Hand Posture Recognition using Machine Learning

Hey guys,
I am currently working on my thesis and for that I am trying to recognize different hand postures for controlling an embedded system. My first implementation used simple skin color segmentation, calculation of contours, convex hull, defects and so on. This works, but I am not satisfied, since it is not very robust. This approach also detects other skin colored objetcs and I don't want to compute all these things every frame.
Because of that I started to think about machine learning algorithms. I thought about using a Support Vector Machine for my task. My problem is that I don't really know what to use. Is a SVM a good choice for hand posture recognition or is another machine learning algorithm more appropriate? I am also unsure about what features to use for training my model. Currently I use SURF-Features, since SIFT is to slow. Are other features more suitable? And my last problem is the training set. What kind of images do I need to train my model?
So my questions are:
Is a Support Vector Machine a good choice for hand posture recognition?
What are good features to train the model?
- What kind of images do I need for my training? How many for each class? Grayscale, Binary, Edges?
I know that these are no specific questions, but there is so many literature out there and I need some advide where to look at.
I am working with the OpenCV Python Bindings for my image processing and use the scikit package for the machine learning part.
EDIT
@Pedro Batista, first of all thank you very much for your detailed answer, I really appreciate that. The system should run in a laboratory environment. So the user has to interact with different devices and should be able to control some of these devices by hand postures/gestures. The background might be stable, but it is no simple white/black background. For the moment I assume that the user places his hand close in front of the camera.
Yesterday I made a minimal example with a SVM. I took some sample images of three different hand postures (Open Hand, Fist and two fingers). I took only 20 images for every posture of size 320*240. The size and distance of the hand was nearly the same in every image.
After that I segmented the hand by simple threshold in the YCrCb color space and performed some smoothing and opening/closing operations. By calculating the biggest contour (which I assume is the hand) I got two features, the area of the contour and the perimeter. Calculating more features should be no problem, like convexity defects, angles and so on. I used these two features to train my SVM and got the following classification (area on the x axis and perimeter on the y axis).
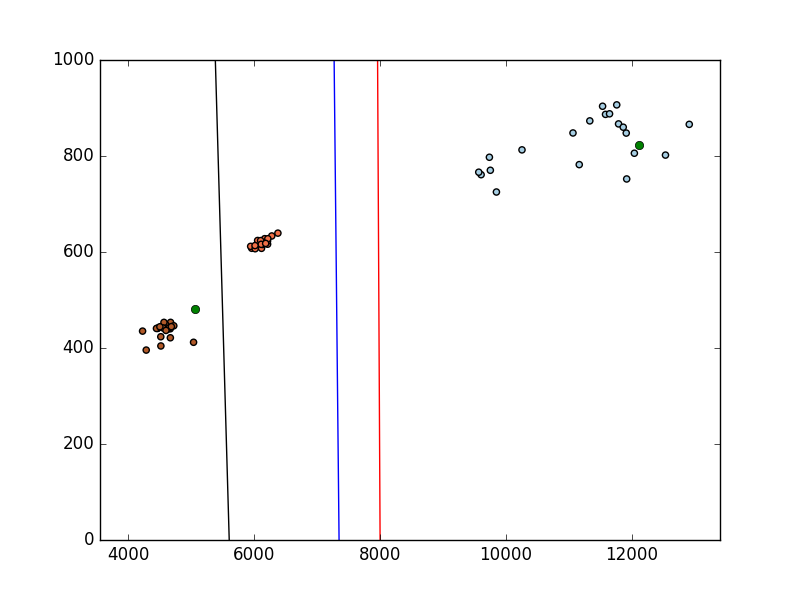
So in this case the simple classification works quite well, but at the moment I just worked with an idealized situation. For the moment ...

As you can tell by that plot, using SVM to classify your Area/Perimeter data is overkilling the problem, even though it is a good simple way to figure out how SVM works. You can classify that data using simple heuristic (if statements). ML will become useful when feature space becomes so big that you can't interpret it yourself and need a machine to do it for you.
k-Nearest Neighbours is the simplest ML because it actually doesn't compute a model to classify data. To classify a unlabelled sample, it goes through all the labelled train data and finds the samples that are the most similar to the one being classified.
The only parameter is k, which is the number of votes needed to classify each sample. If k=15, the algorithm will find the 15 closest samples and each then each label will represent a vote to identify the class.