This forum is disabled, please visit https://forum.opencv.org
| 2018-07-19 02:31:47 -0600 | received badge | ● Notable Question (source) |
| 2017-10-09 18:30:56 -0600 | received badge | ● Popular Question (source) |
| 2016-06-13 09:26:53 -0600 | commented answer | Preprocessing before OCR I see. I'm looking for the best way to do it by code and not manually :) |
| 2016-06-13 09:12:37 -0600 | commented answer | Preprocessing before OCR Hi, I can find the text blocks because they will be in the same place always, which OCR youv'e used and which output did you passed? the SWT? As you mentioned - getting the text as black on white is my current problem :) Thanks again! |
| 2016-06-13 08:03:24 -0600 | commented answer | Preprocessing before OCR Its depends, the best values was with simple thresholding (black 50%, white 50%) http://imgur.com/YMk6uCT Tesscart was unable to read text from the SWT outputs (both your, and my testings) Im trying to find a techinque to filter the text by its text so it will clear the noise. |
| 2016-06-07 09:02:07 -0600 | commented answer | Preprocessing before OCR i'm still struggling with it even when I'm using the SWT, tesseract still fails with getting the strings. any good resource about training it for new fonts? |
| 2016-06-03 09:35:18 -0600 | commented answer | Preprocessing before OCR Yeah thats why I'm thinking about scaling even more than 300% , though I was able to extract the "ARS" text from the output.png (by using imagemagick: convert input.png -resize 300% -black-threshold 50% -white-threshold 50% output.png |
| 2016-06-02 09:15:25 -0600 | commented answer | Preprocessing before OCR Thanks, do you mind sharing the code you were using? I found a python implemention of SWT but Tesscart wasn't able to get the text from the output neither on the 2 images you showed. THE SWT I was using for testing is: https://github.com/mypetyak/StrokeWid... again, thanks a lot ! |
| 2016-06-02 07:37:30 -0600 | commented answer | Preprocessing before OCR Original image is: http://i.imgur.com/e7bTW7r.png, I was cropping the area that contain the text Im interested in. Basically I think SWT will have problem with the anti-aliasing on the text too. :( EDIT: I found out that I resized using ImageMagick by 300% before processing it. thats where the different sizes came from. |
| 2016-06-02 07:12:43 -0600 | commented answer | Preprocessing before OCR you are right, the second image is after I scaled the original image. My original image is 960 x 540 but most of it is noise and I want the text only from the portion that I cut from it which includes the text I want to process. Do you think that scaling up and then applying SWT will help? Im working on it right now |
| 2016-06-02 04:41:11 -0600 | commented answer | Preprocessing before OCR Actually this is the size I have of this content I was thinking about scaling it and making it bigger. (Of course this is just a part of the whole image, but this is the part I'm intersted in so I simply cut it without resizing.) |
| 2016-06-01 13:16:58 -0600 | commented question | Preprocessing before OCR Yeah, the fact that I know where the banner is should be helpful and I can cut the desired area the problem is the resolution and the noise. |
| 2016-06-01 13:16:22 -0600 | received badge | ● Supporter (source) |
| 2016-06-01 13:16:22 -0600 | received badge | ● Supporter (source) |
| 2016-06-01 13:16:10 -0600 | commented answer | Preprocessing before OCR Hey! Thanks, I have read and tried to use SWT, my biggest problem is to clear the noises from the image and maybe scale it so the letters/numbers will be bigger. |
| 2016-05-31 09:30:28 -0600 | received badge | ● Student (source) |
| 2016-05-31 08:05:01 -0600 | asked a question | Preprocessing before OCR Hi all, I'm pretty new to CV, I'm doing some experiment that requires OCR, I'm ussing tesseract as the OCR Engine. I have the following image:
I was trying applying all kind of preprocessing techniques but wasn't able to filter all the noise and have only the text. (I'm interested in ARS, 0 - 1, TOT, 04:02) My biggest issue is finding a way to filter those texts even though I know their color (the fact that they are gradient makes it even a bigger issue for me) any tips/ideas on how to tackle this problem? some example of the image after some processing (which aren't good enough as the tesseract fails with reading it):
|

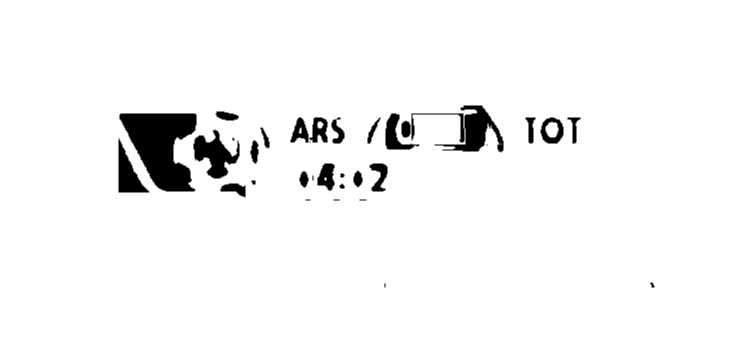
{kind=link}