Human joint estimation

Hi all, I have used superpixel and SVM to classify the human body parts.link text Find the attached images. 1st image represents the output from SVM and another image contains the joint points.I want to fit upper body more accurately. I am searching good technique for elbow joint and shoulder joint. I have few questions.
1) Is it possible to apply CNN(without graphics card) only on upper body part as there are not much variations in lower body parts. or it will be great, if anyone suggest me another approach.
2) Currently, I am using the HOG for the co-ordinate system of SVM. Is there any alternative for the HOG'?
Thanks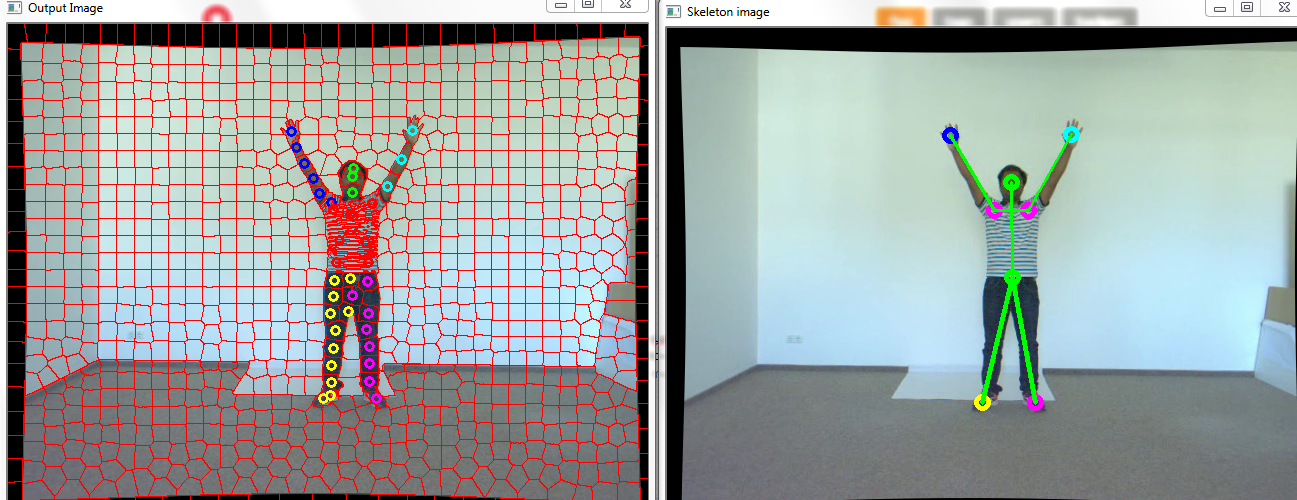
using latest opencv (3.4.1) , you could try with the pretrained openpose dnn
(it works on the whole body, but will happily ignore any parts it does not see)
Hi Berak, Thanks for your response but I want to create my own module. As you see in the above image, I am able to find the hand tip points and head point from the output of the SVM. Just I am finding the way to find out the elbow joint and shoulder joint.
" I want to create my own module" -- that's great !
curious here: how do you derive the skeleton from the superpixels ?
As per your suggestion :) link text I have created data set of 100 images for 6 classes(hands, legs , torso and head). After training the SVM , I am almost getting the correct results for 6 body parts.
ahh, so each superpixel gets a prediction for a body part. for ellbows/hands you would just more classes then ? (and ofc. appropriate train data)
I am afraid that your solution will only work in these
lab conditionshaving a white clear background. Have you tried if this works in cluttered backgrounds?@berak..I have created the label tool for all 14 joints. currently, I have converted 14 classes to 6 class. I will try for 14 classes. Just I am courious, is there any way to operate on upper body to get the shoulder joint and elbow joint.
@StevenPuttemans ..you are right, As I don't have sharp depth data. So, I have to provide the difference of background frame and current frame to the SVM. The advantage is , I don't have to provide threshold value or morphological operation data to SVM.