Cascade Training Error OpenCV 3.1 - Train dataset for temp stage can not be filled. Branch training terminated. Cascade classifier can't be trained. Check the used training parameters.
"Train dataset for temp stage can not be filled. Branch training terminated. Cascade classifier can't be trained. Check the used training parameters."
I'm really struggling on this error. It's taking me forever to solve it.
I've already read
- http://answers.opencv.org/question/16...
- http://answers.opencv.org/question/10...
- http://stackoverflow.com/questions/11...
- http://stackoverflow.com/questions/20...
and I'm doing the same as the following tutorials:
I couldn't find any real solution, hence I'm updating the question.
I'm using OpenCV 3.1.0 with Python on a Macbook with 8 GB of memory (Unix).
Here you can find the folder structure and files of my project. (Negative and Positive folders, the .vec file, and a sample of both images database).
I have in total 500(640 × 240) positive images and 2988(640 × 480) negative images.
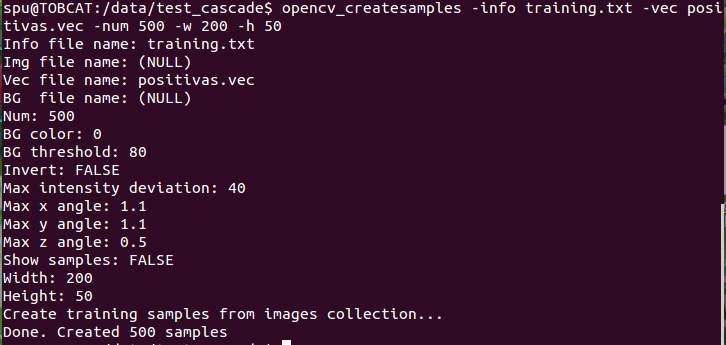
The command that I used to create de .vec file (at the directory Positivas) was :
opencv_createsamples -vec Placas_Positivas.vec -info Training.txt -num 500 -w 200 -h 50 (just like as here)
The command that I'm using (at the directory Cascade_Training) is:
opencv_traincascade -data Data -vec Positivas/Placas_Positivas.vec -bg Negativas/Training_Negatives.txt -numPos 400 -numNeg 2500 -numStages 15 -w 200 -h 50 -featureType LBP
and NO MATTER WHAT I DO, I always see the result in the following image:
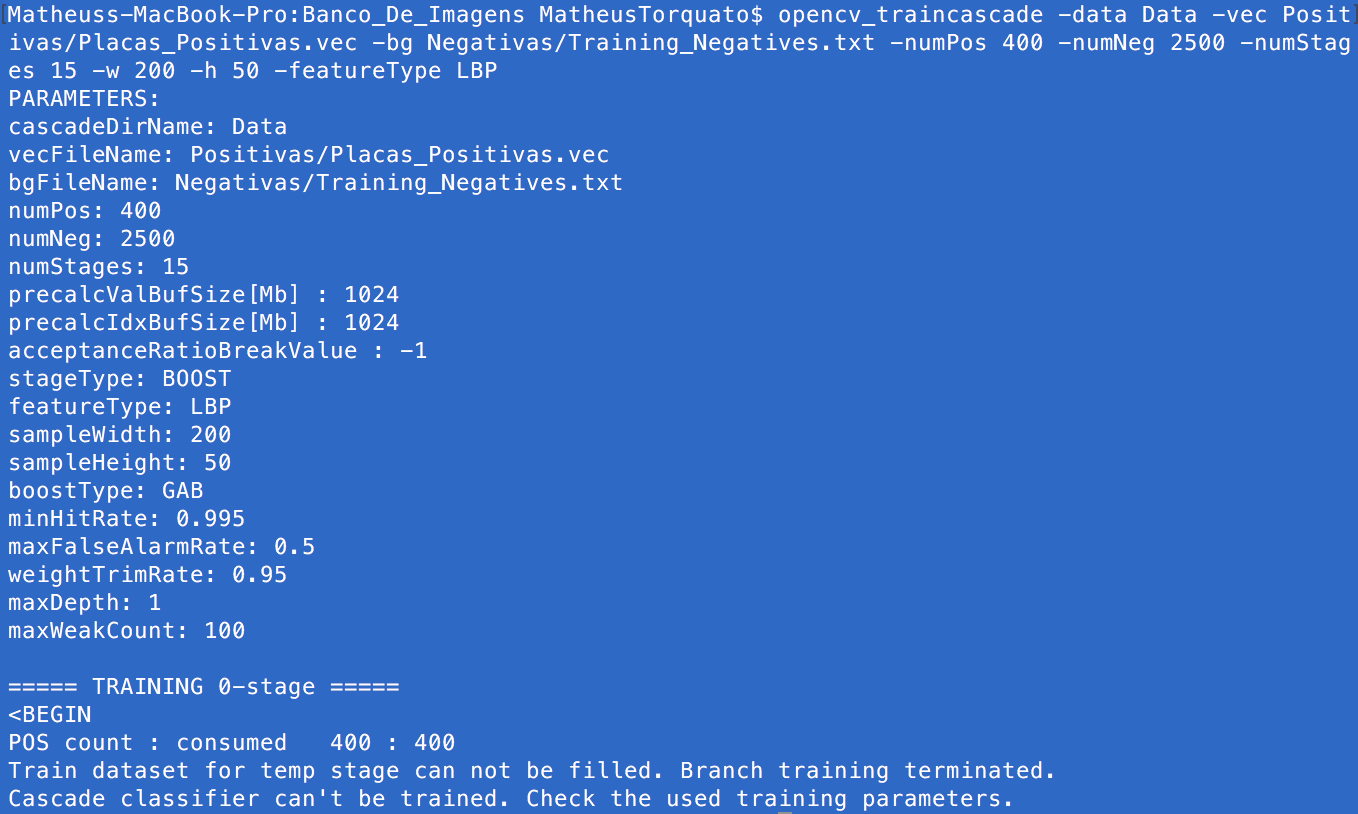
Any help?

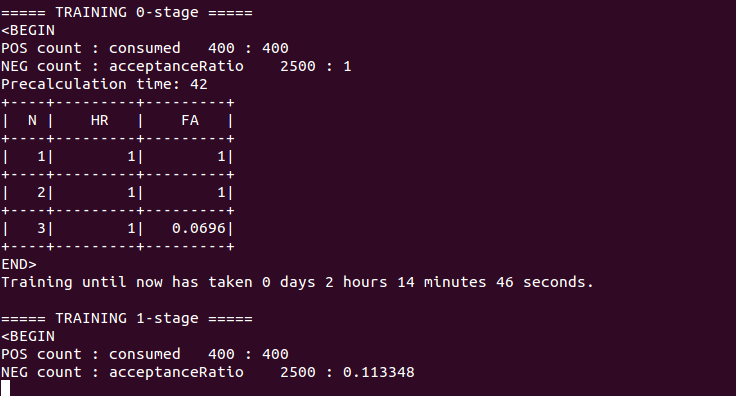
Okay some initial questions
Update your question and I will get back to you helping you to solve this.
Thanks for adding the data. I am going to try it myself now and report back to you!
I've updated with all your questions. Thanks for your fast response. As I posted, you can check my folders and files here
I hope we can solve this problem now =)