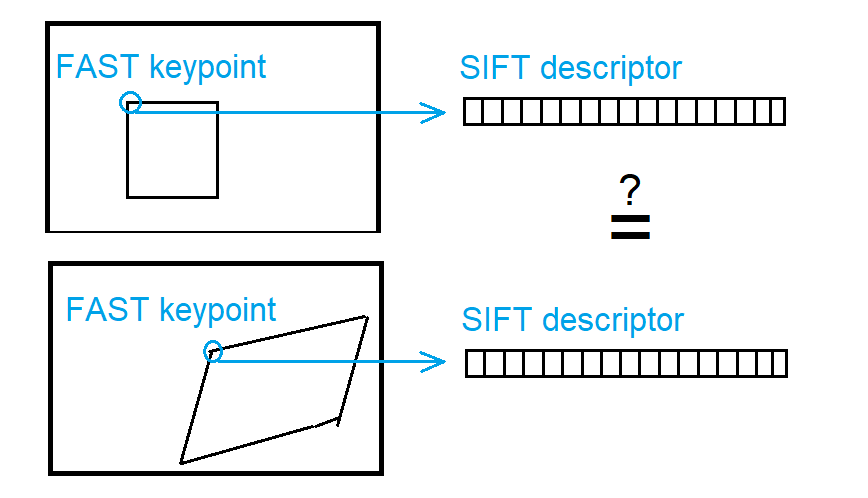
The SIFT is said to be scale, rotation and viewpoint invariant. But when does it gain this characteristic? If I were to detect keypoints with the FastFeatureDetector and get descriptors with the SiftDescriptorExtractor, would the descriptors be the same for the same keypoint seen from a different viewpoint?
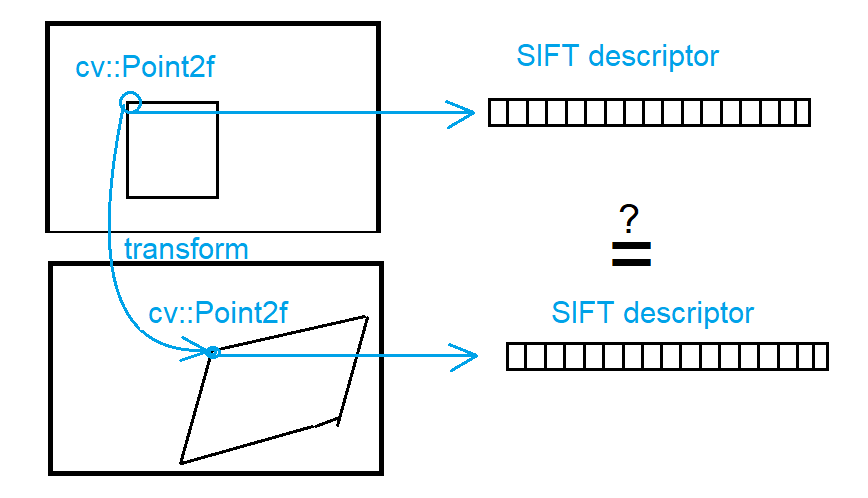
If I convert cv::KeyPoint into cv::Point2f to transform the keypoints into other viewpoint and then convert the transformed cv::Point2f it back to cv::KeyPoint, would the information in the cv::KeyPoint be the same, as if the keypoint at the same place was detected by SiftFeatureDetector?