traincascade : openMP vs Intel's TBB ?

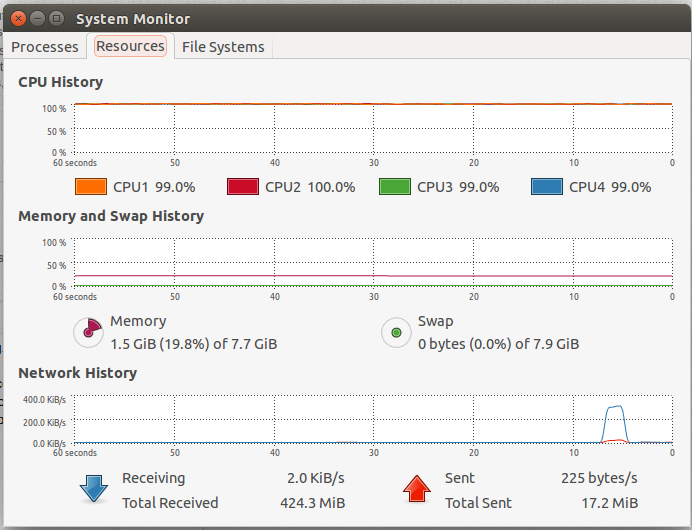
I have an Intel i5 processor with 8gb RAM. Ubuntu 14.04. I am working on cascade training with LBP on openCV 2.4.9. Training takes hell lot of time. After waiting for a week to train cascade, its really painful to see it not working correctly and figuring out that it needs to be trained on more samples.
I tried installing opencv with TBB (thread building block) with no notable advantage in training. What else can I do for making it more time efficient. ?
I found a link https://iamsrijon.wordpress.com/2013/... demonstrating the use of openMP. Is openMP better than TBB ? Any tutorial for reference. Any help would really be very helpul.
add a comment