::Mat());
network1->train(trainData);
// train and test by varying the number of epochs
for(int nEpochs = 2; nEpochs <= 9; nEpochs++) {
cout << "nEpochs=" << nEpochs << endl;
// train/update network1 with new weights
network1->train(trainData,cv::ml::ANN_MLP::UPDATE_WEIGHTS);
cv::Mat predictions;
network1->predict(testMat, predictions);
for(int i = 0; i < nTestRows; i++) {
cout << "network1 with UPDATE_WEIGHTS... "
<< testMat.at<float>(i,0) << "+" << testMat.at<float>(i,1)
<< " = " << truthsMat.at<float>(i, 0) << " =? " << predictions.at<float>(i, 0)
<< " error=" << abs( truthsMat.at<float>(i, 0) - predictions.at<float>(i, 0) ) << endl;
}
// init and train network2 from ground up, specifying the count = nEpochs
cv::Ptr<cv::ml::ANN_MLP > network2 = cv::ml::ANN_MLP::create();
network2->setLayerSizes(layersMat);
network2->setActivationFunction(cv::ml::ANN_MLP::ActivationFunctions::SIGMOID_SYM);
network2->setTermCriteria(cv::TermCriteria(cv::TermCriteria::COUNT+cv::TermCriteria::EPS,nEpochs,0));
network2->train(trainData);
network2->predict(testMat, predictions);
for(int i = 0; i < nTestRows; i++) {
cout << "network2 with COUNT=nEpochs... "
<< testMat.at<float>(i,0) << "+" << testMat.at<float>(i,1)
<< " = " << truthsMat.at<float>(i, 0) << " =? " << predictions.at<float>(i, 0)
<< " error=" << abs( truthsMat.at<float>(i, 0) - predictions.at<float>(i, 0) ) << endl;
}
}
This outputs:
nEpochs=2
network1 with UPDATE_WEIGHTS... 87+75 = 162 =? 49.0659 error=112.934
network2 with COUNT=nEpochs... 87+75 = 162 =? 52.3952 error=109.605
nEpochs=3
network1 with UPDATE_WEIGHTS... 87+75 = 162 =? 66.0874 error=95.9126
network2 with COUNT=nEpochs... 87+75 = 162 =? 77.3854 error=84.6146
nEpochs=4
network1 with UPDATE_WEIGHTS... 87+75 = 162 =? 83.8339 error=78.1661
network2 with COUNT=nEpochs... 87+75 = 162 =? 108.564 error=53.4359
nEpochs=5
network1 with UPDATE_WEIGHTS... 87+75 = 162 =? 91.5657 error=70.4343
network2 with COUNT=nEpochs... 87+75 = 162 =? 114.608 error=47.3916
nEpochs=6
network1 with UPDATE_WEIGHTS... 87+75 = 162 =? 98.5976 error=63.4024
network2 with COUNT=nEpochs... 87+75 = 162 =? 132.864 error=29.1357
nEpochs=7
network1 with UPDATE_WEIGHTS... 87+75 = 162 =? 106.354 error=55.6464
network2 with COUNT=nEpochs... 87+75 = 162 =? 146.292 error=15.7078
nEpochs=8
network1 with UPDATE_WEIGHTS... 87+75 = 162 =? 113.352 error=48.6481
network2 with COUNT=nEpochs... 87+75 = 162 =? 169.54 error=7.53975
nEpochs=9
network1 with UPDATE_WEIGHTS... 87+75 = 162 =? 121.01 error=40.9899
network2 with COUNT=nEpochs... 87+75 = 162 =? 161.719 error=0.28093
You can see that network1 (using UPDATE_WEIGHTS) and network2 (using COUNT) act very differently even though the number of training epochs is the same. The error from network2 converges much more quickly. I can not find a reason why this would be the case, as they should be the same?
-Tim