Haartraining and Traincascade crashes creating XML.
Hi everyone, I'm trying to generate XML with haartraining or taincascade based on generated .vec file, which is created by following command:
bin\opencv_createsamples.exe -info positive\info.txt -vec positive\muestra.vec -num 10 -w 90 -h 140
I think it's well generated: no errors, and file weight is about 30mb (when specify -num 900, -num 10 weights about 250kb).
I've tried to train using:
bin\opencv_haartraining.exe -data cascada -vec positive\muestra.vec -bg negative\infofile.txt -npos 10 -nneg 10 -w 90 -h 140 -mem 1024 -nonsym
and
bin\opencv_traincascade.exe -data cascada -vec positive\muestra.vec -bg negative\infofile.txt -numPos 10 -numNeg 10 -w 90 -h 140 -mem 1024
In both cases, the app crashes, telling me it can't allocate memory. Using Haartaining it get stuck here:
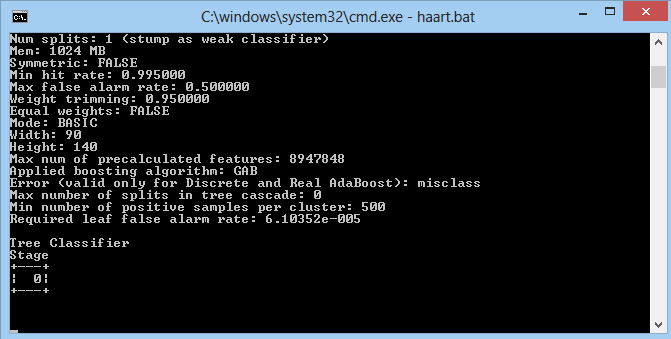
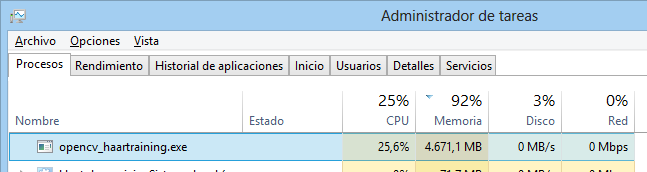
Watching at the system monitor, we can see it consumes about 5Gb of 6 available on system (4.7 on this particular screenshot), even with only 10 positive and 10 negative images. (This low number of images is an attempt to resolve the memory problem, the original files are about 900 positives and 1000 negatives, 92x144 sized with BMP extesion).
Using Traincascade, simply don't show anything until it crashes. Only popup new Windows message "traincascade stop working, searching for solution..." after one minute.
I've tried with multiple -mem values in both haar and traincascade (between 512 and 5000), and three different OS in different PCs: Windows 8, Windows 7 and Debian, all x64. Also tried with three different versions of OpenCV.
Example of Positive list. Paths are OK.
rawdata/image105.bmp 1 22 26 40 68
rawdata/image106.bmp 1 21 27 42 72
rawdata/image107.bmp 2 19 26 43 69 20 29 42 67
Also tried adding and removing lots of parameters, image sizes, paths... nothing works. Every attempt finish with "unable to allocate memory", "insufficient memory" or simply crash.
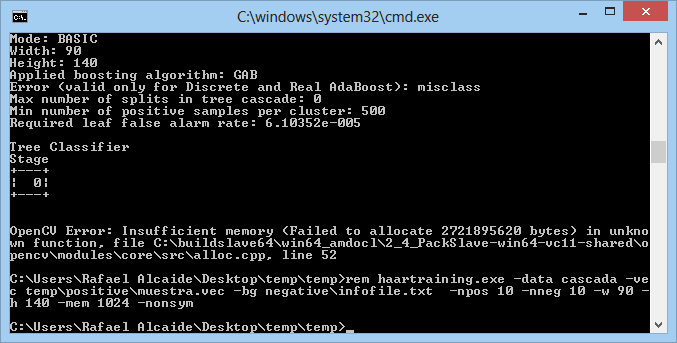
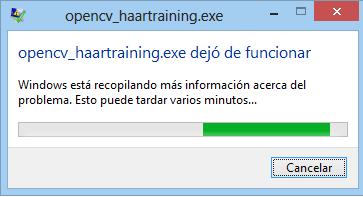
The fact that it happens in three different PCs, OSs and OpenCV versions makes me think there's a problem with .vec, createsamples or some step before training.
Tree directory is:

.bat or .sh files to run previous commands are placed in the root of that tree.
