This forum is disabled, please visit https://forum.opencv.org
| 2020-04-21 16:47:09 -0600 | received badge | ● Taxonomist |
| 2018-05-04 21:47:36 -0600 | received badge | ● Notable Question (source) |
| 2016-04-23 05:47:43 -0600 | received badge | ● Popular Question (source) |
| 2014-09-11 22:27:54 -0600 | received badge | ● Nice Question (source) |
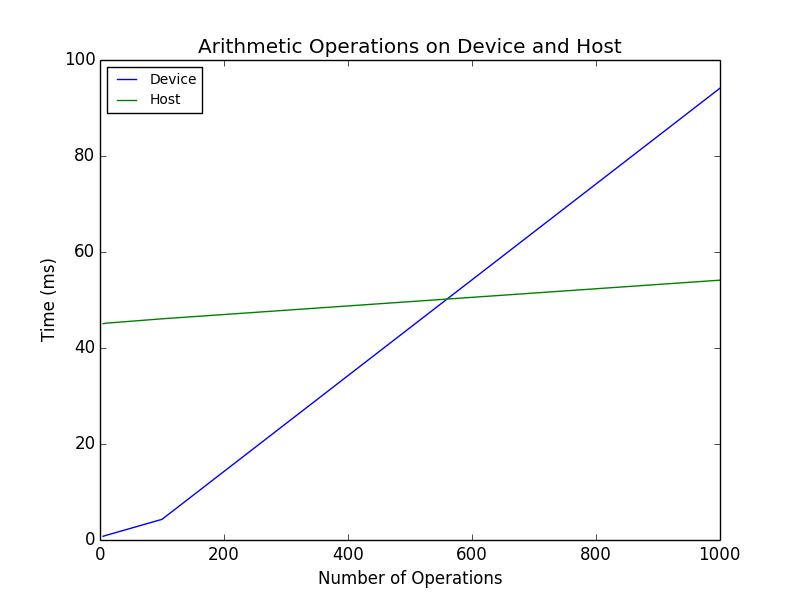
| 2014-08-27 08:05:17 -0600 | answered a question | Performance of OpenCL via cv::UMat (v3.0 [dev]) Thanks for your reply, Jakob. I do not know when GPU synchronization is happening while using OpenCV. However, the timing of each step indicates there is some dependency on the parameters. For example, on the arithmetic operation step, it takes longer to invoke 800 operations than it does 600 operations -- and the time is roughly proportional, which makes sense. However, like you pointed out, these might be asynchronous operations, i.e., some of the time might be showing up in the next step (copy device buffer to host). However, even if the operations are happening during the buffer copy to the host, the total time to execute the arithmetic operations is 2 orders of magnitude greater than the CPU implementation -- this has me puzzled. I was hoping someone close to the design/development of the cv::UMat / OpenCL functionality in OpenCV would recognize this question and offer some insight. However, it seems like this will require digging into the source code to determine the behavior. Thanks again for your reply. -adam |
| 2014-08-27 07:36:45 -0600 | received badge | ● Supporter (source) |
| 2014-05-27 16:09:12 -0600 | received badge | ● Editor (source) |
| 2014-05-27 15:41:38 -0600 | received badge | ● Student (source) |
| 2014-05-27 15:33:23 -0600 | asked a question | Performance of OpenCL via cv::UMat (v3.0 [dev]) I am using v3.0 of OpenCV, which is currently still under development. I observe surprising performance behavior when executing arithmetic operations using the The code below provides an illustration of the experiments performed, which is characteristic of other proprietary code that cannot be provided: The code above is a simplified version taken from a comprehensive test environment that allows for inspection of execution time relationships with respect to experiment variables (e.g., buffer size, number of arithmetic operations, etc.). Note, the code above exhibits the problem that will be described. The code was instrumented with timing functions from the Windows API (i.e.,
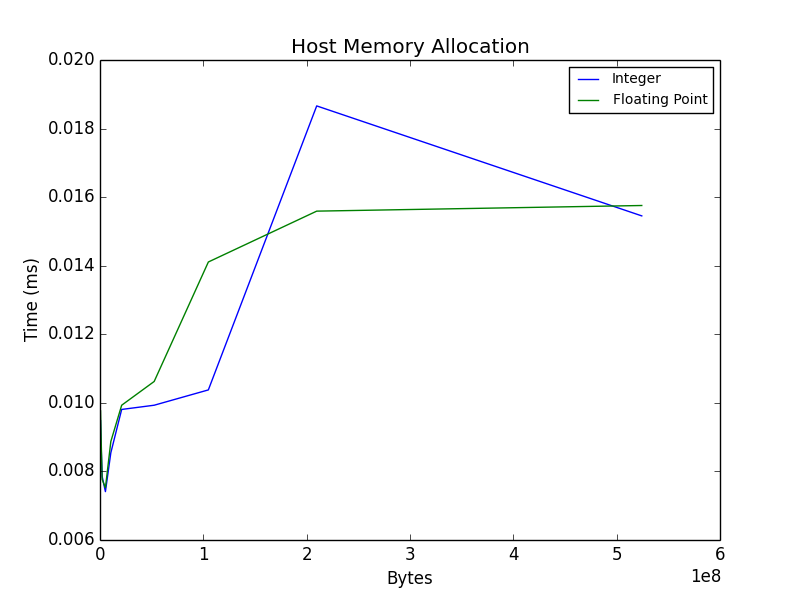
Allocate host buffer
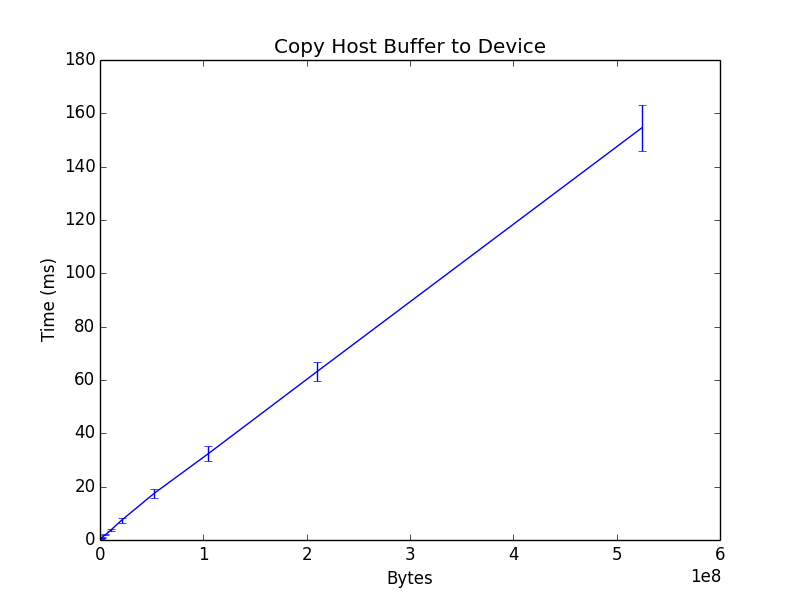
Copy host buffer to device
The host buffer is copied to the device using the
Execute arithmetic operations
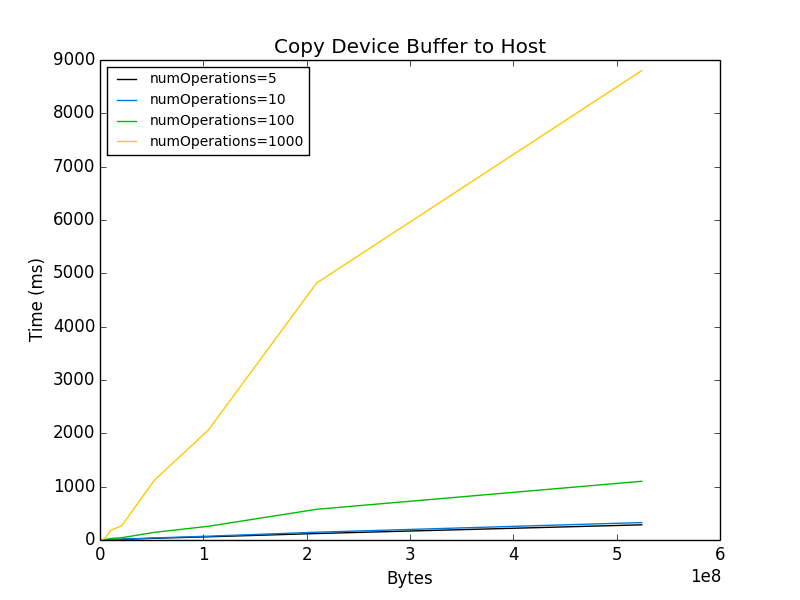
Note: the plot illustrates timing for a 500MB buffer (11448x11448).
Copy device buffer to host
If anyone can offer some insight into this issue, it would be greatly appreciated! Thanks for your time! -Adam Rossi |