This forum is disabled, please visit https://forum.opencv.org
| 2015-03-13 08:18:55 -0600 | received badge | ● Scholar (source) |
| 2015-01-20 06:13:24 -0600 | commented question | [ATTENTION] Regarding topics and answers not appearing right away, but requesting moderation OK, no problem then! I know you have done a lot for this QA forum, thanks! |
| 2015-01-20 03:56:24 -0600 | commented question | [ATTENTION] Regarding topics and answers not appearing right away, but requesting moderation Same as @kbarni: if our answers are stuck in the moderation queue, we lose motivation... |
| 2015-01-20 03:50:46 -0600 | answered a question | How to specify modules with CMake? You can also use ccmake (if you are a linux user) which will help you to select the feature you want (or not)... There is also a beautiful graphic interface (cmake-gui), depending the version you have installed... |
| 2014-12-02 13:43:22 -0600 | answered a question | Limiting the no. of keypoints detected by detector created by FeatureDetector Hi! In 2.4.9, you can still use the But in Opencv3, you will have to use the parameters of the BRISK class... |
| 2014-12-01 13:22:19 -0600 | received badge | ● Great Question (source) |
| 2014-12-01 03:59:34 -0600 | received badge | ● Nice Answer (source) |
| 2014-11-30 14:34:19 -0600 | answered a question | how blury the background apart from ROI Hi! This can be done using additions (easy to code, but not very efficient...): |
| 2014-11-30 06:44:07 -0600 | edited question | Opencv3 and Algorithm (create, getList, etc.) Hi, I just moved my project from 2.4.9 to 3.0.0alpha and I noticed that most of feature2d algorithms don't use the macro the CV_INIT_ALGORITHM which allows us to use: My project highly relies on such feature (and also on get/set parameter, list algos and parameters...), so my question is : will this feature included in OpenCV3 or Algorithm is going to be a dead-end ? |
| 2014-11-25 08:45:09 -0600 | asked a question | Vision challenge: tracking and Pedestrian Detection Hi! I'm a bit confused with the OpenCV Vision Challenge: on the main page, they give the list of categories covered by the challenge, and you can find the "tracking" category. In PDF, you also have a link to the database, but nothing in the dataset page... Is this topic still covered by the challenge? There is also a new category, named "Pedestrian Detection", but the footnote seems to state that this dataset is not used in the challenge??? Can someone (Dmitry Anisimov?) gives us some details? Thanks in advances! |
| 2014-11-23 12:46:44 -0600 | commented question | Videowriter and capturing - memory leak ? Hi, please post here your code, from webcam opening to video writing. I don't have such problem here... |
| 2014-11-23 12:43:29 -0600 | answered a question | How to get SURF to work in these scenarios? Indeed, SURF is not affine-invariant. It means that non-uniform scaling (as well as perspective transformations) produces too much perturbations, and the SURF features vectors will be very distant. Unfortunately, there is not yet a good algorithm which can deals with such transformation... So you will have to find an other way to match your images :-( For the bounding-box problem, you have to draw a rotated bounding box using points of each corners, and lines... |
| 2014-11-23 12:32:25 -0600 | answered a question | OpenCV ref count: function returning cv::Mat? Hi! This should not be a problem... Please add: That way, you are sure the matrix type is OK... You should also use direct access to speedup a little the iterations:
|
| 2014-11-23 12:10:19 -0600 | answered a question | Simple matrix operation not working : is it normal ? Hi! there is probably something wrong with your code, because this works for me... Can you post the code you use? |
| 2014-11-22 09:38:16 -0600 | answered a question | A way to ensure Canny runs in serial? Hi, Indeed, you have to make sure you build OpenCV without TEGRA_OPTIMIZATION or IPP (you have to install such library so by default, this is not enabled). Then, you have to disable opencl using After a brief investigation of the source code (2.4.9), it seems Canny (as well as Sobel) was not optimized using TTB... It should then run using only one processor. Please tell us if it's not the case! |
| 2014-11-22 09:23:39 -0600 | answered a question | How to extract data from edge detection of a video Hi! I thing the best way to do this is to compare the mean edge response of the original video with the blurred one., You can do it like this: Then using totalSum, you know if the second video is blurred or not (if totalSum < 0, the test video is blurred...) |
| 2014-11-20 16:41:46 -0600 | commented question | How to extract data from edge detection of a video HI! Please precise your problem: if you want to see if someone blur a video, I would do differently than using Canny. So do you really need a binary edge map (canny) comparison or not? |
| 2014-11-20 07:18:51 -0600 | answered a question | How is OpenCVConfig.cmake detectable by cmake on windows This behavior depends on the operating system. I assume you are on windows, the path is found thanks to cmake-gui: according to documentation (section 5.), find_package will search for project in build trees recently configured in a cmake-gui. But you can deactivate this behavior using "NO_CMAKE_BUILDS_PATH" constant in your CmakeLists.txt file... |
| 2014-11-20 06:57:15 -0600 | commented answer | Coordinate System Transform An homography is like an affine transformation, but allows perspective deformations... If you just want to correct the motion of camera, you can follow the tutorial I posted before... Instead of matching points from one object image to "live" image, you will match points from first image of your sequence to current image. Then, using the homography computed by findHomography, you will be able to correct the transformation using warpPerspective. Depending the way you match your points, you will probably need to invert the transformation (or use the WARP_INVERSE_MAP flag). |
| 2014-11-19 18:35:24 -0600 | answered a question | Coordinate System Transform Hi! I am assuming that your object is flat because otherwise you can't find an homography transformation (rotation, scale, translation) which put the object back in the same position : the perspective will change the object 2D projection (for example, one face of the object can be hidden)... If your object is flat, this tutorial will probably help you! If not, please ask for details! |
| 2014-11-19 18:23:22 -0600 | answered a question | OpenCV Function Not in Docs... Need Help! Hi! opencv_createsamples and opencv_traincascade are not opencv function... They are executable you have to build (using CMake rule BUILD_opencv_apps). The source code can be found in /apps/traincascade and /apps/haartraining of the opencv repository... Then you can use this tutorial to understand how to use the programs! Good luck ;) |
| 2014-11-14 03:01:59 -0600 | received badge | ● Nice Answer (source) |
| 2014-11-11 13:46:59 -0600 | received badge | ● Self-Learner (source) |
| 2014-11-05 09:54:01 -0600 | answered a question | Opencv3 and Algorithm (create, getList, etc.) A small bump as this is not yet answered... Maybe someone know how to list every feature2d algorithms the user has access to (at run-time of course), without Algorithm::getList()? |
| 2014-11-05 09:35:49 -0600 | answered a question | how to pass command line argument to excute this code in visual studio 2013 I'm not sure I understand your question, but if you want to know how to pass command line argument in Visual studio 2013, watch this video! |
| 2014-11-04 11:20:16 -0600 | commented answer | Guarantee continuous Mat Image Please mark it as solved ;-) |
| 2014-11-03 15:48:50 -0600 | commented answer | Guarantee continuous Mat Image Hi, your code is correct, you just made small mistakes: you forgot the "u" in isContinuous, and the function clone() should have parenthesis : |
| 2014-10-31 07:58:35 -0600 | commented question | how to calibrate camera (stereo) I'm sorry, but I have the same problem as you (black rectified images...). How do you acquire your images? Are you sure the relative position of the two camera doesn't change (it's very important as you are working with very small pattern)? You didn't process your images after that (rescale, rotation...)? As I don't have any clue, I edited your question with the information you gave, maybe someone with more experience will give it a try ;-) |
| 2014-10-31 07:30:57 -0600 | edited question | how to calibrate camera (stereo) Hi i am trying to calibrate two cameras which are looking at a mini object through a microscope. The calibration target is a circle grid. I have to mark these images appropriately in order to find the circles (images with markers) markers data : (points only; format is objectX,objectY,objectZ,img1X,img1Y,img2X,img2Y per line) if you want you can load these points as the input for stereocalib. My program is very similar to the one from opencv example. I tried both :
I still have black images as rectification output. From what I read the calibration should be done by moving the calibration target around, so that it fulfill some criteria:
But due to space and lighting limitation I can only move up and down using the calibration target. It is impossible to do the (stereo) calibration like this? Since I got only black images after using stereo rectify. Thank you |
| 2014-10-30 13:42:09 -0600 | answered a question | Cannot detect yellow balls using OpenCV It's very strange because your binary image is very good! Try with the two last parameters: If it's not working, try to analyse |
| 2014-10-30 13:31:15 -0600 | answered a question | getting area points inside contour You can get the pixels inside the shape using drawcontours: you will create a black image of the same size of your image, then draw the shape on it (be careful to use You can also use pointpolygontest to test points, but the performances are probably worse than the previous version... |
| 2014-10-30 13:22:28 -0600 | commented question | how to calibrate camera (stereo) Yes it is possible. Your problem is probably elsewhere. Can you show us your code and the calibration pattern you use? |
| 2014-10-30 05:37:26 -0600 | answered a question | Capturing Video - OpenCV Hi! Do you do any particular treatment on your video? Can you post your code? |
| 2014-10-30 05:34:50 -0600 | answered a question | Guarantee continuous Mat Image Hi! Are you sure your images are not continuous (img.isContinuous())? If they aren't, the solution you post seems correct, it's working for me. Can you give use more details on your code and error? |
| 2014-10-30 05:08:35 -0600 | answered a question | Interfaces std::Vector to cv::Mat Hi!
So here is a snippet of how to do this with classical types: |
| 2014-10-29 16:14:10 -0600 | answered a question | image processing to improve tesseract OCR accuracy Hi! Without seeing your images, it's quite difficult to know which specific problem your images have. But I suggest you to resize images if they are too small, convert them to grayscale and normalize them. You can also try to deblur (sharpen) your images using for instance Wiener filter. Unfortunately, there is no such function in opencv, so you will have to do it yourself. For instance, here is a small code which will sharpen your image: |
| 2014-10-29 15:57:37 -0600 | answered a question | Categorizing lines on a shirt Hi!
Your first guess is I think the best way to handle this problem. The fact that a line is broken into multiple lines is not a problem : just take the orientation of each line (in degree for example), put them into a vector and try to count vertical lines ( If you want to be more robust, you can try to cluster this vector using K-Means, for instance. Using 2 or 3 class, and analyzing variances of each class, you can have some guess about the type of the shirt (horizontal/vertical ; both ; neither). Then the problem is easier: you have to choose between vertical or horizontal shirt... |
| 2014-10-28 16:17:21 -0600 | commented answer | Circular Region of Interest before thresholding The problem with such methods is the window size: taking a too small window will lead on a binary edge map (the interior of the circular object will be white), and taking a too big window will lead to the same problem than Otsu's method... |
| 2014-10-27 17:19:24 -0600 | answered a question | Multi object tracking with Haar cascade detection I suppose you are working on a video with high temporal resolution (at least 10 images / seconds). Indeed, below this, you will have a lot of problems to track your objects. The solution you can implement depends also on the processing time you can spend to track objects. If you need a close-to-realtime solution, I suggest using sparse Lukas-Kanade tracking algorithm. You will first take point in the center of each objects detected by your classifier, then use calcopticalflowpyrlk to track those points along the sequence. If you can spend more CPU, you can use dense optical-flow algorithm which are more robust. You will then have to compute the mean translation of the flow field inside the bounding box of each objects to have the movement of your object. |
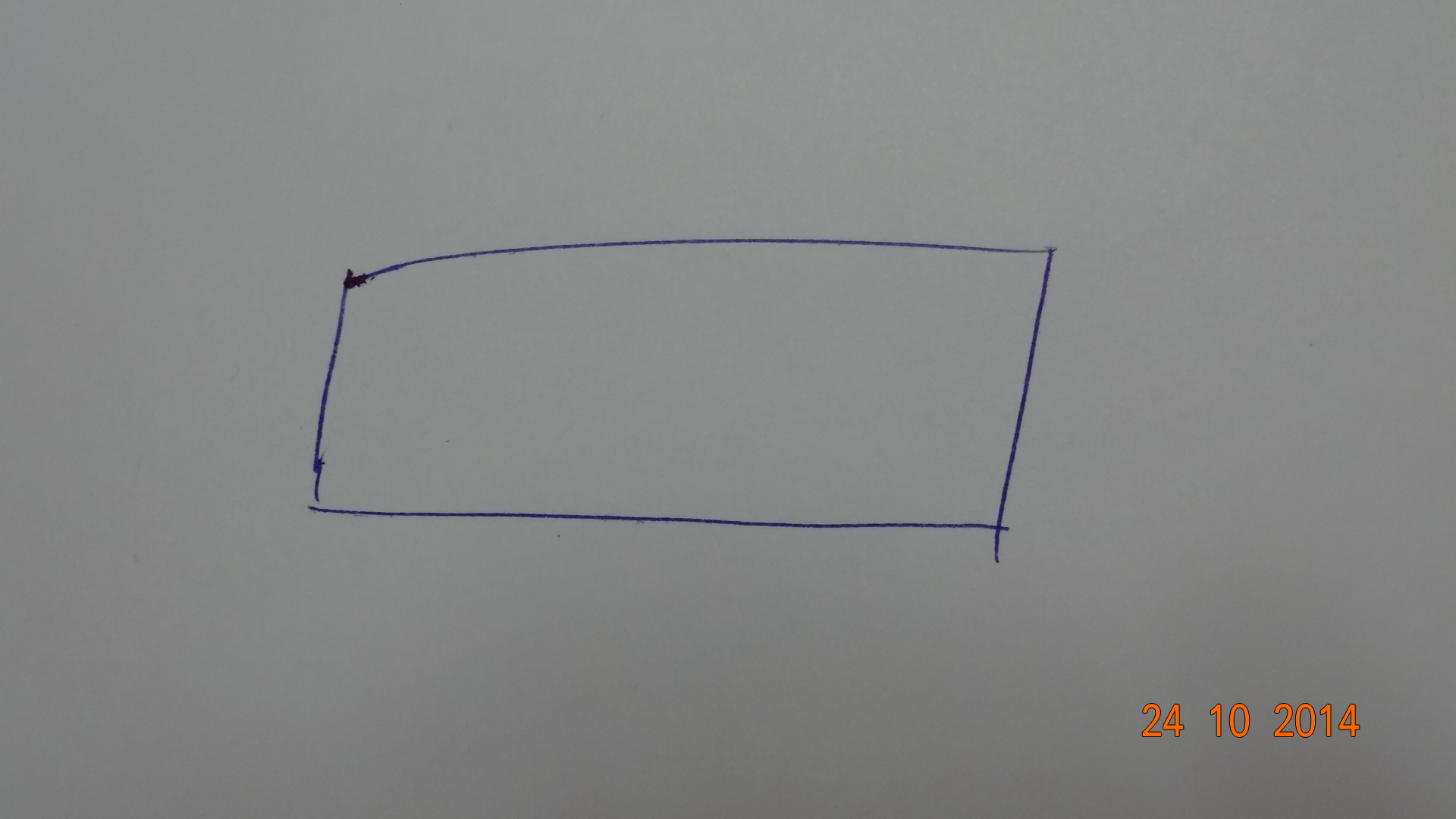
| 2014-10-27 16:57:45 -0600 | edited question | How to find angle of corners detected? i want to find angles between the corners detected from a sketched rectangle, i have used harris corner detection and canny edge detection and also have drawn circles around the corners , can i used all of these together to find angles of each corner? I want to find angles from this image for rectangle classification.
I have so far done this:
Here is a snippet of code (I have saved the vertices of the drawn circle and want to use it with detected edges from canny): |
| 2014-10-27 16:52:00 -0600 | answered a question | Circular Region of Interest before thresholding Hi! This problem is classical with global-threshold methods (like Otsu). It's a very difficult task, and to my knowledge, there is no general method to handle this case. During my thesis, I developed an algorithm for binarization which was focused on text but you can try with your images here : demoFAIR. As your images have a big amount of blur, I suggest you to use a very low value for K (for instance 0.07), or if you can try with images before you blurred them, it will probably have better results. Of course, I would be happy to give you more details if you think this method worth a try! |
| 2014-10-27 05:33:20 -0600 | received badge | ● Critic (source) |
| 2014-10-27 05:04:50 -0600 | answered a question | How to tag persons in an image in OpenCV? Hi, I would decompose the problem in two steps : create a learning database of the person you want to tag, and the recognition step. For the first step, you will first have to create a database containing multiple view of the face of each person you want to recognize. That database will consist of a list of pictures with the corresponding name. So to sum up: In this example, you have 3 persons, with some pictures of them. labels correspond to the index in the names vector. You can then use a classifier (I suggest you the LBP face detector): Now model contains everything you need to tag peoples. To get the class, you just have to do that: |