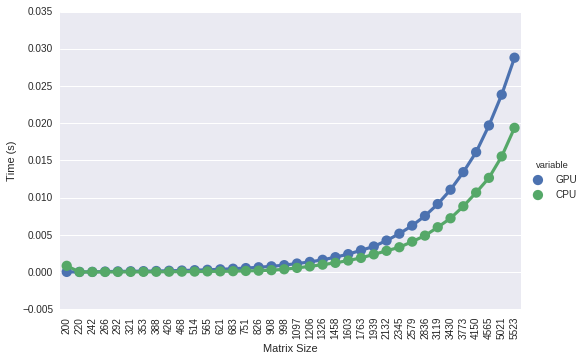
Hi, I used the following code to compare execution time between CPU and GPU versions of scaleAdd. I am in Ubuntu 16.04, cuda 8.0, 740M card, and core i7 5th gen in my laptop.
However, the results I get is that the CPU version is always faster.
Could you execute the code and provide me your results with machine configuration?
I compile with
OPENCV_LIBPATH=/usr/local/lib
OPENCV_LIBS=`pkg-config opencv --cflags --libs`
g++ -c scaleAdd.cpp -Wall -Wextra -m64 -lm -L$(OPENCV_LIBPATH) $(OPENCV_LIBS)
#include <opencv2/core.hpp>
#include "opencv2/cudaarithm.hpp"
#include <iostream>
using namespace std;
class Timer
{
private:
double tick;
public:
Timer()
{
}
void tic()
{
tick = (double)cv::getTickCount();
}
double toc()
{
return ((double)cv::getTickCount() - tick)/cv::getTickFrequency();
}
};
int main()
{
size_t LOOPS = 100;
size_t MAX_SIZE=6000;
Timer clock;
float filter= 1;
cv::cuda::GpuMat buffer;
cv::cuda::GpuMat result;
cout<< "Time in ms" << endl;
cout<< "N,BW(GBS),GPU,CPU"<< endl;
for (size_t N=200; N<MAX_SIZE; N*=1.1)
{
//setup buffer
cv::Mat h_buffer = cv::Mat::ones(N, N, CV_32FC1);
cv::Mat h_result = cv::Mat::ones(N, N, CV_32FC1);
clock.tic();
buffer.upload(h_buffer);
double bw = N*N*32.0/8.0/clock.toc()/1e9;
result.upload(h_result);
clock.tic();
for (size_t i=0; i<LOOPS; i++)
cv::cuda::scaleAdd(buffer, filter, result, result);
double gpu = clock.toc()/(double)LOOPS;
clock.tic();
for (size_t i=0; i<LOOPS; i++)
cv::scaleAdd(h_buffer, filter, h_result, h_result);
double cpu = clock.toc()/(double)LOOPS;
cout<< N << "," << bw << "," << gpu << "," << cpu << endl;
}
}