Perspective transformation without camera intrinsic/extrinsic matrix?
I'm a bit confused in whether something can be accomplished or not.
Supposing I have 2 identical delimiting shapes:
Rectangle, 5 units height, 50 units width.
Which I position on a uniform plane parallel to each other so that they form a rectangle between them. Can I obtain the perspective transformation needed to go from what a video camera sees (perspective view) to a 2D representation of it?
Based on this link: (http://docs.opencv.org/3.0-beta/doc/p...)
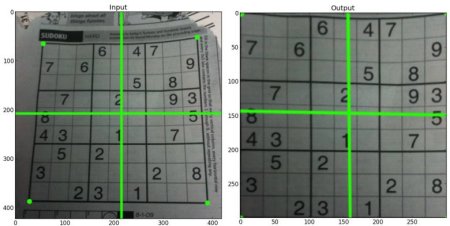
I need to specify 4 points for the input, and another 4 points for the output.
The input 4 points are known, since I can detect the top left/right corners of my top marker, and the bottom left/right corners of my bottom marker.
The problem lies in the 4 points required for the output. I know what the width of the final image should be (which is equal to my marker width) but i don't know what the height should be (as the markers CAN be positioned with a variable distance between each other).
Is there a way to calculate this distance somehow? (I somehow believe there must be an alternative to using the intrinsic/extrinsic matrices since I know before hand the dimensions of both of my markers.)

Just to be clear:
- Both of the markers are exactly the same. (although the arrows point to the middle)
- Distance between them is VARIABLE, but they will always appear parallel to each other forming a VARIABLE height rectangle, with a static width (the marker's width)
unclear question. maybe addiing an image would help ?
Would love to, but I don't have enough karma for it, actually, i'll just upload it somewhere else and paste the URL. Even though i can't show normal links either, lol.
i added some. (sorry, should have done so before)
@berak thanks alot. I added an image and some clarification points below.
"but i don't know what the height should be" -- do you want to preserve the aspect ratio of your rectangle ?
(then the height could be inferred from the target width)
@berak Yeah, but the distance between both markers (which defines the height of the yellow area) is also unknown. As sometimes the markers might appear further away from each other. (The goal of this is to create a variable-height area for processing stuff inside it.) Or do you mean the rectangle as in the black markers?
btw, no, you do not need to calibrate your camera or use intrinsic calibration information (camera matrix, distortion coeffs) for this task.
Aaaaaa, would you be some kind as to give me some pointers on how to achieve it?
What I would do is infer the largest dimension in either X or Y between the corner points. Than transform to a largest x largest dimension. This because simply said, a sudoku is always squared, an inherent property of it.
Sorry, I think i wasn't clear enough. The sudoku image is just an example of the perspective transform to show how it requires 4 points. The actual image I want to transform has only a known width but the height is completely variable (it could be smaller or bigger than the width depending on how far from each other the top and bottom markers are placed).