This forum is disabled, please visit https://forum.opencv.org
| 2017-10-16 17:13:16 -0600 | received badge | ● Popular Question (source) |
| 2016-06-15 10:22:12 -0600 | marked best answer | highgui window_w32.cpp error: 'TBBUTTONINFO' was not declared in this scope I use OpenCV3-beta in Eclipse under Win8.1 and have to build source from git since there are no minGW libs available for download. It was ok before, but today(just now) I updated all sources and now mingw32-make suddenly fails: \git\opencv\modules\highgui\src\window_w32.cpp:2011:9: error: 'TBBUTTONINFO' was not declared in this scope It is not the only error, there are some another errors which is similar to mentioned above: \git\opencv\modules\highgui\src\window_w32.cpp:2023:81: error: 'BTNS_AUTOSIZE' was not declared in this scope \git\opencv\modules\highgui\src\window_w32.cpp:2023:97: error: 'BTNS_BUTTON' was not declared in this scope |
| 2016-06-15 10:22:12 -0600 | received badge | ● Self-Learner (source) |
| 2016-01-12 16:03:44 -0600 | commented question | optimization techniques for opencv, C++ "You need permission. Ask the owner for access, or switch to an account with permission." |
| 2016-01-12 06:18:23 -0600 | commented answer | imwrite in opencv gives a black image You can save 32 bits as CV_8UC4 image, but it is a little tricky. Use If you want "just segmented image" then 4 colors are enough for any segmentation :) |
| 2016-01-12 06:05:21 -0600 | commented question | How evaluate the performance of OpenCV OpenCV contains a thousands of functions. What do you mean by "OpenCV performance"? Do you know OpenCV and ITK functionality intersection to compare only common parts? ITK is for medical imaging, OpenCV is for near-realtime video and image processing of broad purpose -- but what is your task? |
| 2016-01-12 05:52:35 -0600 | answered a question | imwrite in opencv gives a black image img8bit and CV_32FC3 ? 8 bit image is CV_8UC1 or CV_8UC3 (afair imwrite writes 8 bit 3 channel or 8 bit 1 channel images only). You have CV_32F (one channel) so try CV_8UC1: Sure you will lose some information, but if you want to have just visualization it is ok. If you want store and then read all information use |
| 2016-01-11 17:22:04 -0600 | commented answer | Triangle detection - Canny failing on corner OpenCL version of Canny contains bug more than 1 year. Try to compare OpenCL and non-OpenCL (use |
| 2016-01-11 16:41:58 -0600 | commented question | optimization techniques for opencv, C++
|
| 2016-01-11 16:15:26 -0600 | commented question | optimization techniques for opencv, C++ @pradeep_kb please update you question with profiling information. Based on your manual profiling one can see the most calculation-intensive part is morphology, it takes ~80% of time. The common advise for morphology is to avoid large kernels, emulation for large kernel is simplest resize and small kernel or "small kernel N-times passing". |
| 2016-01-10 19:18:54 -0600 | commented question | optimization techniques for opencv, C++ |
| 2016-01-10 19:14:47 -0600 | answered a question | is it possible to apply convolution in multiple dimensions? Short answer: no, afaik there are no out of the box 3D convolution for arbitrary kernel in openCV. Long answer: some convolution kernels are separable i.e. 2d convolution could be presented as a sequence of two 1D-convolution in one direction and then 1D in another direction (see |
| 2016-01-10 18:45:50 -0600 | commented question | optimization techniques for opencv, C++ Where is your program bottleneck? Did you perform profiling? |
| 2016-01-10 18:42:04 -0600 | answered a question | Java : Convert a binary file (received from Bayer sensor) to a Bayer image and then to an RGB image. In C++ it is |
| 2015-12-08 19:05:19 -0600 | commented question | How can I increase the patch size of keypoints? Are you sure your regions are too small? By default drawMatches just draw points, not full patches. Use DRAW_RICH_KEYPOINTS flag for drawMatches(...). See docs. |
| 2015-12-08 18:53:18 -0600 | answered a question | How can I increase the patch size of keypoints? As I can see from source code, you can fill |
| 2015-12-08 18:18:27 -0600 | commented answer | How can I increase the patch size of keypoints? It is size in bits (not pixels), and it is set to max by default: |
| 2015-11-23 06:16:40 -0600 | commented question | how optimize kaze descriptor I mean 'create' not 'use' since afaik no OpenCL AKAZE in OpenCV yet. |
| 2015-11-17 13:10:03 -0600 | commented answer | Where can I find the computational complexity of the algorithms? As I can see from brief view to the linked article the main complexity comes from matrix inversion and this matrix size is ~number of reference points. So one can assume that complexity is O(n^3). Sure there some other calculations but large matrix inversion is the most intensive. You can easily check this assumption plotting 'calculation time vs number of points' chart and fitting it by polynomial curve (or plotting it in semi-log scale and fitting by line). Anyway big-O notation is asymptotic estimation only, so for small N it can significantly deviates from 'ideal' polynomial form. |
| 2015-11-17 08:41:24 -0600 | commented question | how optimize kaze descriptor Guess the best way to reduce execution time is to create its OpenCL version (afaik there is only CPU version of algorithm). KAZE by its nature is parallel so performance could be boosted by OpenCL approach. |
| 2015-11-17 08:15:03 -0600 | answered a question | Where can I find the computational complexity of the algorithms? Usually every complicated method in OpenCV docs links to science article, where complexity always mentioned. This science articles often has open access. And sometimes complexity mentioned in .h files. |
| 2015-11-16 09:17:39 -0600 | commented question | Process x-ray for easier image detection? "Certain items" can be detected with certain approaches ) Show your picture and mark item on it to be very specific. |
| 2015-11-16 08:03:21 -0600 | answered a question | OpenCV stitching output is unstable The reason could be RANSAC which uses random generator to find best matches, so it is not deterministic approach. |
| 2015-11-14 16:23:55 -0600 | commented question | Account Recovery guess link is better 1. it shows that this question is already exists and answered 2. link has confirmation from recovered OpenID, it gives more faith ) |
| 2015-11-14 14:16:58 -0600 | commented question | Account Recovery |
| 2015-11-13 19:31:03 -0600 | answered a question | Background averaging not working If bees are always moving and there are no forever-static bees, you may slightly modify your approach and use MOG only for creating binary mask of static image parts. Then just overlap this static parts from your frames and you will have "street without moving people". |
| 2015-11-12 19:52:01 -0600 | commented answer | Contact site admin for account issue Yes, it works. My GoogleID-account (this) is now restored. Thank you. |
| 2015-04-23 05:59:40 -0600 | received badge | ● Nice Question (source) |
| 2015-01-16 08:09:48 -0600 | commented question | Is it possible to identify fish by scale pattern with OpenCV? How many photos of fish do you have in your database and how many photos do you have to process every year (?) to find it in this database? How many photos per fish? How large is acceptable level of "false positive" and "false negative" results? |
| 2015-01-15 16:55:38 -0600 | commented question | Is it possible to identify fish by scale pattern with OpenCV? Can you show what is "scale pattern" on your pictures? And also show a few possible patterns. |
| 2015-01-15 00:40:49 -0600 | commented answer | Align 2 photos of text @axk Your images scales differs, so "some size normalization should be performed (based on lines interval, letters size etc) or brute force like build size pyramid using small steps like (1.5)^(1/8) = 1.05". Phase correlate works good for dx+dy shifting only, not for scale change. |
| 2015-01-14 04:18:22 -0600 | commented answer | Align 2 photos of text @FooBar It is the same page photos, hence it does not matter how many rows in your descriptors -- they will mostly match each other, the bigger descriptors area the smaller false positive match rate. |
| 2015-01-13 15:50:55 -0600 | answered a question | Align 2 photos of text I see a few possible solutions for your particular task:
|
| 2015-01-13 08:32:59 -0600 | commented question | Canny (OCL, 3-beta) can not detect connected contour of black square on a white background. @Antonio, thanks for you informative report on OpenCV bug-tracker. I hope this will activate works on that issue. According to attached "cmake-gui-out.txt" file there I have 32-bit version. |
| 2015-01-12 15:41:08 -0600 | answered a question | Writing Video to File Windows 8 has a lot of security restrictions by default, including for system partition root path, so you'd better try to write to you project directory "./thevideo.avi" . |
| 2015-01-12 15:31:07 -0600 | commented question | About OpenCV's roadmap I have seen on November somewhere on opencv.org about February as the month for OpenCV3.0 release. But looking to the bunch of reported bugs.. guess it will be on summer-autumn 2015. |
| 2015-01-12 15:09:56 -0600 | commented question | Canny (OCL, 3-beta) can not detect connected contour of black square on a white background. @Antonio, thanks for your answer. I tested Canny and it is ok in 2.4 with this test picture, your code works perfect. The problem is actual for OpenCV3-beta only. Post updated by soft- and hardware info. As for threshold, from my point of view it is more convenient to have normalized output i.e. threshold should not be a function of another parameters, this increases the code hidden-errors possibility. |
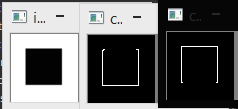
| 2015-01-12 15:04:10 -0600 | edited question | Canny (OCL, 3-beta) can not detect connected contour of black square on a white background. Simple code for simple image result is not connected contour as it is expected. Top or bottom edge missed. Result printscreen is square-bug.png . The picture itself is square.png. Code is: Am I doing something wrong? I use OpenCV3-beta in Eclipse under Win8.1 and have to build source from git. Source updated and compiled today (last canny.cpp change was 7 weeks ago). I do have openCL so I guess UMat Canny function uses OCL_RUN version of function UPDATE: device and system info
|
| 2015-01-09 15:33:55 -0600 | edited answer | OpenCV2.4.9 - OpenCL - oclMat Just guess (never tried this): it is worth do use ROI(1x1px), copy it to a new 1x1 oclMat and download this small matrix. Accoring to docs if you try download a part of oclMat then all matrix is transferred: "Data transfer between Mat and oclMat: ROI is a feature of OpenCV, which allow users process a sub rectangle of a matrix. When a CPU matrix which has ROI will be transfered to GPU, the whole matrix will be transfered and set ROI as CPU’s. In a word, we always transfer the whole matrix despite whether it has ROI or not." -- row(i).col(j) is a kind of ROI and this is your case. |
{kind=link}
{kind=link}