ANN_MLP using UPDATE_WEIGHTS to graph error - broken
I ran into this problem while trying to make a learning curve of an MLP I was using to predict 4 output values across 30,000 samples. I wanted to use UPDATE_WEIGHTS to output the error after each training epoch. That way I can graph it and look at trends.
When training the network and setting the termination criteria COUNT=1000 the network received ~5% error. The problem is that when I used UPDATE_WEIGHTS to iteratively train the network 1 epoch at time, the error did not converge to the same value, or with a similar trend.
I provided code below for a simple example that illustrates the same UPDATE_WEIGHTS issue, just so you can clearly see what the problem is. The example uses an MLP to learn how to add two numbers, and compares iteratively training the network using UPDATE_WEIGHTS nEpoch number of times (network1) to retraining the network and using termination criteria COUNT = nEpochs (network2).
OpenCV 4.0.1
MacBook Pro 64 bit
Eclipse C++
// create train data
int nTrainRows = 1000;
cv::Mat trainMat(nTrainRows, 2, CV_32F);
cv::Mat labelsMat(nTrainRows, 1, CV_32F);
for(int i = 0; i < nTrainRows; i++) {
double rand1 = rand() % 100;
double rand2 = rand() % 100;
trainMat.at<float>(i, 0) = rand1;
trainMat.at<float>(i, 1) = rand2;
labelsMat.at<float>(i, 0) = rand1 + rand2;
}
// create test data
int nTestRows = 100;
cv::Mat testMat(nTestRows, 2, CV_32F);
cv::Mat truthsMat(nTestRows, 1, CV_32F);
for(int i = 0; i < nTestRows; i++) {
double rand1 = rand() % 100;
double rand2 = rand() % 100;
testMat.at<float>(i, 0) = rand1;
testMat.at<float>(i, 1) = rand2;
truthsMat.at<float>(i, 0) = rand1 + rand2;
}
// initialize network1 and set network parameters
cv::Ptr<cv::ml::ANN_MLP > network1 = cv::ml::ANN_MLP::create();
cv::Mat layersMat(1, 2, CV_32SC1);
layersMat.col(0) = cv::Scalar(trainMat.cols);
layersMat.col(1) = cv::Scalar(labelsMat.cols);
network1->setLayerSizes(layersMat);
network1->setActivationFunction(cv::ml::ANN_MLP::ActivationFunctions::SIGMOID_SYM);
network1->setTermCriteria(cv::TermCriteria(cv::TermCriteria::COUNT + cv::TermCriteria::EPS, 1, 0));
cv::Ptr<cv::ml::TrainData> trainData = cv::ml::TrainData::create(trainMat,cv::ml::ROW_SAMPLE,labelsMat,cv::Mat(),cv::Mat(),cv::Mat(),cv::Mat());
network1->train(trainData);
// loop through each epoch, one at a time, and compare error between the two methods
for(int nEpochs = 2; nEpochs <= 20; nEpochs++) {
// train network1 with one more epoch
network1->train(trainData,cv::ml::ANN_MLP::UPDATE_WEIGHTS);
cv::Mat predictions;
network1->predict(testMat, predictions);
double totalError = 0;
for(int i = 0; i < nTestRows; i++)
totalError += abs( truthsMat.at<float>(i, 0) - predictions.at<float>(i, 0) );
double aveError = totalError / (double) nTestRows;
//recreate network2
cv::Ptr<cv::ml::ANN_MLP > network2 = cv::ml::ANN_MLP::create();
network2->setLayerSizes(layersMat);
network2->setActivationFunction(cv::ml::ANN_MLP::ActivationFunctions::SIGMOID_SYM);
network2->setTermCriteria(cv::TermCriteria(cv::TermCriteria::COUNT + cv::TermCriteria::EPS, nEpochs, 0));
// train network2 from scratch, specifying to train with nEpochs
network2->train(trainData);
network2->predict(testMat, predictions);
totalError = 0;
for(int i = 0; i < nTestRows; i++)
totalError += abs( truthsMat.at<float>(i, 0) - predictions.at<float>(i, 0) );
aveError = totalError / (double) nTestRows;
}
I graphed the average error vs the number of training epochs used:
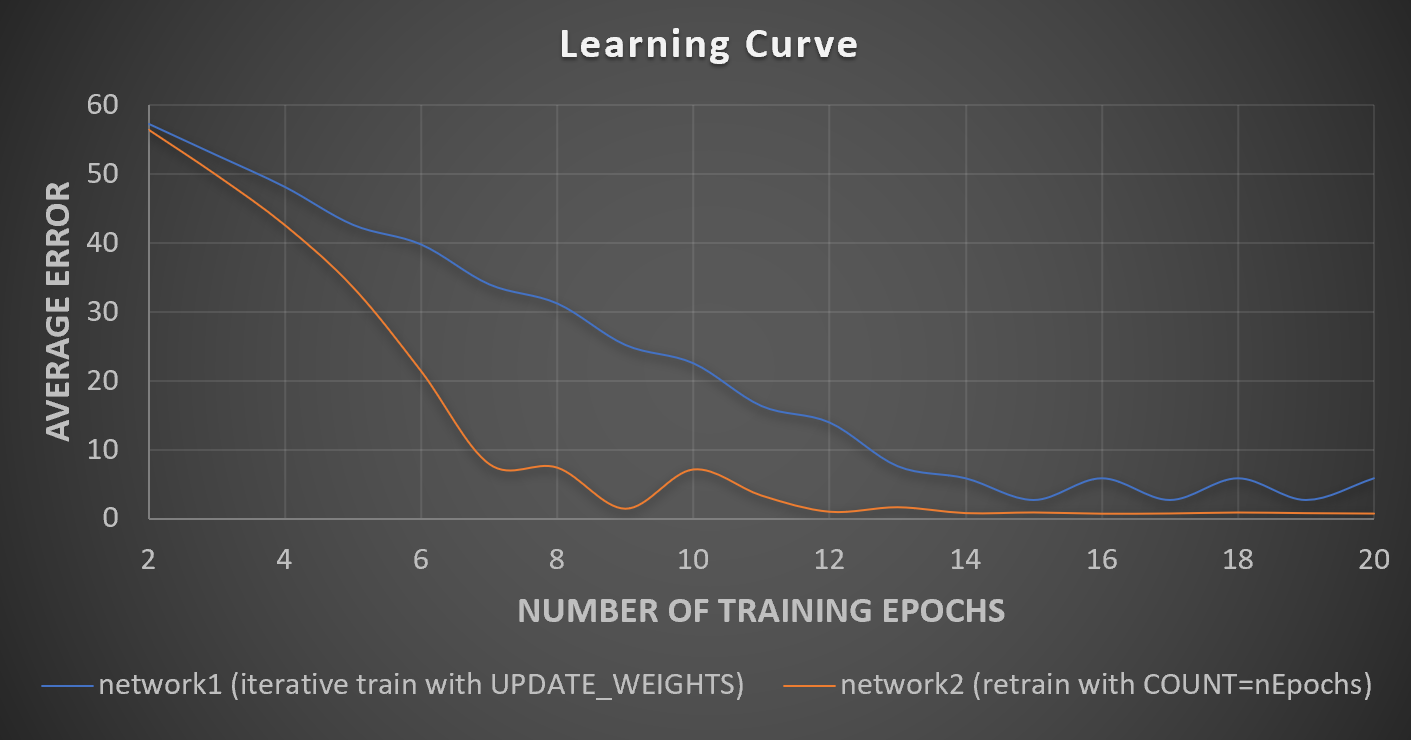
You can see that network1 (using ...
Have you tried to do the XOR problem?
Can you try with those line for seed ?
It’s the same results if I comment out the random seed lines.
What would be the point of trying the XOR problem?
Let's try to explain (with my bad englisg) : in source code data are shufled when idx ==0 and it depends of iter. when you set iter to 1 or nEpochs you don't shuffle datasame time? is it correct ?
Shuffling data differently shouldn’t have that big of an effect on how quickly the error converges?
Your network is random network. It's a regression problem isn't it?
Yes it’s a regression problem. The training data is still the same for both network1 and network2. Shouldn’t the randomness balance out after doing multiple epochs (each epoch reshuffles the data)
try with :
and
and nTestRows=3 what is your question? backpropagation uses a way to find a solution but this way depends of data
Hey LBerger I rewrote the question to be more clear what the problem is.