This problem only happens for UMat arguments, and only if us OpenCl is switched on as well.
I am guessing that the program is running out of GPU memory. This is apparently not supposed to be possible because the driver can do virtual memory. An alternative explanation is that TDR is the cause, but the computer doesn't freeze at any time so I don't think this is it.
Of course in the real program I will shrink the large images down before template matching, but since my program is for doing batches, I hope to call matchTemplate from a few windows threadpool threads to try and get higher throughput anyway. This also causes the crash. OpenCl gives us no way of getting the amount of free video memory, so I was thinking of making the number of parallel matchTemplate calls as a function of the total GPU memory amount.
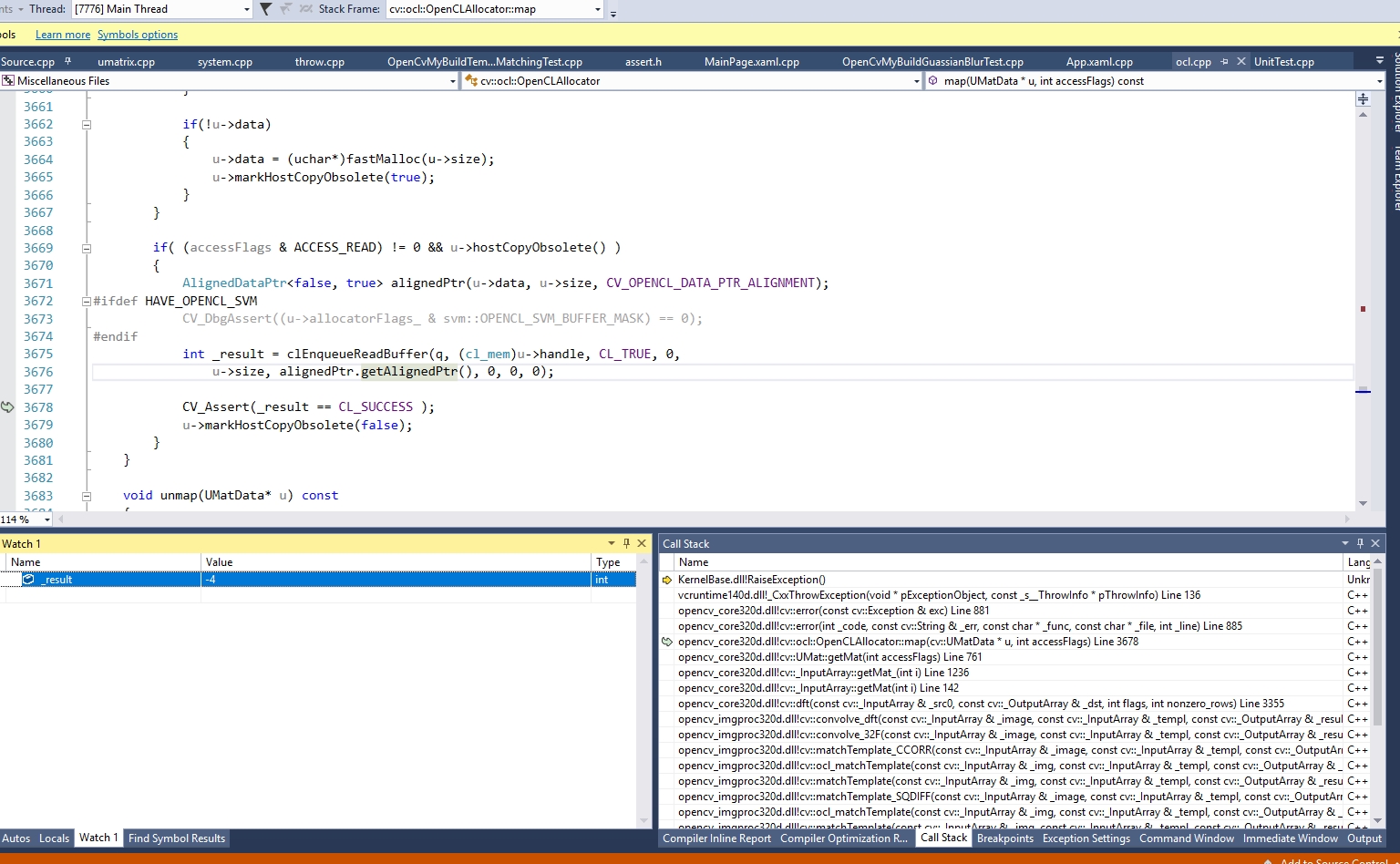
The error comes out of clEnqueueReadbuffer, which returns -4 (CL_MEM_OBJECT_ALLOCATION_FAILURE);
Some code:
// OpenCvMyBuildTemplateMatchingTest.cpp : Defines the entry point for the console application.
//
#include "stdafx.h"
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/core/ocl.hpp>
#include <iostream>
#include <chrono>
#include <conio.h>
using namespace std::chrono;
milliseconds DoMatTemplateMatching();
milliseconds DoUMatTemplateMatching();
void ContinuousUMatTemplateMatching();
cv::String PatchUri = "patch.bmp";
cv::String PictureUri = "notpatch.bmp";
int _numberOfTimesToRun = 32;
bool _useOpenCl = true;
int main()
{
milliseconds _totalMatElapsed = milliseconds::zero();
milliseconds _totalUMatElapsed = milliseconds::zero();
cv::ocl::setUseOpenCL(_useOpenCl);
for (int i = 0; i<_numberOfTimesToRun; i++)
{
_totalUMatElapsed += DoUMatTemplateMatching();
}
std::cout << "\n";
std::cout << "\nUMAT template matching took " << _totalUMatElapsed.count() << " milliseond for " <<
_numberOfTimesToRun << " runs.\n";
std::cout << "\n";
for (int i = 0; i < _numberOfTimesToRun; i++)
{
_totalMatElapsed += DoMatTemplateMatching();
}
std::cout << "\n";
std::cout << "\nMAT template matching took " << _totalMatElapsed.count() << " milliseond for " <<
_numberOfTimesToRun <<" runs.\n";
std::cout << "\n";
cv::ocl::setUseOpenCL(false);
for (int i = 0; i<_numberOfTimesToRun; i++)
{
_totalUMatElapsed += DoUMatTemplateMatching();
}
std::cout << "\n";
std::cout << "\nUMAT without OpenCl template matching took " << _totalUMatElapsed.count() << " milliseond
for " << _numberOfTimesToRun << " runs.\n";
std::cout << "\n";
getch();
return 0;
}
milliseconds DoMatTemplateMatching()
{
cv::Mat _picture = cv::imread(PictureUri);
cv::Mat _patch = cv::imread(PatchUri);
cv::Mat _result;
milliseconds _startTime = duration_cast< milliseconds >(system_clock::now().time_since_epoch());
cv::matchTemplate(_picture, _patch, _result, 0);
milliseconds _endTime = duration_cast< milliseconds >(system_clock::now().time_since_epoch());
milliseconds _deltaTime = _endTime - _startTime;
return _deltaTime;
}
milliseconds DoUMatTemplateMatching()
{
cv::Mat _picture = cv::imread(PictureUri);
cv::Mat _patch = cv::imread(PatchUri);
milliseconds _startTime = duration_cast< milliseconds >(system_clock::now().time_since_epoch());
/// need to convert to greyscale or else get that error:
cv::cvtColor(_picture, _picture, CV_BGR2GRAY);
cv::cvtColor(_patch, _patch, CV_BGR2GRAY);
cv::UMat _uPicture = _picture.getUMat(cv::ACCESS_READ);
cv::UMat _uPatch = _patch.getUMat(cv::ACCESS_READ);
assert(_uPatch.type() == _uPicture.type());
std::cout << _uPatch.type();
cv::UMat _result;
cv::matchTemplate(_uPicture, _uPatch, _result, CV_TM_SQDIFF);
milliseconds _endTime = duration_cast< milliseconds >(system_clock::now().time_since_epoch());
milliseconds _deltaTime = _endTime - _startTime;
_picture.release();
_patch.release();
return _deltaTime;
}
void ContinuousUMatTemplateMatching()
{
while (true)
{
std::cout << "\n" << DoUMatTemplateMatching().count() << "\n";
}
}
The images I used in the above test: https://drive.google.com/file/d/0B_LsZxeKoN9eckZpSGdCN2tuNU0/view?usp=sharing https://drive.google.com/file/d/0B_LsZxeKoN9edlI5WUZxeVZTalk/view?usp=sharing
Some system info:
Number of platforms 1
Platform Name NVIDIA CUDA
Platform Vendor NVIDIA Corporation
Platform Version OpenCL 1.2 CUDA 8.0.0
Platform Profile FULL_PROFILE
Platform Extensions cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_khr_fp64 cl_khr_byte_addressable_store cl_khr_icd cl_khr_gl_sharing cl_nv_compiler_options cl_nv_device_attribute_query cl_nv_pragma_unroll cl_nv_d3d10_sharing cl_khr_d3d10_sharing cl_nv_d3d11_sharing cl_nv_copy_opts cl_nv_create_buffer
Platform Extensions function suffix NV
Platform Name NVIDIA CUDA
Number of devices 1
Device Name GeForce GT 610
Device Vendor NVIDIA Corporation
Device Vendor ID 0x10de
Device Version OpenCL 1.1 CUDA
Driver Version 382.33
Device OpenCL C Version OpenCL C 1.1
Device Type GPU
Device Available Yes
Device Profile FULL_PROFILE
Device Topology (NV) PCI-E, 01:00.0
Max compute units 1
Max clock frequency 1620MHz
Compute Capability (NV) 2.1
Max work item dimensions 3
Max work item sizes 1024x1024x64
Max work group size 1024
Compiler Available Yes
Preferred work group size multiple 32
Warp size (NV) 32
Preferred / native vector sizes
char 1 / 1
short 1 / 1
int 1 / 1
long 1 / 1
half 0 / 0 (n/a)
float 1 / 1
double 1 / 1 (cl_khr_fp64)
Half-precision Floating-point support (n/a)
Single-precision Floating-point support (core)
Denormals Yes
Infinity and NANs Yes
Round to nearest Yes
Round to zero Yes
Round to infinity Yes
IEEE754-2008 fused multiply-add Yes
Support is emulated in software No
Correctly-rounded divide and sqrt operations No
Double-precision Floating-point support (cl_khr_fp64)
Denormals Yes
Infinity and NANs Yes
Round to nearest Yes
Round to zero Yes
Round to infinity Yes
IEEE754-2008 fused multiply-add Yes
Support is emulated in software No
Correctly-rounded divide and sqrt operations No
Address bits 64, Little-Endian
Global memory size 1073741824 (1024MiB)
Error Correction support No
Max memory allocation 268435456 (256MiB)
Unified memory for Host and Device No
Integrated memory (NV) No
Minimum alignment for any data type 128 bytes
Alignment of base address 4096 bits (512 bytes)
Global Memory cache type Read/Write
Global Memory cache size 16384 (16KiB)
Global Memory cache line size 128 bytes
Image support Yes
Max number of samplers per kernel 16
Max 2D image size 16384x16384 pixels
Max 3D image size 2048x2048x2048 pixels
Max number of read image args 128
Max number of write image args 8
Local memory type Local
Local memory size 49152 (48KiB)
Registers per block (NV) 32768
Max constant buffer size 65536 (64KiB)
Max number of constant args 9
Max size of kernel argument 4352 (4.25KiB)
Queue properties
Out-of-order execution Yes
Profiling Yes
Profiling timer resolution 1000ns
Execution capabilities
Run OpenCL kernels Yes
Run native kernels No
Kernel execution timeout (NV) No
Concurrent copy and kernel execution (NV) Yes
Number of async copy engines 1
Device Extensions cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_khr_fp64 cl_khr_byte_addressable_store cl_khr_icd cl_khr_gl_sharing cl_nv_compiler_options cl_nv_device_attribute_query cl_nv_pragma_unroll cl_nv_d3d10_sharing cl_khr_d3d10_sharing cl_nv_d3d11_sharing cl_nv_copy_opts cl_nv_create_buffer