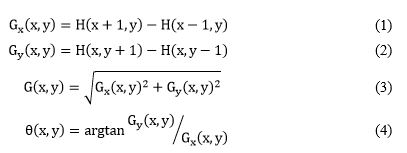This forum is disabled, please visit https://forum.opencv.org
| 2017-06-12 14:28:08 -0600 | commented question | Sending Mat over the web Yes. I'll be sending it with an HttpClient "POST". |
| 2017-06-12 05:56:35 -0600 | asked a question | Sending Mat over the web I need to send a Mat over the web (to ASP .net c# backend) Any ideas or ready examples? |
| 2017-06-12 05:30:08 -0600 | commented question | kNN implementation and required input/output not exactly sure if it can be solved with regression let me know your thoughts |
| 2017-04-04 15:36:11 -0600 | asked a question | kNN implementation and required input/output I found a ready code but have some issues mapping my thoughts and what I've implemented in [weka] especially that how do I supply my data to the algorithm. I have: x, y, speed, factor. They all numbers, the [x] & [y] are the coordinates of the object. [speed] is the speed of the object. [factor] is division of the initial speed and the current speed of the object. So I need to build a model based on kNN so I can supply the model with :[x, y, speed] to get [factor] which is predictable based on the model I've built. I have a sample data as per the following (sample from 50k rows): x, y, speed, factor 414, 369, 250.004761, 1.1 418, 360, 225.004285, 1.222222221 423, 352, 225.004285, 1.222222221 427, 344, 200.003809, 1.374999998 431, 336, 200.003809, 1.374999998 435, 329, 200.003809, 1.374999998 438, 322, 175.003333, 1.571428568 441, 315, 175.003333, 1.571428568 444, 309, 150.002856, 1.83333334 448, 303, 175.003333, 1.571428568 451, 297, 150.002856, 1.83333334 454, 291, 150.002856, 1.83333334 457, 285, 150.002856, 1.83333334 460, 280, 125.00238, 2.200000008 463, 275, 125.00238, 2.200000008 466, 270, 125.00238, 2.200000008 469, 265, 125.00238, 2.200000008 472, 260, 125.00238, 2.200000008 474, 256, 100.001904, 2.75000001 477, 251, 125.00238, 2.200000008 The code I found and I can't figure out how to map my table and the input (450, 300, 100.002834) in order to get the predicted/calculated (factor) I appreciate any explanation to the declared [Mat]s in the code as they seemed confusing. |
| 2017-04-02 09:03:34 -0600 | commented question | Ways of doing realtime processing Is there any example for that? |
| 2017-04-02 06:34:10 -0600 | asked a question | Ways of doing realtime processing What is the best way to do realtime processing for frames? I'm reading from a video and processing cascade detector and a tracker as well so the speed is becoming bad. I need to play or read from a camera while processing my algorithm. If ever you worked on something please advise. |
| 2017-02-28 07:49:51 -0600 | received badge | ● Student (source) |
| 2017-02-28 04:34:42 -0600 | commented question | building from source along with opencv_contrib Maybe you both are right. I have to research that with Mr. Google :) |
| 2017-02-27 07:41:29 -0600 | asked a question | building from source along with opencv_contrib I'm working on a research with opencv [cpp] and I had to use the opencv_contrib. You know that in this case we must build the library from the source and I found a good reference on Youtube.com but I was wondering about:
I know it is not a core opencv question but I appreciate any assistance |
| 2017-01-10 02:26:06 -0600 | commented question | Background subtraction to detect cars on a road @abhijith, It doesn't detect far objects, some cars are detected as 2 or more blobs instead of 1 (especially buses), sometimes if 2 cars moving side by side it will detect them as a single car. |
| 2017-01-08 06:23:36 -0600 | commented question | Background subtraction to detect cars on a road Yes I did. The results were worst since the video is having some pixels changes over time due to lightning and air (there are some trees) |
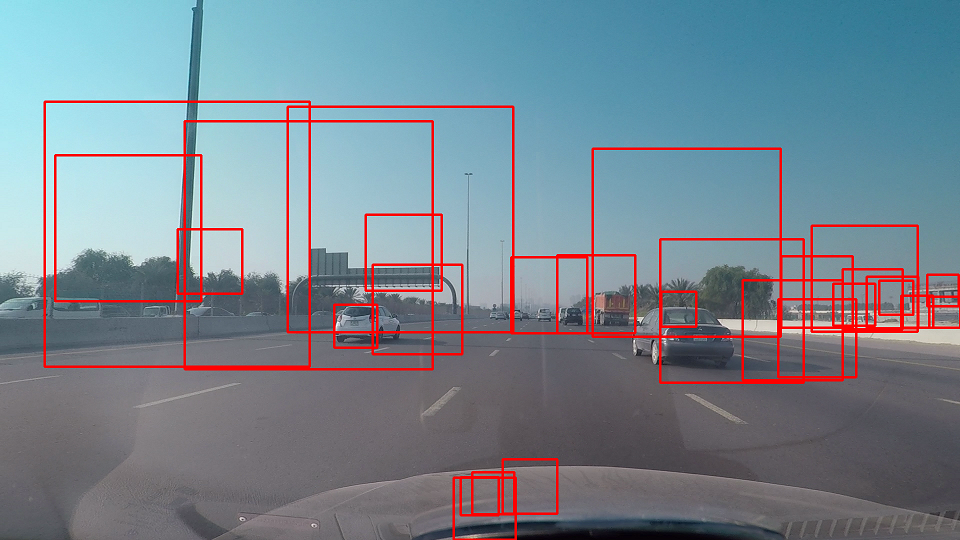
| 2017-01-07 10:18:49 -0600 | asked a question | Background subtraction to detect cars on a road I've implemented the background subtraction method to detect moving blobs but the issue is that it doesn't detect the far objects and sometimes the moving cars are not accurately detected as a single blob (sometimes it splits into 2 or 3, sometimes it doesn't detect it). I've also implemented the code here: https://github.com/MicrocontrollersAn... Is there any sophisticated read solution to do the needful and it does the job perfectly (detecting car blob and tag it with ID)? |
| 2016-12-01 07:27:25 -0600 | received badge | ● Self-Learner (source) |
| 2016-12-01 04:43:53 -0600 | received badge | ● Scholar (source) |
| 2016-12-01 04:43:23 -0600 | answered a question | using opencv with c++ .net application compilation issues Apart from doing the linker and include stuff I had also to: Use project build x64 instead of x86 Then I had to copy the .dlls to my project directory Then set the linker->System->SubSystem to WINDOWS. Then I had to go Advanced->Entry Point set to Main Don't forget that if you choose x64 to verify the linker and include setup is already implemented. Because I had to redo it as it seems x86 and x64 got different setup. |
| 2016-11-27 04:31:14 -0600 | commented question | using opencv with c++ .net application compilation issues There is nothing special in the code but I included it. I removed the arrow brackets for 2 includes because of the formatting in the website is ignoring them. |
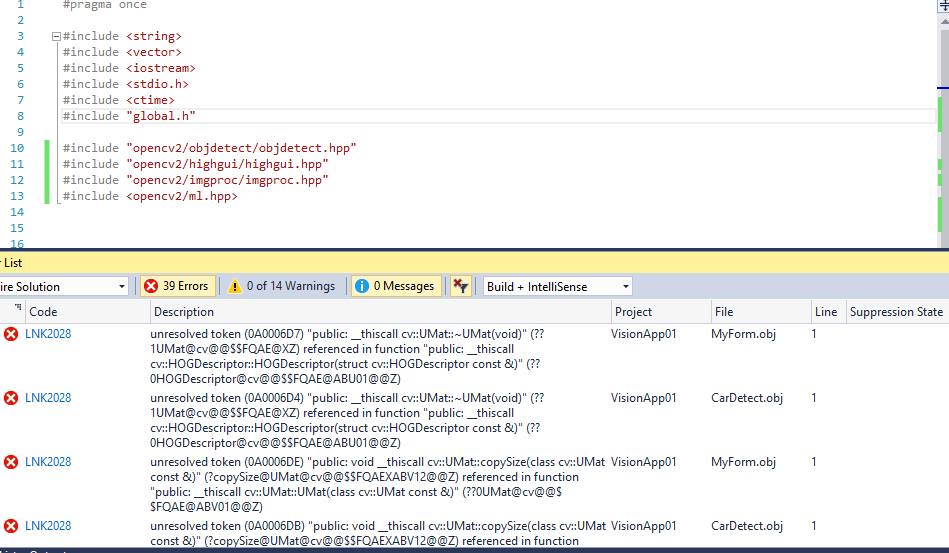
| 2016-11-27 02:23:46 -0600 | asked a question | using opencv with c++ .net application compilation issues I didn't face any issues while linking opencv library with basic console application but when I moved to do the same in a .net framework template I got many LNK errors
I didn't do anything strange except that I included the include and using namespace only. I appreciate any assistance provided PS: I managed to run it if I install the opencv package via NuGet but I don't wan't to use NuGet. (I tried to get frames from video but it is not working and I get an unhalded error while the same code is running with console without an issue) This is a clean Form header. Whenever I place the include tags of opencv I will not be able to compile:
include "opencv2/objdetect/objdetect.hpp"
include "opencv2/highgui/highgui.hpp"
include "opencv2/imgproc/imgproc.hpp"
include opencv2/ml.hpp
include ctime
namespace VisionApp01
{
using namespace cv;
using namespace cv::ml;
using namespace System;
using namespace System::ComponentModel;
using namespace System::Collections;
using namespace System::Windows::Forms;
using namespace System::Data;
using namespace System::Drawing;
|
| 2016-11-18 00:46:09 -0600 | received badge | ● Enthusiast |
| 2016-11-17 07:59:00 -0600 | commented question | best way to do the traincascade via the standalone tool Maybe you are right.. Can you provide me with the best opinion, method or ready code you came across? Note that the camera is moving and not fixed. |
| 2016-11-17 06:35:17 -0600 | commented question | best way to do the traincascade via the standalone tool The idea is getting the shadow locations, make the detected Rect as squared, resize to 64x64, then run a verification for that squared area via SVM traind with HOG from another samples of cars rear shot. I'm trying to replication the work of some other researchers in order to do some enhancements. |
| 2016-11-15 13:42:04 -0600 | commented question | best way to do the traincascade via the standalone tool Also I wonder if my positive and negative samples should be converted to grey scale and then have a histogram equalization? |
| 2016-11-15 11:58:41 -0600 | commented question | best way to do the traincascade via the standalone tool So what do I have to do then? As per my investigation I found everybody is telling to get samples of the object in its many statuses. For the squared detection actually I'm making it like that, when I get the Rect vector I'm making the height equals the width before I plot the borders on the image so the |
| 2016-11-13 23:40:28 -0600 | received badge | ● Editor (source) |
| 2016-11-13 23:39:40 -0600 | asked a question | best way to do the traincascade via the standalone tool Hi all I'm trying to train a classifier to detect cars shadows (rear view) and I am facing difficulties doing that, later I want to use the output to verify the possible car region via HOG+SVM (will worry about it later). I don't know exactly what is needed to do so as I'm using around 692 positive samples with 4400 negatives converted to gray, cropped exactly to the object (160x45). for training I'm using 600 pos, 3500 neg. My target dimensions: -w 60 -h 17 Positive samples are like (160x45):
Negative samlpes are like (160x45):
And this is the horrible result with only 1 correct catch (I made the rectangle height similar to the width to match the whole car):
What exactly is wrong? Do I need more samples? Is it required to do histogram equalization (before or after)? Is it mandotary to use the annotation tool (I'm using cropped images so my pos.txt having things like pos/pos2.png 1 0 0 160 45)? Do my negative samples should be a full image or just peices matches the size of the positives? I'm so confused! Appreciate any help really Thanks |
| 2016-10-28 08:08:44 -0600 | asked a question | HOG calculation I'm applying a research that includes HOG + SVM Is there any process is needed before using OpenCV HOG features extraction? In the research paper they are talking about some mask to be applied as a first step: 1D centered point discrete derivative mask [-1, 0, 1] and [-1, 0, 1]^-1 in one or both of the horizontal and vertical directions to obtain the gradient orientation and gradient magnitude. We can use the Eq. 1 and Eq.2 to calculate each pixel point's horizontal and vertical gradient value, respectively. And use the Eq. 3 and Eq. 4 to calculate pixel point's gradient magnitude value and gradient value, respectively.
Then: 2) Orientation binning: Each pixel within the cell casts a weighted vote for an orientation-based histogram channel based on the values found in the gradient computation. The histogram channels are evenly spread over 0 to 180 degrees or 0 to 360 degrees, depending on whether the gradient is 'unsigned' or 'signed'. In our study, we use the 'unsigned' and nine channels that evenly spread over 0 to 180 degrees to construct our histogram. As for the vote weight, pixel contribution can either be the gradient magnitude itself, or some function of the magnitude. We just use the gradient magnitude value as vote weight in our study. 3) Descriptor blocks: In order to avoid for changes in illumination and contrast, the gradient strengths must be locally normalized, which requires grouping the cells together into larger, spatially connected blocks. The HOG descriptor is then the vector of the components of the normalized cell histograms from all of the block regions. These blocks typically overlap, meaning that each cell contributes more than once to the final descriptor. Every four cells (22) comprise one block in our study. For an image with size of 6464, we assume that each cell's size is 88, and the size of one block is 1616 since one block comprises four cells. Thus, we can consider that there are 49 blocks in an image since one block can be slid seven times in horizontal and vertical orientation, respectively. Meanwhile, there are nine channels in one cell and 36 features in one block. Thus, we can obtain the number of features is 1764 (3649) in a 6464 image that as shown as Figure 7. So please is there anybody can help me in this task as I'm supposed to compare this to a new method of my own (in progress).. |