Hello,
Is it possible to reverse engineer an image feature?
Given a feature2D detection/description method (SIFT, SURF, FREAK, AKAZE etc) is it possible to create image features that are likely to be detected in an image? I want to create an alphabet of features. I don't think BOW is quite right here, but the usage of a vocabulary may be necessary.
Let's say we have 10 images, and we want to add a sticker with one of our features on it. We can print out these images onto giant pieces of cardboard and move them in front of the camera.
When shown to a camera, the feature detector/descriptor/matcher will be able to tell which image is current in view of the camera, despite it's scale/translation/rotation very quickly.

I know QR codes are probably better for the scenario i am describing, however, QR codes are not viable. I just want one giant image feature that can be easily matched.
Is there such a method to know all possible features for a detector/descriptor/matcher ahead of time? And in particular, the ones that will match well.
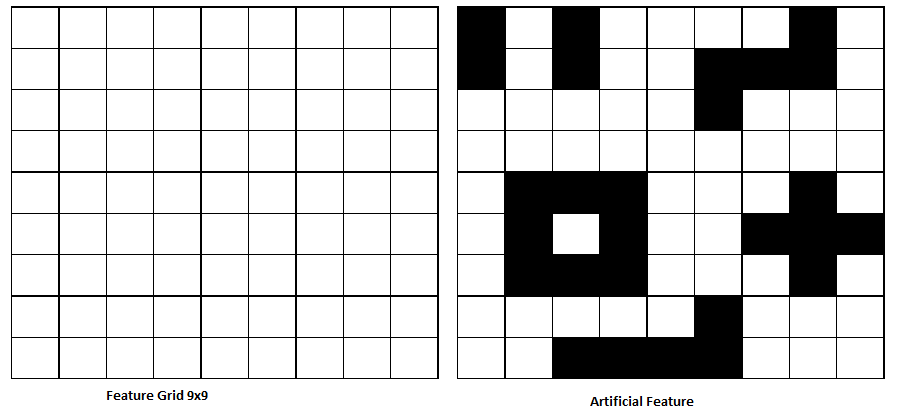
i.e. SURF is a 9x9 patch, so possibly create a large image say 900 x 900, then according to a 10x10 grid on this surface, we could colour squares making a detectable feature.
Please ask for clarification on any points here......