OpenCV 3.1 CUDA 7.5 detectMultiScale function works slower on GPU then CPU
Good Day!
My question would be, that i'm currently trying to optimize my C++ program for GPU. My PC (relevant part):
- Geforce GTX 780
- I5-6600K
- Corsair vengeance 2.6GHZ memory 16GB
My code is pretty big, because it's connected with an AI, and i also use Landmark detection aswell, so now i will post only the relevant part of the code. Basictly my problem is, then every settings how i try gives slower results on GPU then CPU.
My code:
double cascade_ScaleFactor=1.2;
cascade_MinNumberNeighbor=3;
void facedetector(cv::Mat& frame, BufferFaceGPU& b)
{
double processT,processT_total;
/****************************/
/***********GPU**************/
/****************************/
if (GPUx==1){
/***********VERSION 1.0 OLD*************/
cascade_gpu->setMinObjectSize(cascadeMinSize);
cascade_gpu->setMaxObjectSize(cascadeMaxSize);
processT_total = (double)cv::getTickCount();
std::vector<Rect> faces;
cv::Mat cpu_frame_gray;
processT = (double)cv::getTickCount();
b.gpu_frame.upload(frame);
processT = (double)cv::getTickCount() - processT;
processT /= (double)cv::getTickFrequency();
read_write_data_tofile("GPU_data_upload.txt", processT);
processT = (double)cv::getTickCount();
cv::cuda::cvtColor(b.gpu_frame, b.gpu_frame, CV_BGR2GRAY);
processT = (double)cv::getTickCount() - processT;
processT /= (double)cv::getTickFrequency();
read_write_data_tofile("GPU_data_cvtColor.txt", processT);
processT = (double)cv::getTickCount();
cv::cuda::equalizeHist(b.gpu_frame, b.gpu_frame);
processT = (double)cv::getTickCount() - processT;
processT /= (double)cv::getTickFrequency();
read_write_data_tofile("GPU_data_equalizeHist.txt", processT);
processT = (double)cv::getTickCount();
cascade_gpu->detectMultiScale(b.gpu_frame, b.gpu_faces);
processT = (double)cv::getTickCount() - processT;
processT /= (double)cv::getTickFrequency();
read_write_data_tofile("GPU_data_detectMultiScale.txt", processT);
processT = (double)cv::getTickCount();
cascade_gpu->convert(b.gpu_faces, faces);
processT = (double)cv::getTickCount() - processT;
processT /= (double)cv::getTickFrequency();
read_write_data_tofile("GPU_data_convert.txt", processT);
processT = (double)cv::getTickCount();
b.gpu_frame.download(cpu_frame_gray);
processT = (double)cv::getTickCount() - processT;
processT /= (double)cv::getTickFrequency();
read_write_data_tofile("GPU_data_download.txt", processT);
if (!faces.empty())
{
processT = (double)cv::getTickCount();
get_landmarks(faces, cpu_frame_gray, frame);
processT = (double)cv::getTickCount() - processT;
processT /= (double)cv::getTickFrequency();
read_write_data_tofile("GPU_data_getLandmarks.txt", processT);
}
processT_total = (double)cv::getTickCount() - processT_total;
processT_total /= (double)cv::getTickFrequency();
read_write_data_tofile("GPU_data_total.txt", processT_total);
}
/****************************/
/***********CPU**************/
/****************************/
else if(GPUx==2){
cv::Mat frame_gray;
std::vector<Rect> faces;
processT_total = (double)cv::getTickCount();
processT = (double)cv::getTickCount();
cv::cvtColor(frame, frame_gray, CV_BGR2GRAY);
processT = (double)cv::getTickCount() - processT;
processT /= (double)cv::getTickFrequency();
read_write_data_tofile("CPU_data_cvtColor.txt", processT);
processT = (double)cv::getTickCount();
cv::equalizeHist(frame_gray, frame_gray);
processT = (double)cv::getTickCount() - processT;
processT /= (double)cv::getTickFrequency();
read_write_data_tofile("CPU_data_equalizeHist.txt", processT);
processT = (double)cv::getTickCount();
face_cascade.detectMultiScale(frame_gray, faces, cascade_ScaleFactor, cascade_MinNumberNeighbor, 0 | CV_HAAR_SCALE_IMAGE, cascadeMinSize,cascadeMaxSize);
processT = (double)cv::getTickCount() - processT;
processT /= (double)cv::getTickFrequency();
read_write_data_tofile("CPU_data_detecetMultiScale.txt", processT);
if (!faces.empty())
{
processT = (double)cv::getTickCount();
get_landmarks(faces, frame_gray, frame);
processT = (double)cv::getTickCount() - processT;
processT /= (double)cv::getTickFrequency();
read_write_data_tofile("CPU_data_getLandmarks.txt", processT);
}
processT_total = (double)cv::getTickCount() - processT_total;
processT_total /= (double)cv::getTickFrequency();
read_write_data_tofile("CPU_data_total.txt", processT_total);
}
else{
errormsg("Something went wrong!\nEXIT");
}
}
Sorry for the long code. I tried a bunch of optimalization (e.g. the max and min size is in a PID controller, and it's alwasy have to search for just a reasenable size of faces).
I'm monitoring the FPS and the process times also, and get almost a 1/4 of the CPU processed FPS.
My results in monitoring is just like that:
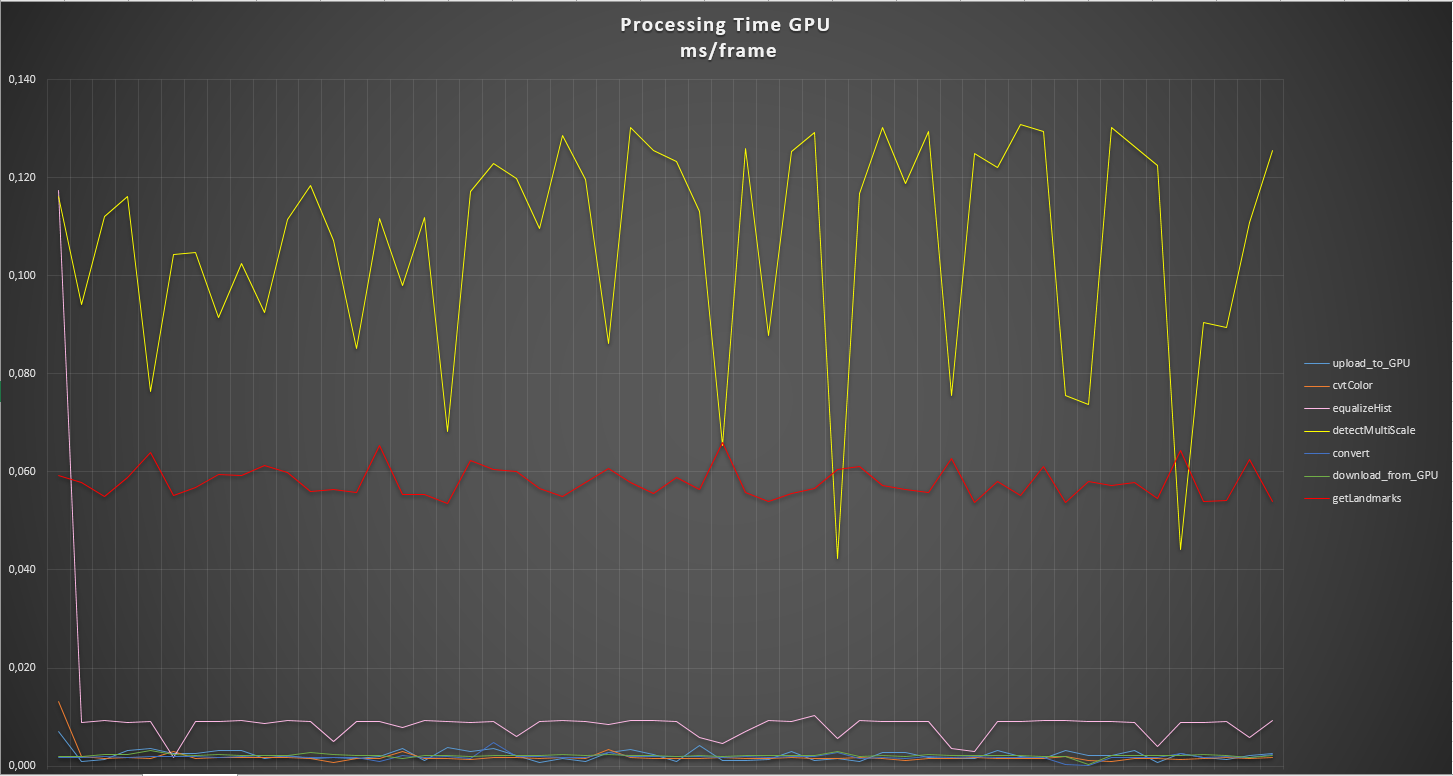
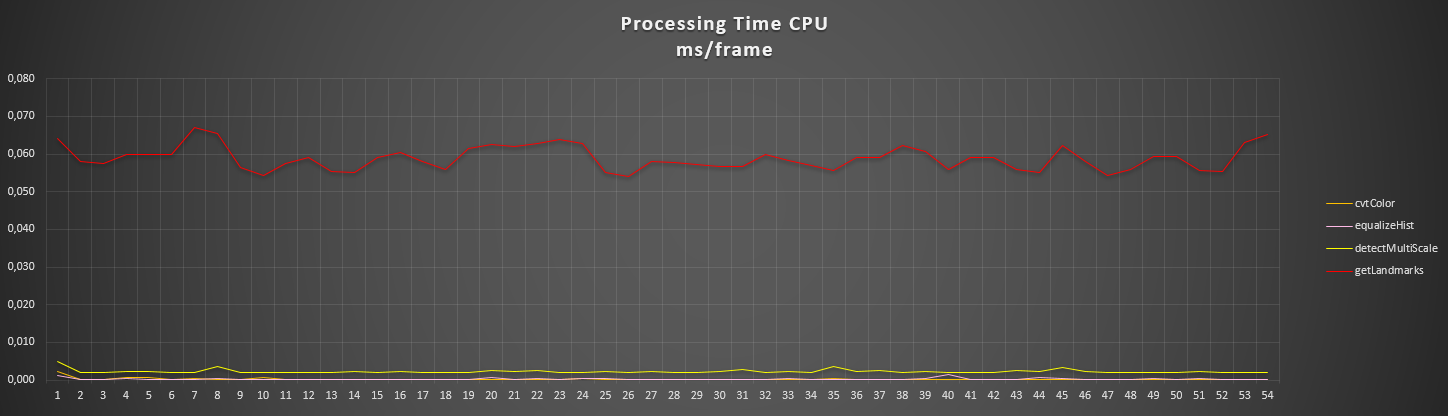
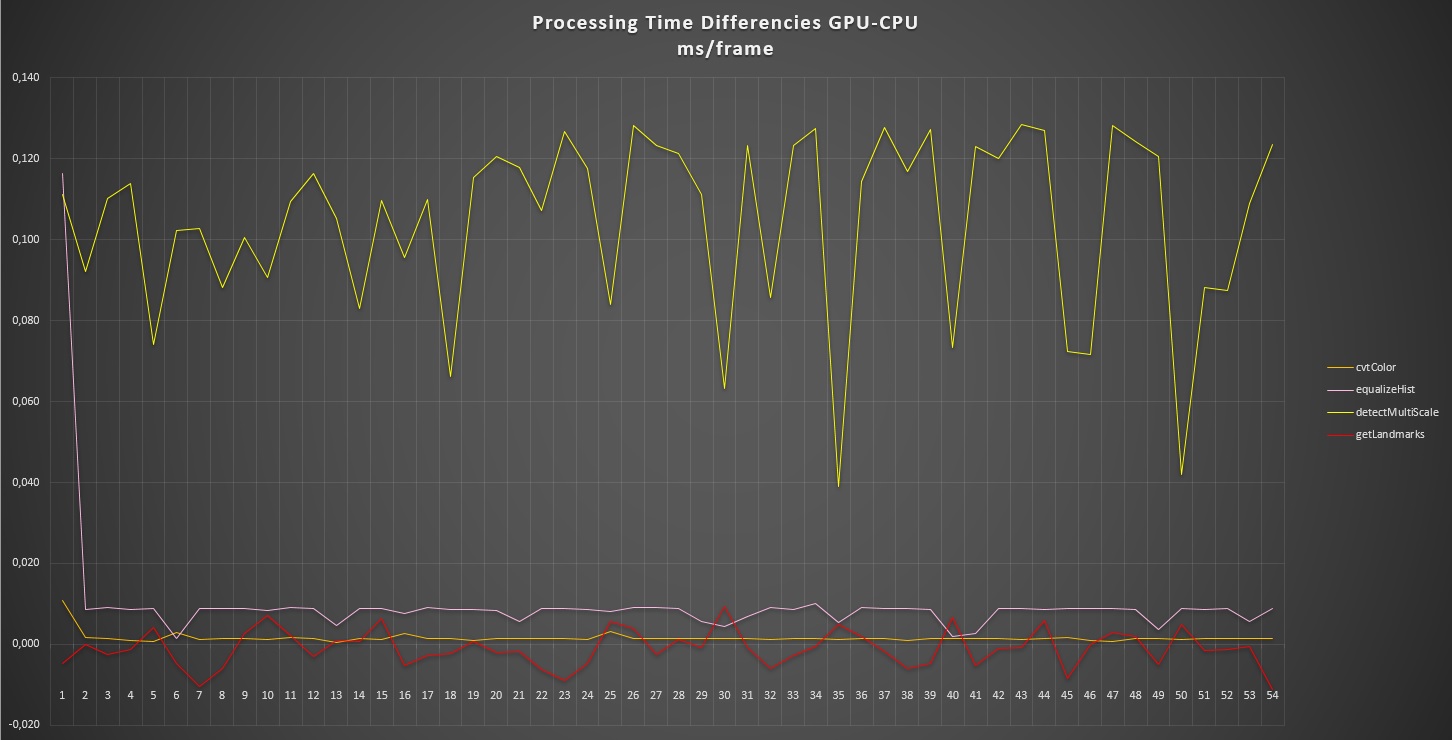
On the last picture you can clearly see that ...
I'm not even sure that i'm running my build correctly. I'm just building an exe, then running it.
What is the size of your image?
I observed a similar behavior with my own test (
haarcascade_frontalface_alt2.xml, 1280x720, minSize=40x40, maxSize=400x400, scaleFactor=1.2, minNeighbors=3): image result.The GPU time is the time to upload an RGB frame, convert it to gray, detect and get the result.
The CPU time is the time to detect an RGB frame (the conversion is done internally I suppose).
I'm working with full HD video/camera input. So my picture is 1920*1080, but i tested it with smaller videos also (same result). This is my settings:
The Min and Max scale is dynamicly adjusting in 10 frame for the detected face size.
Like that. And generally my faces on the full HD video are between 300x300 and 500x500 px.
This is expected behaviour I am afraid and is due to the following things
I have done similar experiments with large panoramic images and noticed that processing larger images on GPU was about 45x times slower than running it on a TBB optimized 24core CPU...
Thank you for your answer!
Actually i was thinking the same, while trying to optimize the process. I watched also while running the program that all of my 4 cores are working on 70-80%. But the funny thing was that i wrote a seqential program, so i though maybe its optimized automaticly with TBB or something like that. So i had a feeling about that and now according to you, it's true. :) (The funny thing, as i remember i didn't enable TBB on Cmake, maybe only the "with TBB" section, but i'm pretty sure that i set disable the "Build TBB" part.)
Do you know a different process maybe in openCV, what is optimized more on GPU for face detection?
Ow with_tbb takes your system tbb installation, while build_tbb builds a tbb version shipped with OpenCV from scratch. So actually the with is enough to enable the support.