SVM training much slower in version 3.0.0
Due to some problems with version 2.4.12, I've been testing SVM training with OpenCV 3.0.0, and I've found it is much slower now with the new module.
To share some results, these are the times I got using the same training data and paramters in both versions, and training over 100 iterations to average:
- 1000 samples, 5000 features/sample: 0.11/SVM (2.4.12) vs 0.19/SVM (3.0.0) -> 72% slower
- 5000 samples, 5000 features/sample: 0.50/SVM (2.4.12) vs 0.95/SVM (3.0.0) -> 90% slower
- 5000 samples, 50000 features/sample: 4.9/SVM (2.4.12) vs 9/SVM (3.0.0) -> 83% slower
Not only that, memory consumption is quite higher in new version too. As you can see in the below images, 2.4.12 (fist one) consumes less memory and in a much more stable way than 3.0.0 does (second one).
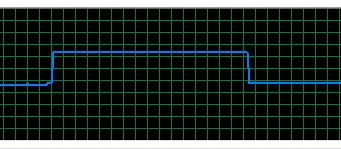
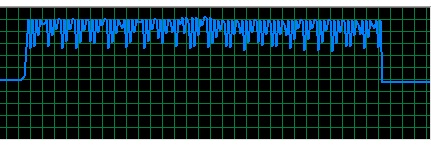
So the question is... was this expected when rewriting the ml module? Is there anything that can be done (by the users and/or the devs) to improve it?

Like said in the other topic, could you try adding
cv::ocl::setUseOpenCL(false);. Even if you do not use UMat some functions do a huge amount of checks at first time run, which yields a giant overload of memory consumption.I had already tried that (I saw the Sobel question too), but in fact disabling ocl leads to worse results: 0.21 vs 0.19 in the case 1 described above, 1.05 vs 0.95 in case 2 and 11.33 vs 9 in case 3
Hmm so it is actually benefiting from the openCL interface ... what other multithread options do you have enabled?
You mean like TBB? I guess none, I'm using a fair simple build and code. Build options are the same in both versions btw.
I am always surprised how powerfull the pthread backend is. On my system that actually works faster than OpenCL and CUDA.
I re-built with TBB support, just to check, and nothing changed. I may consider implementing my own parallel_for loop or even using pthreads, though I don't feel very confident about it (I think I'm not that skilled yet...). Anyway, any insights/comments/suggestions about the performance decrease in the new ml module are welcomed