This forum is disabled, please visit https://forum.opencv.org
| | 1 | initial version |
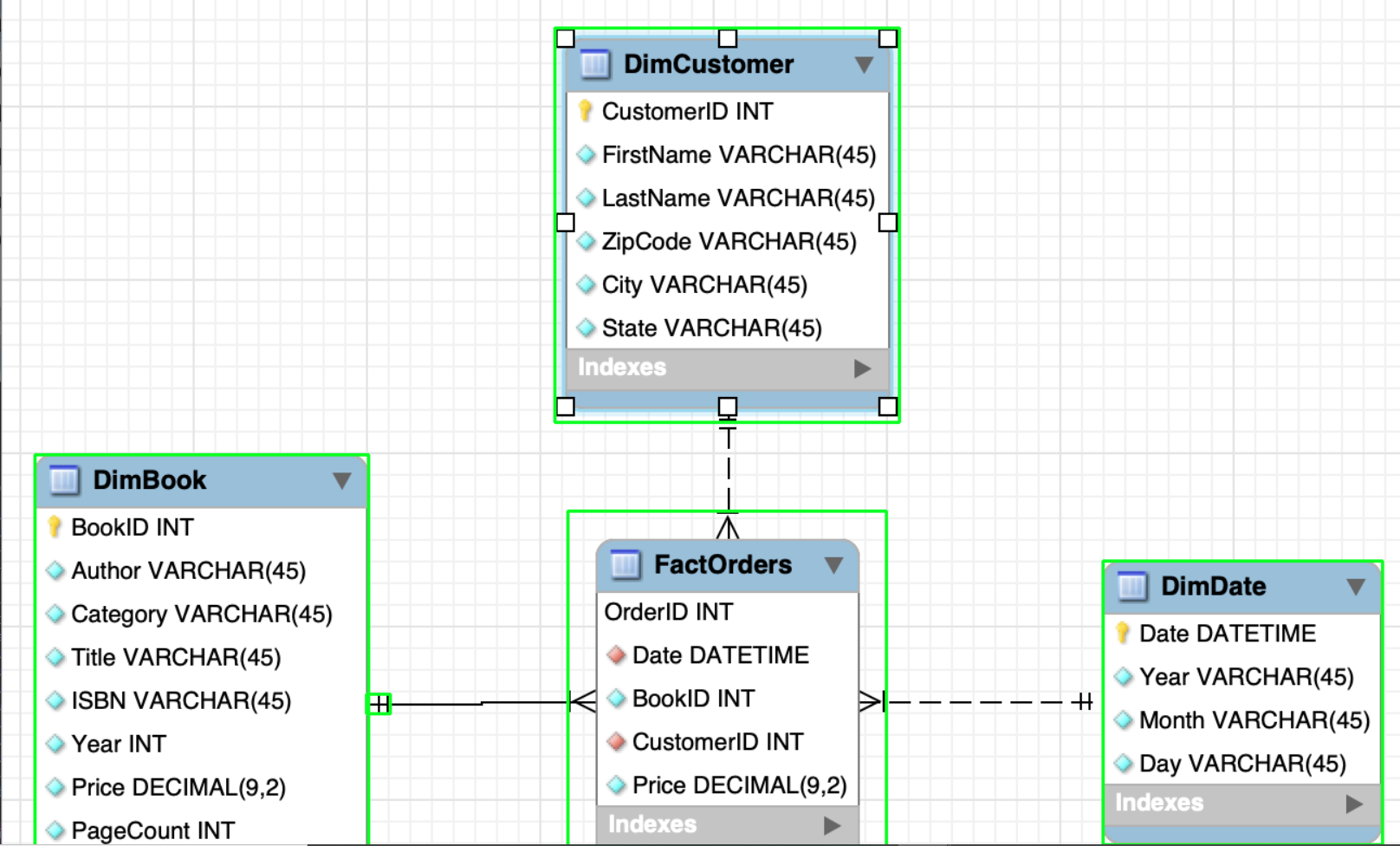
this is the full code. you can see i need to crop each rectangle but also i need to extract the text from each rectangle.
import cv2
import re
import os
import pytesseract
from PIL import Image
# obtengo la direccion donde se encuentra los recortes
lista = os.listdir('C:/Users/Usuario/Documents/Deteccion de Objetos/recortes')
# busco la ultima carpeta creada de los recortes
ultimo = lista.pop()
convertido = int(ultimo)
path = 'C:/Users/Usuario/Documents/Deteccion de Objetos/recortes/' + ultimo
# miro y busco la imagen que necesito para examinar
image = cv2.imread(
"C:/Users/Usuario/Documents/Deteccion de Objetos/imagenes/Nuevacarpeta/ejemplo4.png")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5, 5), 0)
thresh = cv2.threshold(
blur, 127, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
# Remove dotted lines
cnts = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
for c in cnts:
area = cv2.contourArea(c)
if area < 5000:
cv2.drawContours(thresh, [c], -1, (0, 0, 0), -1)
# Fill contours
close_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
morph = 255 - cv2.morphologyEx(thresh, cv2.MORPH_CLOSE,
close_kernel, iterations=6)
cnts = cv2.findContours(morph, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
for c in cnts:
area = cv2.contourArea(c)
if area < 15000:
cv2.drawContours(morph, [c], -1, (0, 0, 0), -1)
# Smooth contours
close = 255 - morph
open_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (20, 20))
opening = cv2.morphologyEx(close, cv2.MORPH_OPEN, close_kernel, iterations=3)
# Busca los contornos y dibuja los resultados
ROI_number = 0
cnts = cv2.findContours(opening, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
for c in cnts:
#cv2.drawContours(image, [c], -1, (36, 255, 12), 3)
# aqui se realiza el recorte de cada entidad
x, y, w, h = cv2.boundingRect(c)
ROI = image[y:y+h, x:x+w]
cv2.imwrite(os.path.join(path, 'imagen_{}.png'.format(ROI_number)), ROI)
cv2.rectangle(image, (x, y), (x+w, y+h), (36, 255, 12), 2)
ROI_number += 1
# formo una lista con las imagenes de la ultima carpeta creada
listadeimagenes = os.listdir(path)
print(listadeimagenes)
# aqui realizo el reconociemiento de texto dentro de cada entidad
for imagenes in listadeimagenes:
preprocess = "thresh"
img = cv2.imread(path + "/" + imagenes)
cv2.imshow('imagen de la ruta', img)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
if (preprocess == "thresh"):
gray = cv2.threshold(
gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
elif (preprocess == "blur"):
gray = cv2.medianBlur(gray, 3)
filename = "{}.png".format(os.getpid())
cv2.imwrite(filename, gray)
imgtext = Image.open(filename)
pytesseract.pytesseract.tesseract_cmd = 'C:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
# limpio el codigo de caracteres que no corresponden
texto = pytesseract.image_to_string(imgtext)
text = re.sub(r'[^\da-zA-Z0-9_() \n]+', '', texto)
print("-------------------------------------------------------------------")
print(" * * T E X T D E T E C T E D * *")
print("-------------------------------------------------------------------")
if text:
print("No está vacía")
contenidolineas = text.splitlines()
palabras = contenidolineas[0].split(" ")
mensaje2 = ""
for i in contenidolineas:
if (contenidolineas.index(i) == 0):
mensaje2 = mensaje2 + f"Entidad: " + contenidolineas[0]
else:
mensaje2 = mensaje2 + f"\nAtributo: "
palabras = i.split(" ")
for j in palabras:
if (palabras.index(j) == 0 and contenidolineas.index(i) != 0):
mensaje2 = mensaje2 + f"{j} tipo "
else:
mensaje2 = mensaje2 + f"{j} "
print(mensaje2)
print("-------------------------------------------------------------------")
else:
print("Está vacía")
nuevo = str(convertido + 1).zfill(7)
os.chdir('C:/Users/Usuario/Documents/Deteccion de Objetos/recortes')
os.mkdir(nuevo)
print("Cantidad de entidades ", len(cnts))
cv2.imshow('gris', gray)
cv2.imshow('difuso', blur)
cv2.imshow('thresh', thresh)
cv2.imshow('opening', opening)
cv2.imshow('image', image)
cv2.waitKey()
this is the another image: