This forum is disabled, please visit https://forum.opencv.org
| 2020-10-29 16:56:31 -0600 | received badge | ● Good Answer (source) |
| 2020-09-14 12:48:21 -0600 | received badge | ● Nice Answer (source) |
| 2018-03-27 10:33:45 -0600 | received badge | ● Nice Answer (source) |
| 2018-02-15 08:02:38 -0600 | received badge | ● Good Answer (source) |
| 2018-02-08 04:17:27 -0600 | received badge | ● Good Answer (source) |
| 2017-11-11 15:24:46 -0600 | received badge | ● Nice Answer (source) |
| 2017-10-03 05:05:14 -0600 | received badge | ● Good Answer (source) |
| 2017-09-10 16:45:24 -0600 | received badge | ● Nice Answer (source) |
| 2017-07-12 09:31:10 -0600 | received badge | ● Necromancer (source) |
| 2017-06-26 01:57:04 -0600 | received badge | ● Good Answer (source) |
| 2017-06-26 01:57:01 -0600 | received badge | ● Good Answer (source) |
| 2017-06-20 08:04:39 -0600 | answered a question | annotation tool for object detection If it's related to documents, then Transkribus is quite good: https://transkribus.eu/Transkribus/ |
| 2017-03-20 16:40:35 -0600 | commented answer | What are the suitable datasets for an Offline English handwritten OCR application I think you missunderstand a concept here. It's about images having words, so no real text. |
| 2017-01-20 00:28:23 -0600 | received badge | ● Good Answer (source) |
| 2016-12-27 17:00:21 -0600 | commented answer | MSER operator() is different from FeatureDetector::detect() function? Please read Lowe's SIFT paper for an explanation, another nice explanation is on vlfeat.org, but I guess there are plenty more out there. |
| 2016-11-28 10:18:16 -0600 | received badge | ● Nice Answer (source) |
| 2016-08-15 06:04:04 -0600 | commented question | How to Use OpenCV with Gstreamer in iOS sounds off-topic for me, how ist that related to OpenCV? |
| 2016-08-04 07:06:51 -0600 | answered a question | Scale-rotation-skew invariant template matching I'd just use feature matching in combination w. RANSAC, have a look at the following example: http://docs.opencv.org/2.4/doc/tutorials/features2d/feature_homography/feature_homography.html. Your reference template looks quite small but it should still work out. Try different feature detectors/descriptor combinations. |
| 2016-08-04 06:59:37 -0600 | commented answer | What options are there for Dimensionality Reduction of HoG Descriptors I don't know much about action recognition. Two ideas, where I prefer the last one:
|
| 2016-08-03 14:57:29 -0600 | commented question | Levenberg-Marquardt algorithm function in openCV? A colleague of mine uses the "eigen" library for any optimization and algebra stuff, it should have also LM on bord, afaik opencv has converters from eigen-matrices to opencv-matrices and vice versa. Check it out! |
| 2016-08-03 11:13:48 -0600 | commented answer | how can i get individual coffee_beans from the image below I wouldn't see it so pessimistic, it's like counting cells, I suggest to look into bio-medicine research. |
| 2016-08-03 07:33:01 -0600 | commented answer | What options are there for Dimensionality Reduction of HoG Descriptors Each SIFT descriptor is 128 dimensional. A HOG descriptor is 36 (or 31 depending on the implementation) dimensional descriptor. If you use HOG for fixed-sized images then you actually don't need BoW, since you already have a global descriptor. BoW is meant to generate a global descriptor from many local ones. So, you have to decide now: go the BoW way, then you have to cluster and encode a (N,36) dimensional matrix (where N is the number of HoG descriptors) to get a global descriptor. Or: use the flattened HoG descriptor as your global descriptor which you can use as input for your classifier. |
| 2016-08-03 04:52:03 -0600 | received badge | ● Nice Answer (source) |
| 2016-08-03 03:35:13 -0600 | commented answer | What options are there for Dimensionality Reduction of HoG Descriptors At which step do you run into memory problems? For k-means you only need a selection as already pointed out, when you process each frame individually you may get a lot of descriptors, but they are not very high dimensional. In case of SIFT you might get 2000 SIFT descriptors which are all 128D. Having trained a visual vocabulary with 1000 clusters you end up with a 1000 dimensional BoW-descriptor for this image frame. You train your classifier, e.g. linear SVM with all BoW-descriptors of your training set. So, at testing you only need to evaluate your SVM with the BoW-descriptor, again not very RAM-intensive. So, for which step you need much RAM? |
| 2016-08-02 13:33:19 -0600 | commented answer | What options are there for Dimensionality Reduction of HoG Descriptors For the actual BoW-descriptor you need to take all descriptor samples of your image, but for k-means it is enough if you take a representative selection from all classes. E.g. you want to detect if there is a pizza or not in your video stream, then you need training images with pizza and without, from all these you extract random 100k descriptors which you feed to k-means, then you train k-means with e.g. 1000 clusters. In the actual encoding step you need to take all descriptors from your training image such that you get a good BoW descriptor which you then can use to train a classifier. |
| 2016-08-02 03:44:52 -0600 | answered a question | What options are there for Dimensionality Reduction of HoG Descriptors You can use PCA to reduce the dimensionality of your descriptors. Note that it won't reduce the number of your descriptors. For training k-means: you don't need to feed all your descriptors to k-means for BoW tasks. Typical strategies are the use of around 100k descriptors for k-means randomly taken from 1k representative (i.e. from all classes) images, i.e. you need to take only 100 random samples per selected image. |
| 2016-07-23 06:37:01 -0600 | commented answer | Image Retrieval through fisher vectors: why my implementation works SO BAD? Sure, no problem and yes to your previous comment, I think you got the idea now. Please mark the answer as accepted if it works. |
| 2016-07-22 09:20:14 -0600 | commented answer | Image Retrieval through fisher vectors: why my implementation works SO BAD? ? No, it's totally different. For each image you want one global descriptor from all local descriptors. Currently you are encoding only one single (the first) descriptor of your local descriptors. |
| 2016-07-21 15:09:27 -0600 | commented answer | Can we use Bag of Visual Words to compute similarity between images directly? Cosine distance for l2-normalized descriptors gives the same ranking as Euclidean distance, s. http://stats.stackexchange.com/questions/146221/is-cosine-similarity-identical-to-l2-normalized-euclidean-distance |
| 2016-07-21 15:06:38 -0600 | answered a question | Image Retrieval through fisher vectors: why my implementation works SO BAD? Currently you are encoding only 1 descriptor, change |
| 2016-07-21 08:46:06 -0600 | commented answer | Can we use Bag of Visual Words to compute similarity between images directly?
where idx is a vector containing the indices from each descriptor to nearest k-means center. After that you only need to reshape and normalize the vlad descriptor. |
| 2016-07-21 08:40:54 -0600 | commented answer | Can we use Bag of Visual Words to compute similarity between images directly? Since VLAD/Fisher vectors are typically already l2 normalized a Cosine distance is sufficient.
|
| 2016-07-20 16:24:53 -0600 | commented answer | Can we use Bag of Visual Words to compute similarity between images directly? Sidenotes: a) if you want to get better results: use activation features extracted from a CNN. b) There are experiments were just averaging these activation features gives a good global descriptor c) try other encoding methods, e.g. VLAD is very simple and effective (I really should finally do a pull request for OpenCV...) |
| 2016-07-20 16:15:15 -0600 | commented question | Bag of Features: why the distance between two histograms of the same image is different than 0? ... then the histogram would change since possible other nearest cluster center (=visual word) would have been choosen for some descriptors. As flann has also in its name, it only gives you the approximate nearest neighbor. |
| 2016-07-11 13:57:42 -0600 | received badge | ● Good Answer (source) |
| 2016-07-03 08:12:50 -0600 | answered a question | tesseract/opencv invert color conditionally?
|
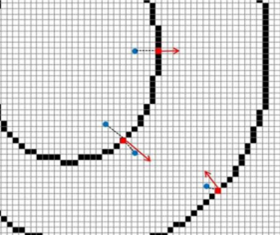
| 2016-07-03 07:56:01 -0600 | answered a question | How can I detect center of road(as a line) if contours for road are drawn. If you have the road lines correctly detected and just want the middle line, then you can do like the famous stroke width transform (SWT). Basically from each point on the line walk in the direction of the gradient until you hit the gradient from the other line (which points (roughly) in the opposite direction). When you have have found the end point of your line, then you can just take the midpoint of it. Do this for each point and you got the line in between of the other two lines.
|
| 2016-07-02 12:01:48 -0600 | commented question | How can I detect center of road(as a line) if contours for road are drawn. So, you have the border lines and want to compute from them the center line? Or do you currently have nothing and want to detect all the road lines? |
| 2016-06-08 16:11:36 -0600 | commented answer | K-Nearest Neighbors, SURF and classifying images. you can get the distances by the |
| 2016-05-26 05:05:47 -0600 | received badge | ● Great Answer (source) |
| 2016-05-26 05:05:47 -0600 | received badge | ● Guru (source) |
| 2016-05-26 04:59:29 -0600 | received badge | ● Nice Answer (source) |
| 2016-05-21 12:02:26 -0600 | received badge | ● Nice Answer (source) |
| 2016-05-17 11:05:48 -0600 | commented question | How many images for good face recognition This is a classical pattern recognition dilemma, nowadays with deep learning techniques the mass is typically more important - the more the better. If you don't have so much data then other methods might work as well (or even better). |
| 2016-04-15 06:50:28 -0600 | received badge | ● Nice Answer (source) |
| 2016-03-30 04:29:49 -0600 | received badge | ● Nice Answer (source) |