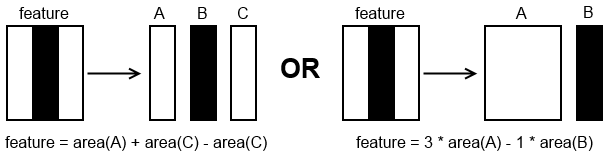
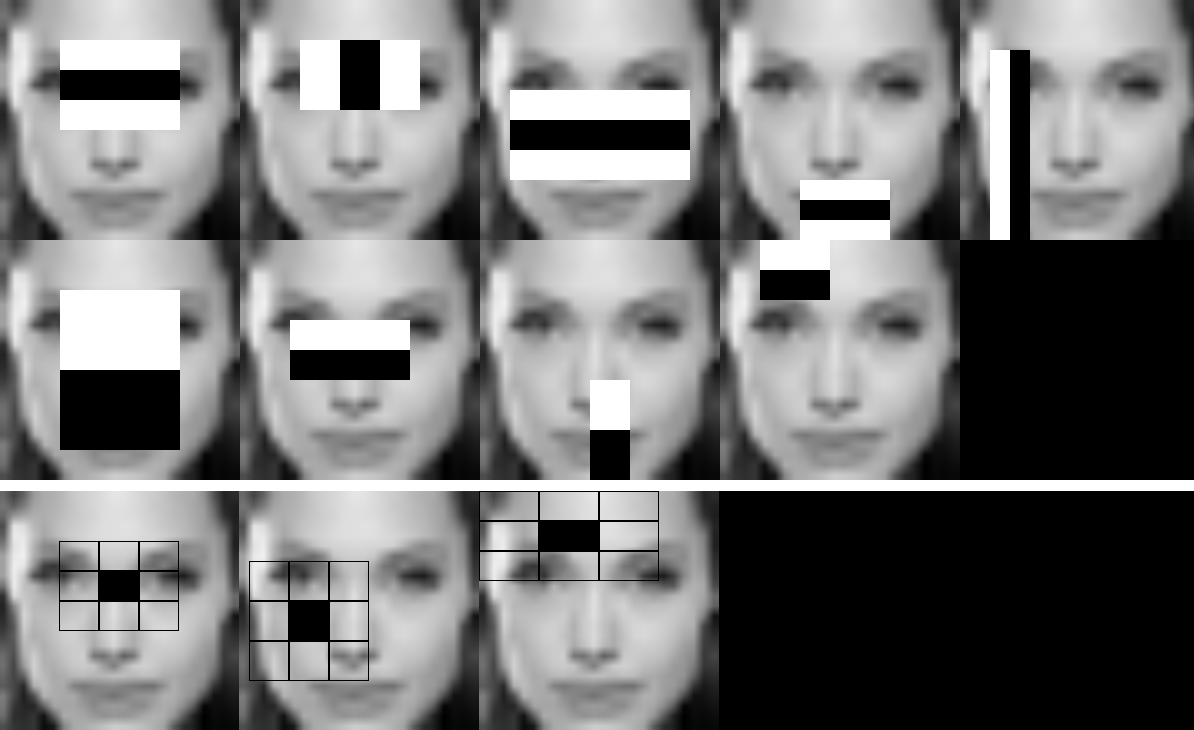How the 3 basic Haar features are formed from the Haar wavelet ?

I have been digging a lot and to this point I know exactly how Viola-Jones algorithm works and how the haar cascade file is prepared. I am more interested in knowing the fact that how the 3 basic haar features are formed, and how they are derived using the haar wavelet, and why only that specific three ?
add a comment