This forum is disabled, please visit https://forum.opencv.org
| 2015-11-02 14:19:14 -0600 | asked a question | BOWTrainer 'blends' image features I'm using the BOWTrainer class to cluster multiple segments of texture classes to create a texton dictionary and class models. For this i'm first using the .add method to add the 1d texture segments to the object then using the .cluster method to generate the cluster centres. I'm having issues with classifier accuracy and wanted to confirm whether this class works by clustering the segments separately? I'm worried that if i'm adding textures with distinct lines,(like bricks), that these could loose their definition if they're clustered together? Thanks |
| 2015-10-13 17:06:48 -0600 | answered a question | Problem with OpenCV calibration module In case anyone is still not sure about this, there's a working example of a calibration setup here for the ar drone 2.0. The camera used is a wide angle lens and he uses 11 images to produce a rough calibration. As far as for the original three questions:
Anyway hope this helps. I'll update this if i find anything else which is relevant. |
| 2015-10-13 11:12:18 -0600 | commented question | Problem with OpenCV calibration module did anyone find a solution to this, i'm having similar issues. I've been able to successfully calibrate a camera with mild distortion but when using the ar drones wide angle lens it throws the following error: OpenCV Error: Bad argument (Unknown array type) in cvarrToMat, file /home/james-tt/Dropbox/Term_2/Final_Project/OpenCv/opencv-2.4.9/modules/core/src/matrix.cpp, line 698 terminate called after throwing an instance of 'cv::Exception' what(): /home/james-tt/Dropbox/Term_2/Final_Project/OpenCv/opencv-2.4.9/modules/core/src/matrix.cpp:698: error: (-5) Unknown array type in function cvarrToMat |
| 2015-09-12 05:31:43 -0600 | commented answer | Take frame after some millisecond oh i've only worked with the c++ api, so cant help you there |
| 2015-09-11 16:23:57 -0600 | answered a question | Take frame after some millisecond Something like this will get you two images and save them to two matrixes then you can always pass them to functions from inside the loop for processing. |
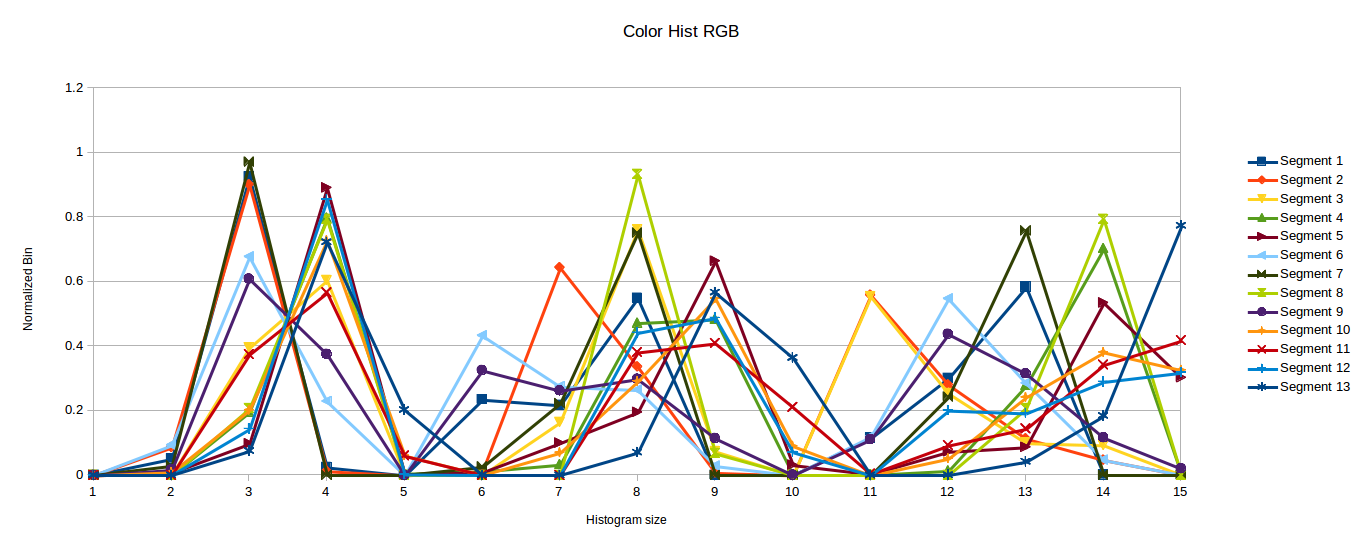
| 2015-09-10 07:59:57 -0600 | asked a question | displaying histogram model space i'm just writing up my dissertation which is based on bag of visual words classification and was looking to find a way to effectively visualise the separate model spaces and ideally how the interact and effect on interclass distance when new images/classes are added. To give you some details the models are histograms with approximately 100 bins and i have 8 classes so 8 dimensions?. Each 8 classes has between 8 and 40 models each comprising 10 cluster centers. The first option was a density histogram, aggregating all of the histograms for each class and drawing trend curve, then displaying them together similar to this: To me this looks clutered though and doesn't really show the interaction.
So i though of again aggregating the bin counts and displaying them stacked on their own horiztonal line like this:
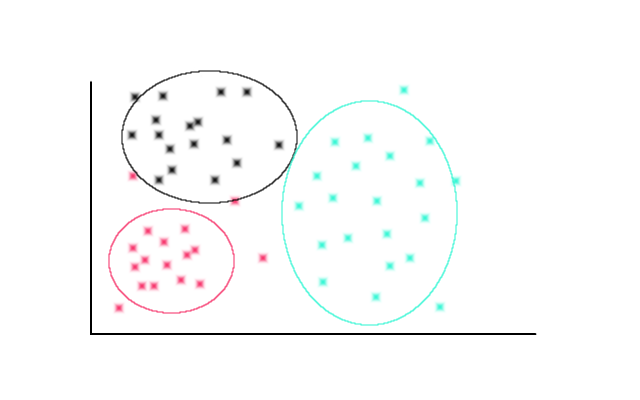
I think that could display the information with less clutter but was looking for something more descriptive. Like a 2d histogram of scatter plot as below:
I'm not sure however how to represent it in this space or what the y axis would be. Does anyone know of anything like this or any other ways to represent a model feature space? Also is there anyway to do the required calculations outside of opencv like in libre office as that's where i'm going through the data. Thanks |
| 2015-09-05 15:16:39 -0600 | commented question | Matching kmeans clusters generating non random sequence Actually to rephrase what do you think is the best method to do a fitlerbank based bag of words as there has to be a method which doesn't require you to duplicate training images to increase you chances of a match |
| 2015-09-05 13:14:17 -0600 | commented question | Matching kmeans clusters generating non random sequence ah that makes sense!! hmm ok so is there anyway to remove this inaccuracy? outside of running test images or or model generation multiple times per image or just testing/adding one model at a time i cant think how to get around this? |
| 2015-09-05 11:16:46 -0600 | answered a question | Matching kmeans clusters generating non random sequence ah that makes sense!! hmm ok so is there anyway to remove this inaccuracy? outside of running test images or or model generation multiple times per image or just testing/adding one model at a time i cant think how to get around this? |
| 2015-09-05 10:50:50 -0600 | commented question | Node iterator missing first value when importing xml very good point, i had incorrectly written the printing function and it was starting from an incorrect position. Thank you for your help, my mistake |
| 2015-09-05 09:43:18 -0600 | commented question | Matching kmeans clusters generating non random sequence possibly, although i dont want to change too much at this stage if possible as hand in is within a couple of weeks. Do you think that could cause the sequence which it outputs? I know kmeans can have variations but the fact that the variations are the same each time seems to indicate that it's related to the number of iterations it runs, but i've reinitialised a new trainer each iteration. Do you think it's something to do with the iterations or the use of BOWTrainer? |
| 2015-09-03 09:20:34 -0600 | commented question | Node iterator missing first value when importing xml Hi yeah here's one of them |
| 2015-09-03 06:30:29 -0600 | asked a question | Node iterator missing first value when importing xml I'm currently saving a large map of histogram data to xml for use in a later part of my program. I've noticed that it is cutting off the first value when loading and instead adding an empty value at the end. A basic example is: The layout of my xml file below where i is a changing value: My import function is below: It seems like an iterator problem so would be likely be in the it1 loop which is skipping the first value but i'm not sure why.?? |
| 2015-09-02 13:00:38 -0600 | commented question | Matching kmeans clusters generating non random sequence is that for keypoint based approach, my implementation needs to use the MR8 filterbank, effectively recreating this With that method you call it three times to generate the textons then for both models and the novel image which are the same method except the model is a known class. |
| 2015-09-02 10:12:48 -0600 | commented question | Matching kmeans clusters generating non random sequence Yes absolutely texton and model generation happen and are saved seperately to xml files. There is variation in the models generated from the same image, (i've put this down in part to kmeans variation), but as it's stored that shouldn't affect the clustering. The main reason i found this bug was because when i changed the number of training images the results for the images changed(even if the ones i added were duplicates). I noticed this only happened to ones which were loaded after the duplicates. I generated a new instance of BOWTrainer for every new image to confirm it wasn't something carried over and the models stay the same so have run out of idea's of where to look.. This is the repo, the testing module is novelImgTest.cpp |
| 2015-09-02 08:17:50 -0600 | received badge | ● Self-Learner (source) |
| 2015-09-02 08:17:50 -0600 | received badge | ● Necromancer (source) |
| 2015-09-02 05:45:24 -0600 | asked a question | Matching kmeans clusters generating non random sequence I've been creating a bag of words based texture classifier using gaussian filterbanks. I've recently found a fairly fundamental flaw in that after i collect and save a set of 'model' histograms from training images, if i then generate another histogram from from one of the training images using an identical procedure and use compareHist with chisquared to match it doesn't give a perfect match but instead a set of seemingly random distances which reoccur exactly if it's the process is repeated from new. I've done this in a loop (generating a histogram and matching to a save histogram of the same image), and example of the distances comparehist throws back is below. {4,6,6,4,3,4,5,6,4,6,5,3,3,5,6,5,6,5,6,4,5,5,4,5,4,4,6,3,5} I cant understand why the distance:
I'm using the bag of words trainer to generate the clusters with KMEANS_PP_CENTERS being used to calculate the initial centres. Then comparing those clusters with chisquared. Is this something which could be due to my code or from the clustering? Thank you in advance this has been driving me crazy and my dissertation is due in a week and a half so stressful.. Note this is partial repost from my other post here but that's mainly because i need an answer pretty quick because it's holding up my project. Thanks Below is a basic example of the kmeans variation i'm talking about, although not my specific problem: Below is the resize function: This is my github, my specific problem is both the variation when i generate models ... (more) |
| 2015-09-02 05:31:06 -0600 | answered a question | Is it possible to create distinct Histogram bins from array for anyone looking at this, the solution i ultimately used, was just to use the non uniform bins input in the calcHist function. First i looked through and matched the input values to the nearest stored value. Then to generate the bin ranges i looped through the original values i wanted to match the new values to and simply added 0.00001 this acted as the upper exclusion limit putting any values which were above this in the next bin, as i knew all the possible values i didn't need to find the nearest as that was already done.
The above code isn't necessarily pretty but it works in case anyone has a similar problem. |
| 2015-08-18 15:14:24 -0600 | commented answer | Comparing KMeans centers for the best match Hi, yeah i'll be happy to do that when i get some more time, it's for my masters thesis so am rushing to finish it by september. |
| 2015-08-15 12:13:44 -0600 | answered a question | Comparing KMeans centers for the best match For anyone looking for an answer or hints on this or specifically about being able to cluster multiple images easily, the way i found was using parts of the Bag of Words classes in the c++ api for opencv.
specifically will allow you to push back as multiple Mat images easily and and then generate a set of cluster centers using:
Definitely better than messing around trying to cluster them with the traditional kmeans function. I haven't yet found a good solution to matching the cluster centres with the the generated vocabulary yet, as the other BOW opencv classes as far as i can tell wont work when using filterbanks. So i'll update it when i find something, otherwise you can check my current implementation on github: https://github.com/albertJ32/multiCha... |
| 2015-08-13 09:08:40 -0600 | received badge | ● Scholar (source) |
| 2015-07-24 11:01:00 -0600 | commented question | Is it possible to create distinct Histogram bins from array yeah i think something like that but being able to assign a collection of values to their nearest value in a seperate array. Is that possible with the mask parameter in normalize is? |
| 2015-07-24 08:47:12 -0600 | asked a question | Is it possible to create distinct Histogram bins from array Hi i'm currently trying to match a large set of values with a template array. I was looking to just display any of the values which perfectly matched the array in a frequency histogram. I've tried this so far with the cv:calcHist function using non-uniform bins and an input array roughly dividing the values into bins but was hoping there was a better way. Such as where you can designate the upper and lower bounds for all the bins as opposed to just the first bin, is this possible? or are there any other methods, outside of prefiltering values as the template values will likely change and taking care of this in a single histogram function would make things easier. Thanks in advance. |
| 2015-07-24 08:37:08 -0600 | commented answer | How to create a histogram from a table of values? not sure if this was what you were asking about with the bins but you can specify whether to have either uniform of custom bins, as a flag in the cv::calcHist method. Then you just input a float array with the lowest inclusive value(will be included), then all of the top exclusive boundaries of your bins(so that bin will not include values from that value). i.e: float exampleArray[] = {0, 100, 256}; So this will have two bins, the first from 0-99 and the second from 100-255. Also remember to input the correct number of bins and the non-uniform flag in the cv::calcHist method. Hope this helps you or others with similar problems. |
| 2015-07-24 08:30:16 -0600 | commented answer | k mean clustering of hsv histogram of frames of a video Hi the code im currently writing is doing something similar to this, should be done in 2 weeks in case you find it useful. Also i know it's messy ect.. will optimise it when i have everything working.. https://github.com/albertJ32/MR8-Filt... |
| 2015-07-18 11:33:06 -0600 | received badge | ● Supporter (source) |
| 2015-07-15 08:27:20 -0600 | commented question | Comparing KMeans centers for the best match thanks berak, yeah i meant to clean it up, although haven't found a good debugger for atom yet. -Interesting about kmeans, can i create a single set of clusters from several images, the pseudo code above give me an error about the matrix not being continuous. would a continuous matrix of several images give the same centers as if i blended the same images together and ran it through kmeans? -Also the key point, is there a way to find the nearest cluster centre for an image from a previous set of cluster centres? |
| 2015-07-14 15:32:53 -0600 | asked a question | Comparing KMeans centers for the best match I'm working on implementing the VZ classifier (http://www.robots.ox.ac.uk/~vgg/resea...), and am having problems creating the models. The first stage is to cluster a large number of filter responses to generate a texton dictionary, where every texton is a kmeans cluster center. Then i need to get filter responses from a test image then get a single kmeans cluster center from each response, marking what is the closest texton(archived cluster center) to the new center. Then i'll display or store a histogram showing which textons were used and how frequently from the training images filter responses. From what i've read labels seem promising, although i dont know i could input the whole texton database and work out which best fitted image. Below is small bit of code i was using to try feeding the centers from one kmeans into the labels for a second kmeans on the same image. I was hoping that this could compare the cluster centers and show they're the same. (seemed logical at the time, have been stuck on this for a while..). Any help would be really appreciated. Thanks! |
| 2015-07-08 12:18:04 -0600 | received badge | ● Editor (source) |
| 2015-07-08 12:16:24 -0600 | asked a question | how to identify excess includes I'm working on a relatively large piece of filterbank code and have managed to amass a large collection of headers many of which were for code which is no longer in the project. Is there any way or method outside of just trial and error to identify which ones are actually being used so i can speed up compilation? Also would just help to make the code a bit leaner. Thanks in advance! Albert Edit: i'm using atom 1.0.0 in case there are any good packages or snippets |
| 2015-07-06 03:31:48 -0600 | received badge | ● Student (source) |
| 2015-07-05 16:16:06 -0600 | asked a question | tutorial site down?? Hi i was just trying to do some tutorials tonight and haven't been able to get onto the opencv tutorials area (http://docs.opencv.org/doc/tutorials/...). Has anyone else had this problem? As far as i can tell the connection just times out, i've tried changing dns's though and have checked on (http://www.isitdownrightnow.com/) and it's saying it's down. Hope it's something small, is a really useful area! Thanks |
| 2015-06-09 10:06:01 -0600 | received badge | ● Enthusiast |
| 2015-06-07 17:19:23 -0600 | commented question | Create MR8 filterbank with open cv thanks for the fast replies, I've more fully defined my question as:
Thanks again for the help! Also @Guanta, thank you for the link, sadly i'm a C programmer at heart so i dont have python experience and haven't found any repo's for C++ code yet |
| 2015-06-04 11:51:16 -0600 | asked a question | Create MR8 filterbank with open cv Hi, I've been looking to implement the MR8 filterbank from http://www.robots.ox.ac.uk/~vgg/resea... with open cv but am still relatively new to it and haven't been able to find many details on how you create the edge or bar filters mentioned. I've gone through the computer vision tutorials on the open cv site but their 'filter 2d' method only allows for odd inputs not the odd and even dimensions required for the bar and edge MR8 filters especially. Is there a different method which is able to handle these or do i need to look at creating these filters another way? Any help would be really appreciated! |