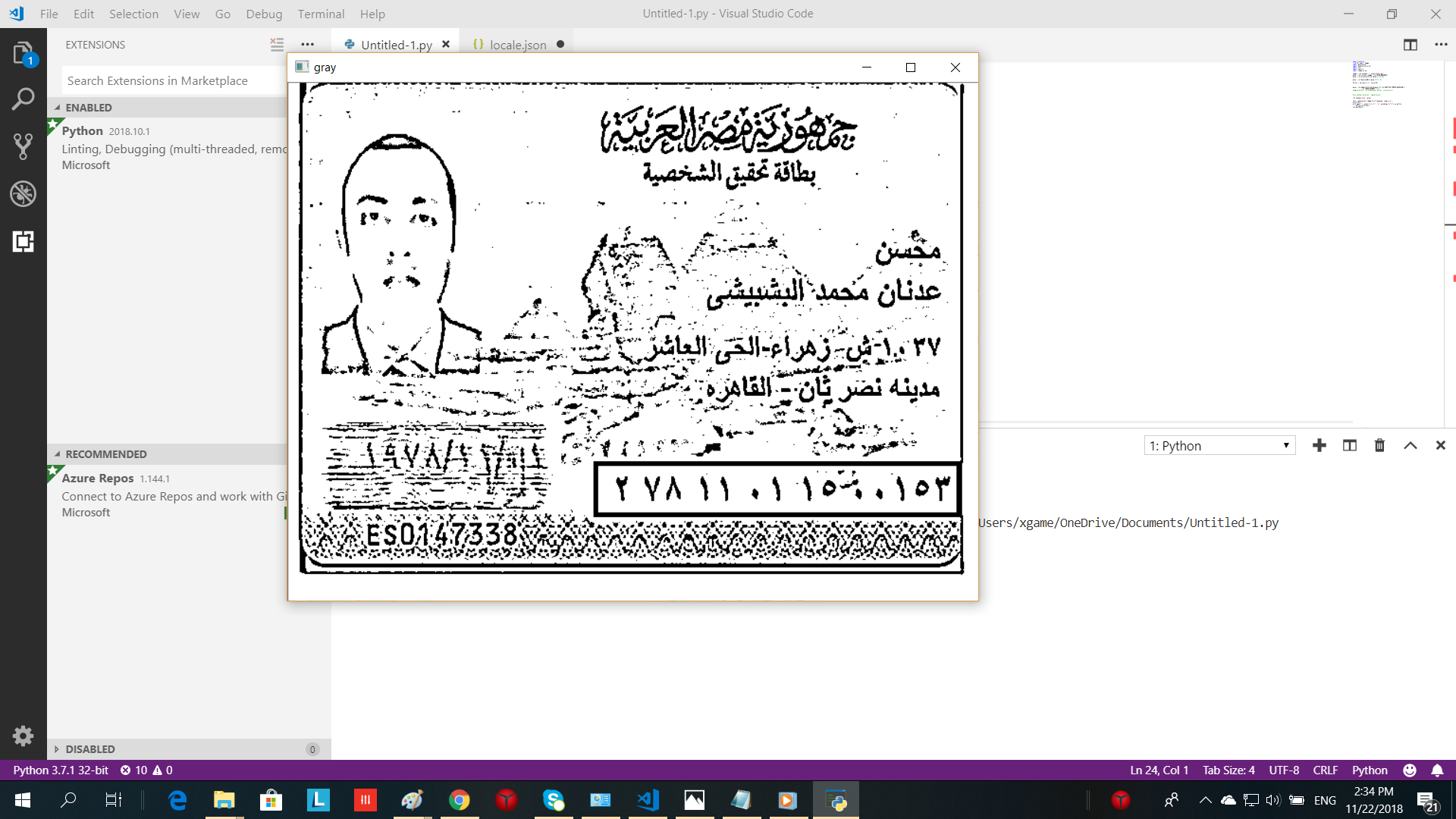
I'm trying to do OCR arabic on the following ID but I get a very noisy picture, and can't extract information from it.
Here is my attempt
import tesserocr
from PIL import Image
import pytesseract
import matplotlib as plt
import cv2
import imutils
import numpy as np
image = cv2.imread(r'c:\ahmed\ahmed.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.bilateralFilter(gray,11,18,18)
gray = cv2.GaussianBlur(gray,(5,5), 0)
kernel = np.ones((2,2), np.uint8)
gray = cv2.adaptiveThreshold(gray,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY,11,2)
#img_dilation = cv2.erode(gray, kernel, iterations=1)
#cv2.imshow("dilation", img_dilation)
cv2.imshow("gray", gray)
text = pytesseract.image_to_string(gray, lang='ara')
print(text)
with open(r"c:\ahmed\file.txt", "w", encoding="utf-8") as myfile:
myfile.write(text)
cv2.waitKey(0)