Hi, I have written a CUDA (8 on my machine) version of a program and compared it to an OpenCL(1.2) / T-API version. The former clocks in quite a bit slower even when using Unified Memory (UM). Could someone advise please? The normalize() function is multi-channel in the T-API, but underneath probably isn't. I had expected Shared Virtual Memory (UM in CUDA) to be faster, which I can't do with my PC because it is limited to OpenCL1.2... I read somewhere it can depend on the size or complexity of the filters, whether pixels are reread etc. but that would be the same for the CL version, wouldn't it?
CUDA (5-6 sec.)
ma = HostMem::getAllocator(HostMem::PAGE_LOCKED);
cv::Mat::setDefaultAllocator(ma);
prev_frame = GpuMat(read_frame);
for (int i = 0; i < 100; i++) {
d_out = ImEnhance(prev_frame);
}//time
ma = HostMem::getAllocator(HostMem::WRITE_COMBINED);
cv::Mat::setDefaultAllocator(ma);
prev_frame = GpuMat(read_frame);
for (int i = 0; i < 100; i++) {
d_out = ImEnhance(prev_frame);
}//time
ma = HostMem::getAllocator(HostMem::SHARED);
cv::Mat::setDefaultAllocator(ma);
prev_frame = GpuMat(read_frame);
for (int i = 0; i < 100; i++) {
d_out = ImEnhance(prev_frame);
}//time`
:
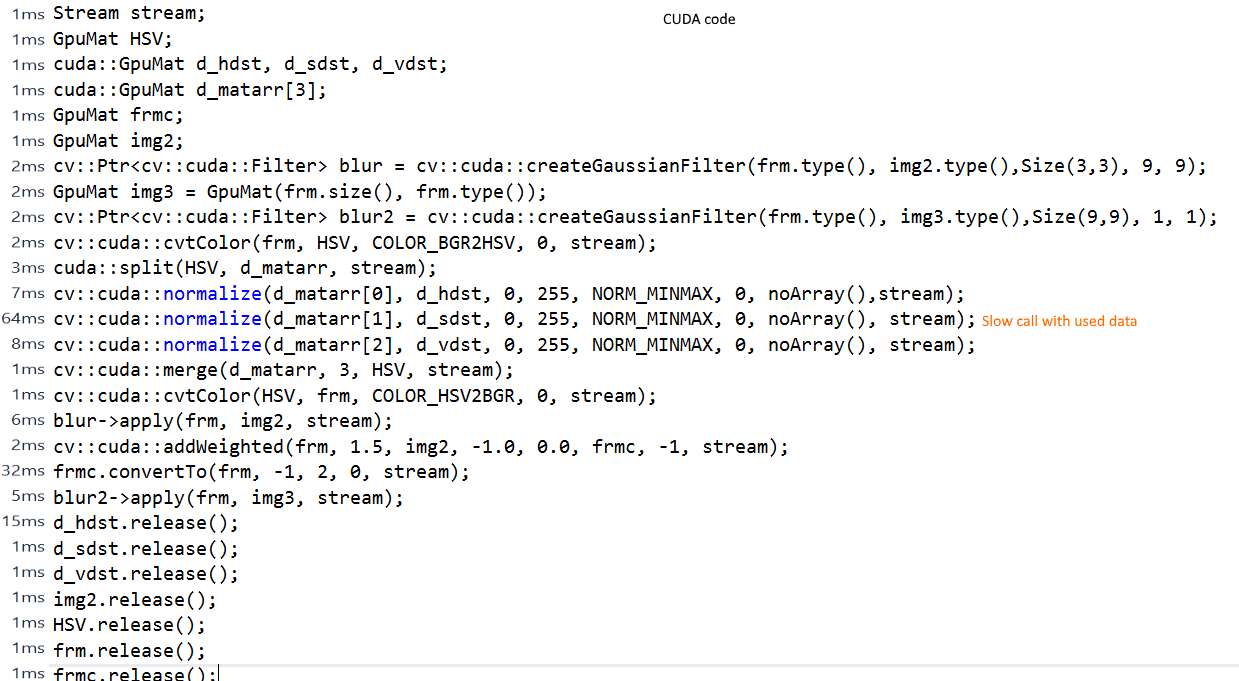
GpuMat ImEnhance(GpuMat frm){
GpuMat HSV;
cuda::GpuMat d_hdst, d_sdst, d_vdst;
cuda::GpuMat d_matarr[3];
cv::Ptr<cv::cuda::Filter> blur = cv::cuda::createGaussianFilter(frm.type(), frm.type(),Size(3,3), 9, 9);
cv::Ptr<cv::cuda::Filter> blur2 = cv::cuda::createGaussianFilter(frm.type(), frm.type(),Size(9,9), 1, 1);
cv::cuda::cvtColor(frm, HSV, COLOR_BGR2HSV, 0);
cuda::split(HSV, d_matarr);
cv::cuda::normalize(d_matarr[0], d_hdst, 0, 255, NORM_MINMAX, 0, noArray());
cv::cuda::normalize(d_matarr[1], d_sdst, 0, 255, NORM_MINMAX, 0, noArray());// <- slowest call
cv::cuda::normalize(d_matarr[2], d_vdst, 0, 255, NORM_MINMAX, 0, noArray());
cv::cuda::merge(d_matarr, 3, HSV);
cv::cuda::cvtColor(HSV, frm, COLOR_HSV2BGR, 0);
blur->apply(frm, HSV);
cv::cuda::addWeighted(frm, 1.5, HSV, -1.0, 0.0, frm, -1);
frm.convertTo(frm, -1, 2, 0);
blur2->apply(frm, frm);
d_hdst.release();
d_sdst.release();
d_vdst.release();
HSV.release();
return frm;
}
OpenCL (3-4 sec)
UMat ImEnhance(UMat frm) {
UMat HSV;
UMat HSV2;
UMat HSV3;
cvtColor(frm, HSV, COLOR_BGR2HSV);
normalize(HSV, HSV2, 0, 255, NORM_MINMAX);
cvtColor(HSV2, HSV3, COLOR_HSV2BGR);
UMat img2;
GaussianBlur(HSV3, img2, Size(3, 3), 9, 9);
addWeighted(HSV3, 1.5, img2, -1.0, 0.0, frm);
img2.release();
UMat img3;
frm.convertTo(img3, -1, 2, 0);
GaussianBlur(img3, frm, Size(9, 9), 1, 1);
HSV.release();
HSV2.release();
HSV3.release();
img2.release();
img3.release();
return frm;
}