#include <iostream>
#include <sstream>
#include <string>
#include <vector>
#include <tclap/CmdLine.h>
#include <opencv2/core.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/ml/ml.hpp>
#include "common_code.hpp"
#define IMG_WIDTH 300
int
main(int argc, char * argv[])
{
TCLAP::CmdLine cmd("Trains and tests a BoVW model", ' ', "0.0");
TCLAP::ValueArg<std::string> basenameArg("b", "basename", "basename for the dataset.", false, "./data", "pathname");
cmd.add(basenameArg);
TCLAP::ValueArg<std::string> configFile("c", "config_file", "configuration file for the dataset.", false, "02_ObjectCategories_conf.txt", "pathname");
cmd.add(configFile);
TCLAP::ValueArg<int> n_runsArg("r", "n_runs", "Number of trials train/test to compute the recognition rate. Default 10.", false, 10, "int");
cmd.add(n_runsArg);
TCLAP::ValueArg<int> ndesc("", "ndesc", "[SIFT] Number of descriptors per image. Value 0 means extract all. Default 0.", false, 0, "int");
cmd.add(ndesc);
TCLAP::ValueArg<int> keywords("w", "keywords", "[KMEANS] Number of keywords generated. Default 100.", false, 100, "int");
cmd.add(keywords);
TCLAP::ValueArg<int> ntrain("", "ntrain", "Number of samples per class used to train. Default 15.", false, 15, "int");
cmd.add(ntrain);
TCLAP::ValueArg<int> ntest("", "ntest", "Number of samples per class used to test. Default 50.", false, 50, "int");
cmd.add(ntest);
TCLAP::ValueArg<int> k_nn("", "k_nn", "[KNN] Number k neighbours used to classify. Default 1.", false, 1, "int");
cmd.add(k_nn);
cmd.parse(argc, argv);
// --------------- MAIN BLOCK ---------------
std::vector<std::string> categories;
std::vector<int> samples_per_cat;
std::string dataset_desc_file = basenameArg.getValue() + "/" + configFile.getValue();
int retCode;
if ((retCode = load_dataset_information(dataset_desc_file, categories, samples_per_cat)) != 0)
{
std::cerr << "Error: could not load dataset information from '"
<< dataset_desc_file
<< "' (" << retCode << ")." << std::endl;
exit(-1);
}
std::cout << "Found " << categories.size() << " categories: ";
if (categories.size()<2)
{
std::cerr << "Error: at least two categories are needed." << std::endl;
return -1;
}
for (size_t i=0;i<categories.size();++i)
std::cout << categories[i] << ' ';
std::cout << std::endl;
std::vector<float> rRates(n_runsArg.getValue(), 0.0);
// Repeat training+test
for (int trial=0; trial<n_runsArg.getValue(); trial++)
{
std::clog << "######### TRIAL " << trial+1 << " ##########" << std::endl;
std::vector<std::vector<int>> train_samples;
std::vector<std::vector<int>> test_samples;
create_train_test_datasets(samples_per_cat, ntrain.getValue(), ntest.getValue(), train_samples, test_samples);
//-----------------------------------------------------
// TRAINING
//-----------------------------------------------------
std::clog << "Training ..." << std::endl;
std::clog << "\tCreating dictionary ... " << std::endl;
std::clog << "\t\tComputing descriptors..." << std::endl;
cv::Mat train_descs;
cv::Mat1f totalmat;
std::vector<int> ndescs_per_sample;
ndescs_per_sample.resize(0);
cv::Mat labels;
cv::Mat1f centers;
std::vector <cv::Mat> bovw;
for (size_t c = 0; c < train_samples.size(); ++c)
{
std::clog << " " << std::setfill(' ') << std::setw(3) << (c * 100) / train_samples.size() << " % \015";
for (size_t s = 0; s < train_samples[c].size(); ++s)
{
std::string filename = compute_sample_filename(basenameArg.getValue(), categories[c], train_samples[c][s]);
cv::Mat img = cv::imread(filename, cv::IMREAD_GRAYSCALE);
if (img.empty())
{
std::cerr << "Error: could not read image '" << filename << "'." << std::endl;
exit(-1);
}
else
{
// Fix size: width =300px
//! \todo TO BE COMPLETED
cv::Size size(300,300*img.rows/300*img.cols);
resize(img,img,size);
// Extract SIFT descriptors
//-----------------------------------------------------
cv::Mat1f descs;
descs = extractSIFTDescriptors(img, ndesc.getValue()); //devuelve una matriz de 100 filas y 128 columnas
if (c==0 and s==0) //Para evitar que en la primera no
descs.copyTo(totalmat);
else
cv::vconcat(totalmat,descs,totalmat);//Concatenamos todas las matrices con los puntos caracteristicos.
bovw.push_back(descs); //Gurdamos cada imagen por separado en un vector de imagenes
}
}
}
std::clog << std::endl;
// Dictionary computation
//-----------------------------------------------------
std::clog << "\tGenerating " << keywords.getValue() << " keywords ..." << std::endl;
//! \todo kMeans clustering
cv::kmeans(totalmat,keywords.getValue(), labels,cv::TermCriteria( cv::TermCriteria::EPS+cv::TermCriteria::COUNT, 10, 1.0),n_runsArg.getValue(), cv::KMEANS_PP_CENTERS, centers);
std::cerr << "Hasta aqui " <<std::endl;
cv::Ptr <cv::ml::KNearest> KNN=cv::ml::KNearest::create();
//centers almacena los valores de los centroides en cada fila
std::vector<float> etiquetas;//creo un vector donde ire guardando cada una de las etiquetas de centers
KNN->train(centers,cv::ml::ROW_SAMPLE,etiquetas);
KNN->save("diccionario.yml");
// Compute BoVW for each image
//-----------------------------------------------------
std::clog << "\tComputing BoVW ... " << std::endl;
//For each train image, compute the corresponding bovw.
std::clog << "\t\tGenerating a bovw descriptor per training image." << std::endl;
//! \todo TO BE COMPLETED
// Define the classifier type and train it
//-----------------------------------------------------
//! \todo TO BE COMPLETED
//-----------------------------------------------------
// TESTING
//-----------------------------------------------------
std::clog << "Testing .... " << std::endl;
//load test images, generate SIFT descriptors and quantize getting a bovw for each image.
//classify and compute errors.
std::vector<float> true_labels;
//For each test image, compute the corresponding bovw.
std::clog << "\tCompute image descriptors for test images..." << std::endl;
cv::Mat test_bovw;
//! \todo TO BE COMPLETED
std::clog << "\tThere are " << test_bovw.rows << " test images." << std::endl;
//Classify the test samples.
std::clog << "\tClassifing test images." << std::endl;
cv::Mat predicted_labels;
//compute the classifier's confusion matrix.
std::clog << "\tComputing confusion matrix." << std::endl;
cv::Mat confusion_mat = compute_confusion_matrix(categories.size(), cv::Mat(true_labels), predicted_labels);
CV_Assert(int(cv::sum(confusion_mat)[0]) == test_bovw.rows);
double rRate_mean, rRate_dev;
compute_recognition_rate(confusion_mat, rRate_mean, rRate_dev);
std::cerr << "Recognition rate mean = " << rRate_mean * 100 << "% dev " << rRate_dev * 100 << std::endl;
rRates[trial]=rRate_mean;
}
//Saving the best models: dictionary and classifier, format YML
//! \todo TO BE COMPLETED
std::clog << "###################### FINAL STATISTICS ################################" << std::endl;
double rRate_mean = 0.0;
double rRate_dev = 0.0;
//! \todo TO BE COMPLETED
std::clog << "Recognition Rate mean " << rRate_mean*100.0 << "% dev " << rRate_dev*100.0 << std::endl;
return 0;
}
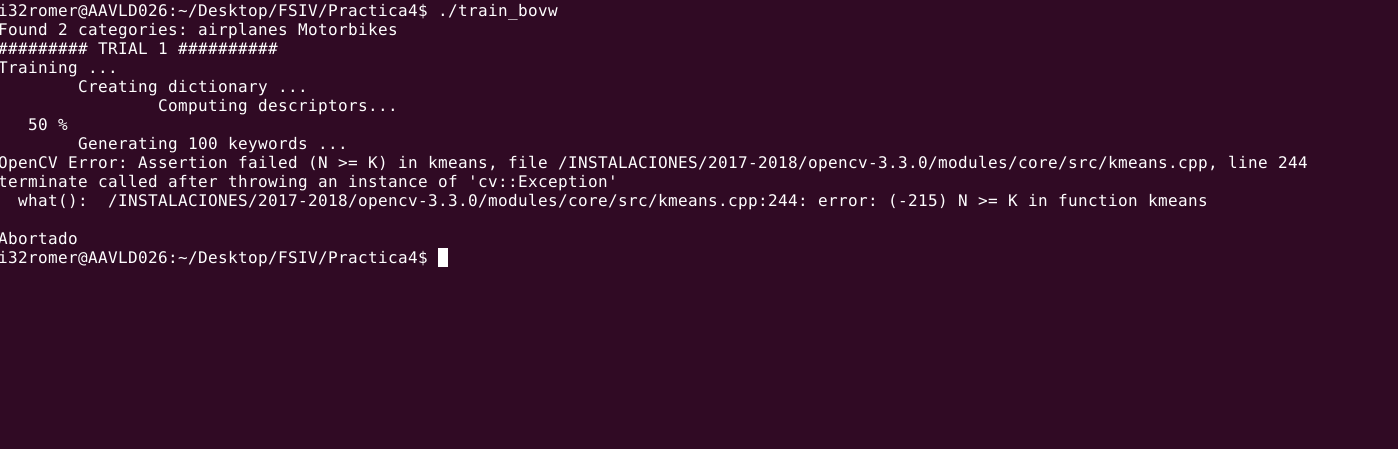
That is my mistake. I've been looking for the fault for several hours and I can not find anything. I think my cv :: vconcat does not work well. Can someone help me ?. a greeting