This forum is disabled, please visit https://forum.opencv.org
| 2018-09-14 13:14:59 -0600 | received badge | ● Notable Question (source) |
| 2017-03-22 03:09:24 -0600 | received badge | ● Popular Question (source) |
| 2016-12-07 08:52:51 -0600 | received badge | ● Famous Question (source) |
| 2016-08-04 04:21:49 -0600 | commented answer | OpenCV3.0 install on Ubuntu 14.04 it does't help me with missing sys/videoio.h trying to install opencv 2.4.13 on Ubuntu 15.04 |
| 2016-08-04 04:21:35 -0600 | commented answer | OpenCV3.0 install on Ubuntu 14.04 it does't help me with missing sys/videoio.h |
| 2016-05-22 15:10:43 -0600 | received badge | ● Nice Answer (source) |
| 2016-03-03 10:45:25 -0600 | received badge | ● Notable Question (source) |
| 2015-11-08 14:01:50 -0600 | received badge | ● Popular Question (source) |
| 2015-10-31 14:32:19 -0600 | marked best answer | how to know grayscale or color img loaded I need to know, is loaded img grayscale or color to not process grayscale. My idea is get grayscale by cvtColor(src,src_gray,COLOR_BGR2GRAY) and compare with loaded img. Perhaps there is a standard or a more interesting variant? |
| 2015-04-26 09:53:25 -0600 | commented answer | how to know grayscale or color img loaded print "1" for all images (color and grayscale). Are you sure that it works? |
| 2015-04-26 09:46:00 -0600 | commented answer | IplImage convertion to Mat Is this the question ? :D Try to use google |
| 2015-04-26 07:22:00 -0600 | answered a question | IplImage convertion to Mat Hi, from IplImage and Mat documentations : If you what pixel access to Mat u can use pointer : ( use uchar type of pointer for type of Mat like CV_8UC1 )
Note that if its a color Mat with 3 channels pixels are saved in data sequentially ( BGRBGR...). or at method : |
| 2015-04-22 09:58:26 -0600 | commented answer | how to remove blobs with SimpleBlobDetector Morphological operations will change shape of tumore area. I think, you can use contours detection and left only contour with area in some range. If range of area is not enough u can use percent of wight pixels in bounding rect or convex hull, ellipticity and other features. |
| 2015-04-13 10:57:53 -0600 | commented answer | How to train a svm? ou, sorry for wrong information |
| 2015-04-13 03:54:50 -0600 | answered a question | How to train a svm? To train svm you need to have Mat with features and Mat with lables ( 0 - happy, 1 - bored, 2 - sad ). But, I think, getting from images features for emotion characterization is too complicated. Read about Cascade Classifier or object detection |
| 2015-04-08 11:32:30 -0600 | commented question | How does LBP work? |
| 2015-03-24 13:33:18 -0600 | commented answer | Real time head segmentation using opencv Yes, I tryed it :) And tryed with opencv face detection. It's realy fast algorithm wich takes only ~ 1ms for pose estamination for detected face ! |
| 2015-03-23 16:47:36 -0600 | answered a question | Real time head segmentation using opencv Hi For fast face pose estamination you can use algoritms based on 68 points . Dlib has implementation of alghoritm that finds 68 points in 1 ms ( if you given ROI of face ) . Dlib have standart face detection too but you can use Opencv detection and Dlib estamination I didn't used Grabcut method so can't say that it's what you are searching :) Plus you can detect face not on each frame because on near for example 5 frames it's pretty same. Maybe you can mach frames and if its too different serch new face pose ...or it's just my fantasy |
| 2015-03-16 04:55:56 -0600 | commented question | HOG training and detection improvement Hi ! I tryed to train HOG and Viola Jones for parts of human bodys, and didn't get very good results. My first try was spleat all objects to big groups like hand, head, leg. But then I understand that HOG can't generalize so differently objects. I broke each group to 2-4 grops witch have objects in same pose and got better results :) I used dlib library, in this lib you can see trained detector like a picture (g) of vectors, maybe it will help you to understand what you have after you trained your classifire. |
| 2015-03-11 09:42:51 -0600 | received badge | ● Critic (source) |
| 2015-03-11 08:00:38 -0600 | commented question | No SURF Feature Detector
Which IDE do you use ? |
| 2015-03-10 18:00:00 -0600 | commented answer | segmentation fault on traincascade hmm, yes, not very informative maybe, if you "try to retry the process" you will get more informative error |
| 2015-03-10 10:12:41 -0600 | commented answer | segmentation fault on traincascade numNeg must be around 300 . If you will have errors with numNeg = 300 then write full error, like you did before :) |
| 2015-03-10 09:22:03 -0600 | answered a question | segmentation fault on traincascade Hi ! In error already writen the answer - " Can not get new positive sample " How you can read in the docs opencv_traincascade arguments numPos and numNeg is number of positive/negative samples used in training for every classifier stage. So if you have 437 positive samples put as numPos argument 437 / numStages. |
| 2015-03-06 06:16:02 -0600 | commented question | install openCV 3.0 beta on windows 7 thanks for your answer, but I'm already builded on ubunta frome source with extra modules :) |
| 2015-02-05 02:21:34 -0600 | received badge | ● Enthusiast |
| 2015-02-03 06:37:28 -0600 | received badge | ● Teacher (source) |
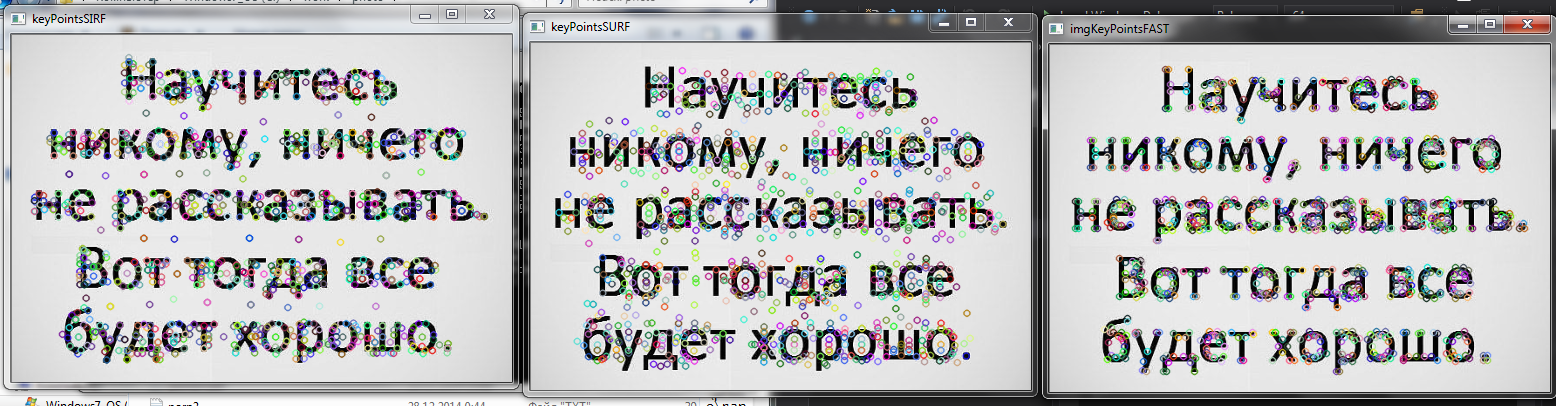
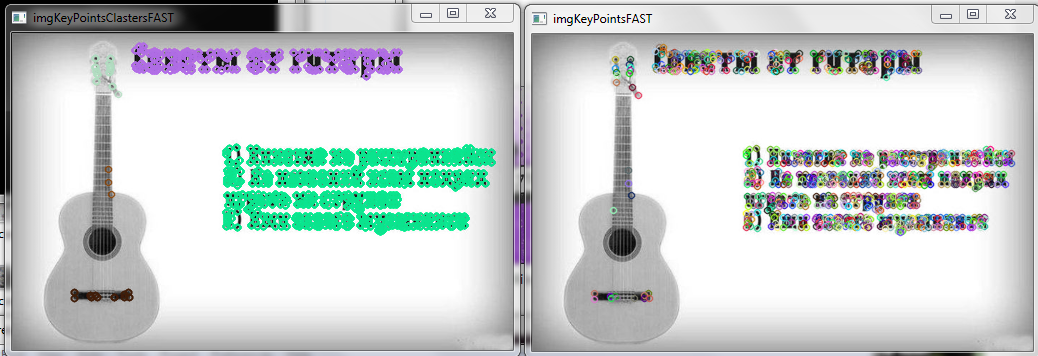
| 2015-02-02 10:32:06 -0600 | answered a question | How to remove text region in a document image? haha, funny, working on this problem now :)) Try to use alghortihms for keypoint detection, I desidet to use FAST, because it's realy faster than SURF and SIFT and, with param that I choosed, working better than them. ( I'm using cv::FAST(img, keyPointsFast, 100, true); )
then you can use clasterization, after clasterization you will have 3 type of classes : words and strings , text and ather objects
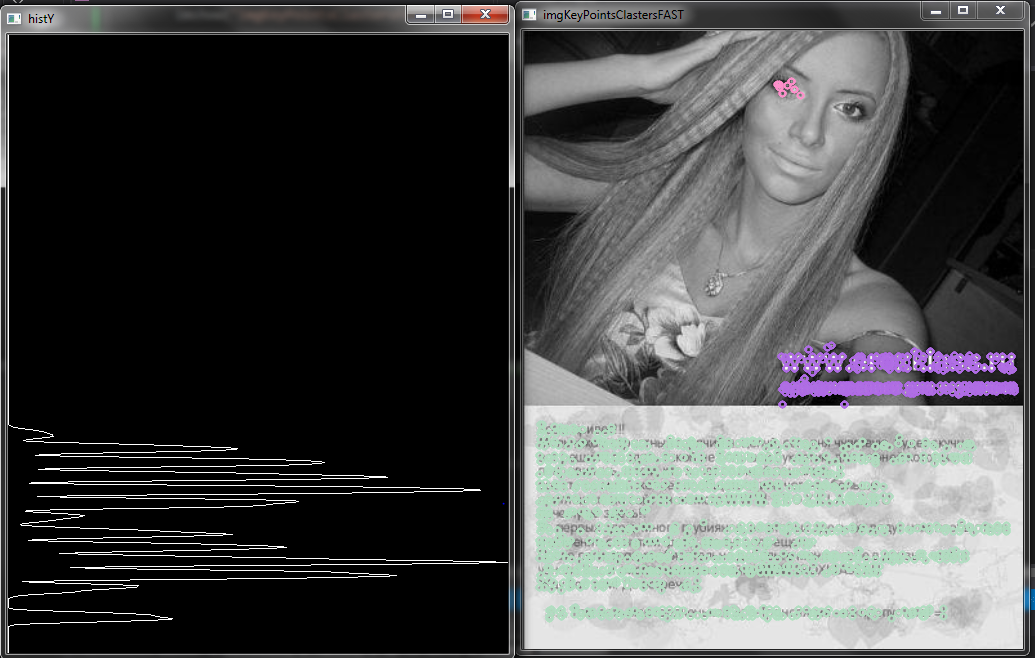
after that you can use differense in dispersion on X and Y for words, and if you make histograms of numPoints in colom you will see that for texts it have pereodic structure
or, if FP not so bad for you, maybe you can try to use sliding window that cheks number of points and if it's greater then threshold than this is the text region :)) hmm, try to do this for your picture, result is not so good :(( maybe, you can try another params
EDITED: haha, ups fogot to convert img to grayscale :) work not so good like on my examples, because photo with peoples have a lot of small details
|
| 2015-01-20 08:12:45 -0600 | commented question | use modules from opencv_extra in visual studio 2013 Will try it, thanks again :) |
| 2015-01-20 08:06:37 -0600 | commented question | use modules from opencv_extra in visual studio 2013 Thanks ! I was writing programs for Linux based system , so it's second reason to went to Linux, but there is no VS ( yes, I'm pervert ) Which compiller did you use in Linux based OS ? Eсlipse ? |
| 2015-01-20 06:00:30 -0600 | asked a question | use modules from opencv_extra in visual studio 2013 This is my firs use of opencv_extra , cant found something about building in vs . Trying to build program with "text" module from opencv_extra. I was downloaded "opencv_contrib" repo and added headers from include in text module to my opencv include folder, but it's only headers and I have errors like " unresolved external symbol "struct cv::Ptr<class cv::text::erfilter="">" so where I can get text.lib ? Or I must do something else for build programs with extra modules ? |
| 2015-01-20 05:42:27 -0600 | commented question | install openCV 3.0 beta on windows 7 my fold, missed step with building program use only standart modules, it's ok trying to build program with not standart "text" module from opencv_contrib/modules/text :) EDITED: text module in cv_extra module |
| 2015-01-19 11:52:02 -0600 | asked a question | install openCV 3.0 beta on windows 7 intstalled opencv 3.0 from exe file , in opencv\build\x64\vc12\lib and same dirs for vc11 and vc10 only world and ts libs . Is it ok ? I think no :) Tell to me that I can try build from source ) |


{kind=link}