Preprocessing before OCR
Hi all,
I'm pretty new to CV, I'm doing some experiment that requires OCR, I'm ussing tesseract as the OCR Engine.
I have the following image:

I was trying applying all kind of preprocessing techniques but wasn't able to filter all the noise and have only the text.
(I'm interested in ARS, 0 - 1, TOT, 04:02)
My biggest issue is finding a way to filter those texts even though I know their color (the fact that they are gradient makes it even a bigger issue for me)
any tips/ideas on how to tackle this problem?
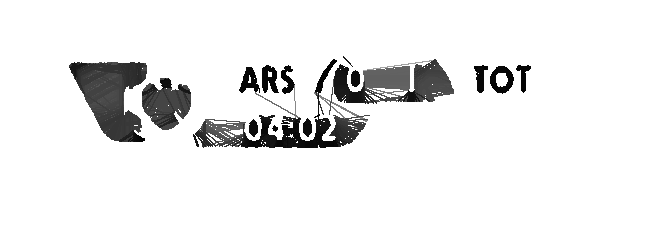
some example of the image after some processing (which aren't good enough as the tesseract fails with reading it):
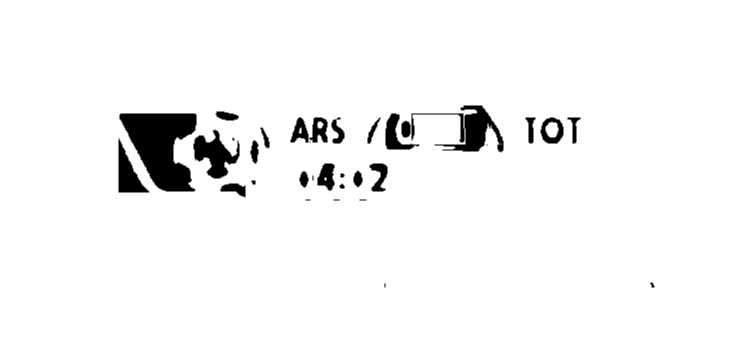
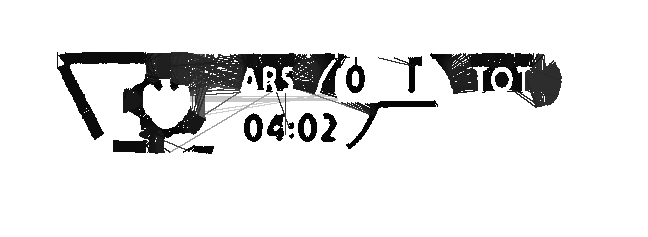
{kind=link}
You can try Stroke Width Transform to get probable location of text: Detecting Text in Natural Scenes with Stroke Width Transform (never tested it). Have you already tried Canny edge detection?
Usually, TV logos are always at the same place. It is a kind of cheat but this should facilitate your work.
Yeah, the fact that I know where the banner is should be helpful and I can cut the desired area the problem is the resolution and the noise.