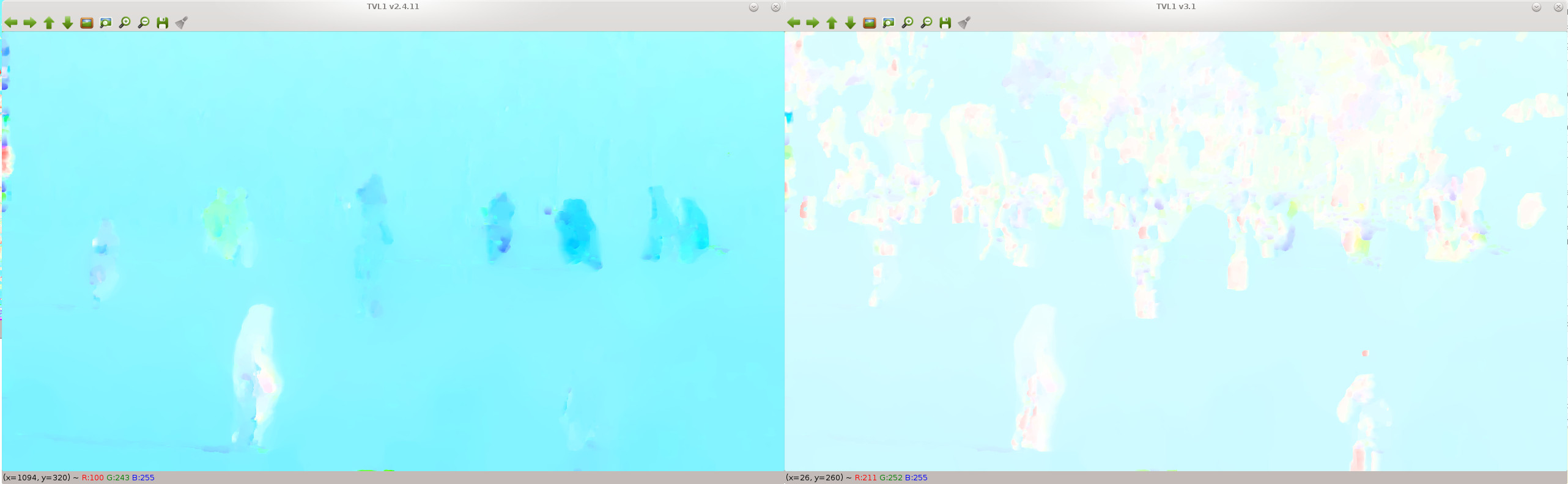
I see differences (some significant) in the Dual TVL1 optical flow algorithm between v2.4.11 and v.3.1. I was wondering if anyone has noticed the same problem, and had an explanation.
I've slightly modified the example code in samples/gpu/optical_flow.cpp. Specifically, I've replaced the hardcoded images to be compared (basketball1.png, pasketball2.png) with the ability to provide a video source file, and a frame # within that file (then consecutive frames are used as input).
I have visually inspected 2.4.11's modules/gpu/src/tvl1flow.cpp and 3.1's modules/cudaoptflow/src/tvl1flow.cpp and I dont see anything different (this is NOT the CUDA code).
I have noticed that in 2.4.11, the TVL1 and Bronx outputs are almost indistinguishable, but in 3.1 they are very different. Also in 2.4.11 TVL1 and Bronx runtimes are very close (on my machine ~.3s and .35s respectively), but in 3.1 they are a good deal different (~1.8s and .35s). The Bronx runtime remains the between opencv versions, but TVL1 is ~6x longer.
Might it be that in 2.4.11 the TVL1 was really running the Bronx algorithm "under the covers"???
Source Images:

TVL1 Difference. Left is 2.4.11, right is 3.1. Left looks just like Bronx, and for these images appears to be more accurate (subjectively)