This forum is disabled, please visit https://forum.opencv.org
| 2013-04-11 05:39:01 -0600 | commented question | DMatch matches output Hi Alicia. So sorry for only replying now, but completely forgot this post. Anyway, custom filters are done by using the keypoint information, such as the angle, (x,y) coordinates and such. One filter we use , for instance, was dividing the image in N parts and comparing only the keypoints inside each part. Again, sorry for the delay in the answer and I hope it was still helpful! :) |
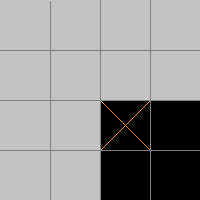
| 2013-04-11 04:50:27 -0600 | asked a question | ORB Keypoint response calculation I've successfully used the For a given image, how can I calculate the response of point marked with orange cross, where each cell represents a pixel and RGB value of grey pixels is (195,195,195)
|
| 2012-10-16 23:39:48 -0600 | received badge | ● Student (source) |
| 2012-10-16 06:44:08 -0600 | received badge | ● Editor (source) |
| 2012-10-16 06:43:20 -0600 | asked a question | DMatch matches output Hey, I'm having some trouble trying to make sense out of the ouput of my matches. I print on screen both the query and train index and their respective distance, then I calculate the min and max distance. My logic tells me that if I'm comparing two different pictures of the same object, the min distance obtained should be smaller than the min distance obtained when matching two pictures of a different object, but that's not the case. Am I reading the output wrong? This is causing a lot of headaches, since I'm currently comparing two pictures and returning a matching rate percentage, but some of these rates are quite wrong. Here's the DMatch output: Query Index: 0; Train Index: 37; Distance: 113.0 How can I use this to determine the good matches? And why do the descriptors in orb return double if it's supposed to be a binary string? Cheers EDIT: So after a few more tests, I've figured that those distances returned can only be the Hamming distance between the two given keypoints in query and train index. I've managed to apply some custom filters for my good matches, and the results are pretty good. If you need help with this, PM me. Cheers |