I am really new to OpenCV and have been poking around for a month or two now trying to learn it by attempting to build an application that will help me and my friends play craps and keep things straight, especially while drinking. Since I am so new, I figure I will give as complete a description of my goals and understanding of what I think I should be doing so someone can explain where I am confusing myself and either making a task more complicated than it should be, or not understanding how complicated my approach actually is.
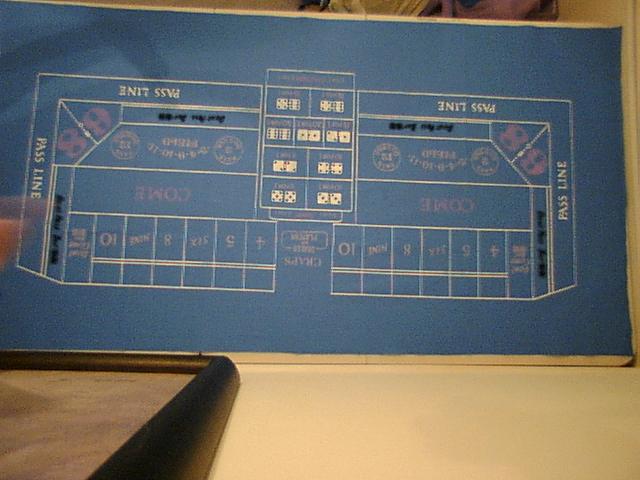
I suppose my explanation will be easier with an idea of the images I am working with. The background can be found here: craps-background.jpg and a "sample" of the objects I want to detect is here: craps_circle_test.jpg
{kind=link}
{kind=link}
My immediate goal is to have one camera mounted so it can see the whole board, recognize the play area, detect objects (dice, chips, markers) and facilitate play by keeping track of the point, and marking bets that win or loose. Ultimately, I want to tie in a projector that can provide feedback directly on the table and use stereo vision so I can identify objects in 3D to determine that this object consists of x number of chips of varying denominations and more accurately track a bet and calculate the winnings, or detect that a dice came to rest on a chip, but I'm taking this in baby steps and not really worried about the end goals just yet.
My reading and tinkering has gotten me to the point of having some code that can read the image from the camera and at least show a mask of the playing field to become familiar with the concepts of computer vision. I have also incorporated the squares sample so it can show the area of the playing field. (Still need to limit this to the single largest square, but I am getting the feeling I might be going in the wrong direction.)
Isolating the green field in a black and white threshold image gives me not only the playing area and the outer region where the players stand (which can be ignored) but also does a really good job of showing the objects on the playing area that I can probably use to track objects, but is mingled with the different patterns on the playing field to designate what bets are in play.
I suspect that I am not approaching the problem correctly which is why I am getting lost in the best way to process this and my question is if someone has some advice on how to properly approach this issue?
I think I should threshold on the green felt, and ignore (mask) all the pixels outside of that area, and somehow mark that this area is the playing field. Then I should somehow find, mark and mask the playing field's printed area as well as the green playing field itself. The camera will always see a good portion of the printed area and should know what those areas are so an object's purpose can be identified, but I don't need to process those pixels that can be seen for every frame because if the camera sees them, I know there is nothing physically there to process.
At that point I should probably detect blobs, identify the object the blobs represent and then determine their purpose based on their position on the board. (Dice rolled a 7, the point is OFF, there is a bet on the Hard Eight, etc.)
In case my questions aren't clear, I am wondering if my approach is even correct? Does anyone have any advice or sample code that I should be studying to read a game table to extract the information that I will need to pass to the code that will actually process the game the computer is watching? When I started this project, I didn't think I would have as much of a learning curve with the math and concepts in computer vision that I find myself tripping over.
Thanks in advance for any pointers anyone can provide,
-Steve