This forum is disabled, please visit https://forum.opencv.org
| | 1 | initial version |
Ok downloading and inspecting your data, I have found already tons of problems
Training_Negativas.txt file, I see the following structure Images/UMD_001.jpg which is asking for trouble. Start by changing those to absolute paths, so that the software reading it will always find the exact image. For example it could be /data/Images/UMD_001.jpg. Relative paths always generate problems...Training.txt, which has the same problem, but somehow you seemed to have trained the *.vec file so it might have been going good.Training.txt is seperated using tabs, while it is stated that data should be seperated by spaces. If you do this with tabs, I am afraid it is already possible that your vec file is actually filled with rubbish.Could you supply the missing 10 images so I can perform tests to see if it works when fixing all this?
| | 2 | No.2 Revision |
Ok downloading and inspecting your data, I have found already tons of problems
Training_Negativas.txt file, I see the following structure Images/UMD_001.jpg which is asking for trouble. Start by changing those to absolute paths, so that the software reading it will always find the exact image. For example it could be /data/Images/UMD_001.jpg. Relative paths always generate problems...Training.txt, which has the same problem, but somehow you seemed to have trained the *.vec file so it might have been going good.Training.txt is seperated using tabs, while it is stated that data should be seperated by spaces. If you do this with tabs, I am afraid it is already possible that your vec file is actually filled with rubbish.Could you supply the missing 10 images so I can perform tests to see if it works when fixing all this?
UPDATE
After changing the data structure as follows [WILL ADD HERE LATER] I ran the opencv_createsamples tool first with the following result
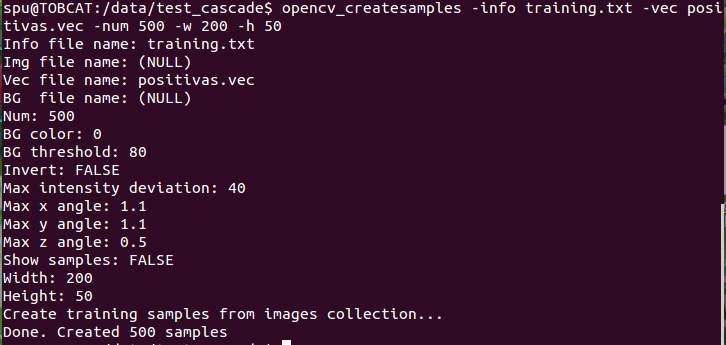
Then I ran the training command like this
opencv_traincascade -data cascade/ -vec positivas.vec -bg negativas.txt -numPos 400 -numNeg 2500 -numStages 15 -w 200 -h 50 -featureType LBP -precalcValBufSize 4048 -precalcIdxBufSize 4048 -numThreads 24
Watch the fact that I increased the memory consumption ... because your system can take more than the standard 1GB per buffer AND I set the number of threads to take advantage from that.
Training starts for me and features are being evaluated. However due to the amount of unique features and the size of the training samples this will take long...
Looking at the memory consumption, this data uses a full blown 8.6GB, so you might want to lower those buffers to ensure that no swapping will happen and that it will cripple the system.
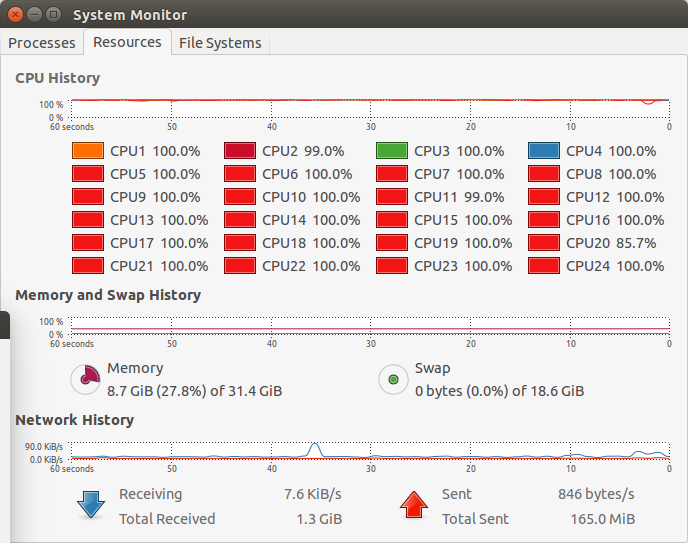
will update once a first stage is succesfully trained, and will increase memory to speed the process up
| | 3 | No.3 Revision |
Ok downloading and inspecting your data, I have found already tons of problems
Training_Negativas.txt file, I see the following structure Images/UMD_001.jpg which is asking for trouble. Start by changing those to absolute paths, so that the software reading it will always find the exact image. For example it could be /data/Images/UMD_001.jpg. Relative paths always generate problems...Training.txt, which has the same problem, but somehow you seemed to have trained the *.vec file so it might have been going good.Training.txt is seperated using tabs, while it is stated that data should be seperated by spaces. If you do this with tabs, I am afraid it is already possible that your vec file is actually filled with rubbish.Could you supply the missing 10 images so I can perform tests to see if it works when fixing all this?
UPDATE
After changing the data structure as follows [WILL ADD HERE LATER] I ran the opencv_createsamples tool first with the following result
Then I ran the training command like this
opencv_traincascade -data cascade/ -vec positivas.vec -bg negativas.txt -numPos 400 -numNeg 2500 -numStages 15 -w 200 -h 50 -featureType LBP -precalcValBufSize 4048 -precalcIdxBufSize 4048 -numThreads 24
Watch the fact that I increased the memory consumption ... because your system can take more than the standard 1GB per buffer AND I set the number of threads to take advantage from that.
Training starts for me and features are being evaluated. However due to the amount of unique features and the size of the training samples this will take long...
Looking at the memory consumption, this data uses a full blown 8.6GB, so you might want to lower those buffers to ensure that no swapping will happen and that it will cripple the system.
will update once a first stage is succesfully trained, and will increase memory to speed the process up
UPDATE 2
I increased my buffers to 8GB each, since I have 32 GB available using both fully would lead to a max allowed memory usage of 16GB. When looking at memory it halts around 13 GB now, the space needed to represent all the multiscale features calculated for a single training stage....
I am guessing this is one of the main reasons why your program is running extremely slow! I would suggest to reduce the dimensions of your model to like -w 100 -h 25 for a starter, which will reduce the memory footprint drastically. Else it will indeed take ages to train.
Using this memory you can see that weak classifiers and stages are being constructed
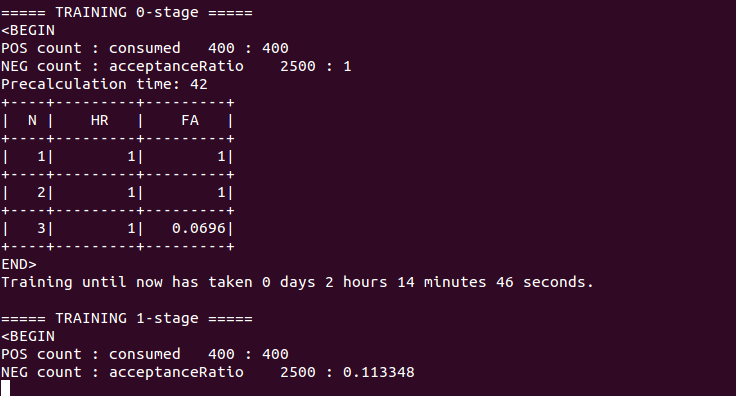
| | 4 | No.4 Revision |
Ok downloading and inspecting your data, I have found already tons of problems
Training_Negativas.txt file, I see the following structure Images/UMD_001.jpg which is asking for trouble. Start by changing those to absolute paths, so that the software reading it will always find the exact image. For example it could be /data/Images/UMD_001.jpg. Relative paths always generate problems...Training.txt, which has the same problem, but somehow you seemed to have trained the *.vec file so it might have been going good.Training.txt is seperated using tabs, while it is stated that data should be seperated by spaces. If you do this with tabs, I am afraid it is already possible that your vec file is actually filled with rubbish.Could you supply the missing 10 images so I can perform tests to see if it works when fixing all this?
UPDATE
After changing the data structure as follows [WILL ADD HERE LATER] I ran the opencv_createsamples tool first with the following result
Then I ran the training command like this
opencv_traincascade -data cascade/ -vec positivas.vec -bg negativas.txt -numPos 400 -numNeg 2500 -numStages 15 -w 200 -h 50 -featureType LBP -precalcValBufSize 4048 -precalcIdxBufSize 4048 -numThreads 24
Watch the fact that I increased the memory consumption ... because your system can take more than the standard 1GB per buffer AND I set the number of threads to take advantage from that.
Training starts for me and features are being evaluated. However due to the amount of unique features and the size of the training samples this will take long...
Looking at the memory consumption, this data uses a full blown 8.6GB, so you might want to lower those buffers to ensure that no swapping will happen and that it will cripple the system.
will update once a first stage is succesfully trained, and will increase memory to speed the process up
UPDATE 2
I increased my buffers to 8GB each, since I have 32 GB available using both fully would lead to a max allowed memory usage of 16GB. When looking at memory it halts around 13 GB now, the space needed to represent all the multiscale features calculated for a single training stage....
I am guessing this is one of the main reasons why your program is running extremely slow! I would suggest to reduce the dimensions of your model to like -w 100 -h 25 for a starter, which will reduce the memory footprint drastically. Else it will indeed take ages to train.
Using this memory you can see that weak classifiers and stages are being constructed
UPDATE 3
Training finished on this 32GB RAM 24 core system in about 1 hour and half. The resulting model has 7 stages until it reaches satisfactory performance given the training parameters. The model and the data structure used by me can be found here.
FInally I used the model to perform a detection output, generated by this command in C++ code
cascade.detectMultiScale( frame_gray, objects, reject_levels, level_weights, 1.1, 1, 0, Size(), Size(), true );
If I then filter out all detections with at least a certainty of 0, then you get the detections stored inside results.txt. The format is filename #detections x1 y1 w1 h1 score1 x2 y2 w2 h2 score2 ... xN yN wN hN scoreN. For now the #detections is still wrong because I postfilter the certainty score. But will update the dropbox file when I fixed this.
Didnt visualise the detections on the training data yet. I will add those too once it works.
| | 5 | No.5 Revision |
Ok downloading and inspecting your data, I have found already tons of problems
Training_Negativas.txt file, I see the following structure Images/UMD_001.jpg which is asking for trouble. Start by changing those to absolute paths, so that the software reading it will always find the exact image. For example it could be /data/Images/UMD_001.jpg. Relative paths always generate problems...Training.txt, which has the same problem, but somehow you seemed to have trained the *.vec file so it might have been going good.Training.txt is seperated using tabs, while it is stated that data should be seperated by spaces. If you do this with tabs, I am afraid it is already possible that your vec file is actually filled with rubbish.Could you supply the missing 10 images so I can perform tests to see if it works when fixing all this?
UPDATE
After changing the data structure as follows [WILL ADD HERE LATER] I ran the opencv_createsamples tool first with the following result
Then I ran the training command like this
opencv_traincascade -data cascade/ -vec positivas.vec -bg negativas.txt -numPos 400 -numNeg 2500 -numStages 15 -w 200 -h 50 -featureType LBP -precalcValBufSize 4048 -precalcIdxBufSize 4048 -numThreads 24
Watch the fact that I increased the memory consumption ... because your system can take more than the standard 1GB per buffer AND I set the number of threads to take advantage from that.
Training starts for me and features are being evaluated. However due to the amount of unique features and the size of the training samples this will take long...
Looking at the memory consumption, this data uses a full blown 8.6GB, so you might want to lower those buffers to ensure that no swapping will happen and that it will cripple the system.
will update once a first stage is succesfully trained, and will increase memory to speed the process up
UPDATE 2
I increased my buffers to 8GB each, since I have 32 GB available using both fully would lead to a max allowed memory usage of 16GB. When looking at memory it halts around 13 GB now, the space needed to represent all the multiscale features calculated for a single training stage....
I am guessing this is one of the main reasons why your program is running extremely slow! I would suggest to reduce the dimensions of your model to like -w 100 -h 25 for a starter, which will reduce the memory footprint drastically. Else it will indeed take ages to train.
Using this memory you can see that weak classifiers and stages are being constructed
UPDATE 3
Training finished on this 32GB RAM 24 core system in about 1 hour and half. The resulting model has 7 stages until it reaches satisfactory performance given the training parameters. The model and the data structure used by me can be found here.
FInally I used the model to perform a detection output, generated by this command in C++ code
cascade.detectMultiScale( frame_gray, objects, reject_levels, level_weights, 1.1, 1, 0, Size(), Size(), true );
If I then filter out all detections with at least a certainty of 0, then you get the detections stored inside results.txt. The format is filename #detections x1 y1 w1 h1 score1 x2 y2 w2 h2 score2 ... xN yN wN hN scoreN. For now the #detections is still wrong because I postfilter the certainty score. But will update the dropbox file when I fixed this.
Didnt visualise the detections on the training data yet. I will add those too once it works.
UPDATE 4
Added visualisations with their score. Basically if you take the best hitting detection per image, you keep the numberplate. Better detectors will require better and more training data.
Good luck with the application!
| | 6 | No.6 Revision |
Ok downloading and inspecting your data, I have found already tons of problems
Training_Negativas.txt file, I see the following structure Images/UMD_001.jpg which is asking for trouble. Start by changing those to absolute paths, so that the software reading it will always find the exact image. For example it could be /data/Images/UMD_001.jpg. Relative paths always generate problems...Training.txt, which has the same problem, but somehow you seemed to have trained the *.vec file so it might have been going good.Training.txt is seperated using tabs, while it is stated that data should be seperated by spaces. If you do this with tabs, I am afraid it is already possible that your vec file is actually filled with rubbish.Could you supply the missing 10 images so I can perform tests to see if it works when fixing all this?
UPDATE
After changing the data structure as follows [WILL ADD HERE LATER] I ran the opencv_createsamples tool first with the following result
Then I ran the training command like this
opencv_traincascade -data cascade/ -vec positivas.vec -bg negativas.txt -numPos 400 -numNeg 2500 -numStages 15 -w 200 -h 50 -featureType LBP -precalcValBufSize 4048 -precalcIdxBufSize 4048 -numThreads 24
Watch the fact that I increased the memory consumption ... because your system can take more than the standard 1GB per buffer AND I set the number of threads to take advantage from that.
Training starts for me and features are being evaluated. However due to the amount of unique features and the size of the training samples this will take long...
Looking at the memory consumption, this data uses a full blown 8.6GB, so you might want to lower those buffers to ensure that no swapping will happen and that it will cripple the system.
will update once a first stage is succesfully trained, and will increase memory to speed the process up
UPDATE 2
I increased my buffers to 8GB each, since I have 32 GB available using both fully would lead to a max allowed memory usage of 16GB. When looking at memory it halts around 13 GB now, the space needed to represent all the multiscale features calculated for a single training stage....
I am guessing this is one of the main reasons why your program is running extremely slow! I would suggest to reduce the dimensions of your model to like -w 100 -h 25 for a starter, which will reduce the memory footprint drastically. Else it will indeed take ages to train.
Using this memory you can see that weak classifiers and stages are being constructed
UPDATE 3
Training finished on this 32GB RAM 24 core system in about 1 hour and half. The resulting model has 7 stages until it reaches satisfactory performance given the training parameters. The model and the data structure used by me can be found here.
FInally I used the model to perform a detection output, generated by this command in C++ code
cascade.detectMultiScale( frame_gray, objects, reject_levels, level_weights, 1.1, 1, 0, Size(), Size(), true );
If I then filter out all detections with at least a certainty of 0, then you get the detections stored inside results.txt. The format is filename #detections x1 y1 w1 h1 score1 x2 y2 w2 h2 score2 ... xN yN wN hN scoreN. For now the #detections is still wrong because I postfilter the certainty score. But will update the dropbox file when I fixed this.
Didnt visualise the detections on the training data yet. I will add those too once it works.
UPDATE 4
Added visualisations with their score. Basically if you take the best hitting detection per image, you keep the numberplate. Better detectors will require better and more training data.
Good luck with the application!
UPDATE 5
Like promised, the best hits collected.
