Hello gaurav_kl!
I've done the same project too. I assume you've already cleaned up the noise in your image. Here are basically the ideas that I used to implement it.
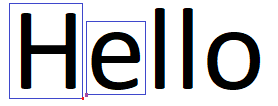
1.) Get the bounding boxes of each letter in your image.
2.) Get the distance between the x-value points of these bounding boxes and store it to an array(let's call it "differences"). On the example image above, the red dot is the x+w value of boundingbox1 while the purple dot is the x value of boundingbox2. You get the difference between the two said values and that's your distance.
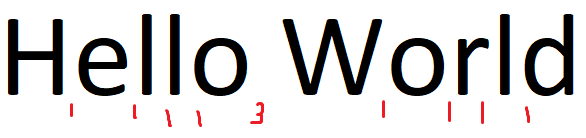
3.) Find out how would you define a space between two letters as a space indeed. This was the tricky part, I hope I can explain it well to you. Given the second image above with two words: Hello World. The numbers between each letter is an example distance value between them. In order to find out if it's really a space, I used a sliding window technique. Basically, it will get the average of the first three values of your "differences" array and checks if the fourth value is greater. If it is, the distance between the third letter and fourth letter is considered as an actual space. If it's lesser, it moves on by taking the average of the 2nd,3rd,4th values and comparing it to the 5th. The same pattern goes on.
In checking the next lines of the document, here's the reference that I used.
I hope that helps.
Hi are you using handwritten text or a fixed typed font?
the text is typed font but it is something like from 19th century .I just need to segment out the sub-images with extra spaces around them.