Ideas for separating LDA clusters to improve SVM accuracy?
I've been trying to classify some tags (each tag is a 24*24 pixel image) that I have on the backs of insects. There are 3 tag types: circle (O), rectangle (I) and Queen (Q). There's also a fourth tag type: unknown (U) because sometimes the angle that the tags are extracted at or the lighting mean that it isn't possible to tell what type of tag it is. There's quite a bit of variation in lighting and tag quality too, which you can see in the image below (image 7.png is actually a rectangle that's a little bit blurry although in the image I said it was unknown):

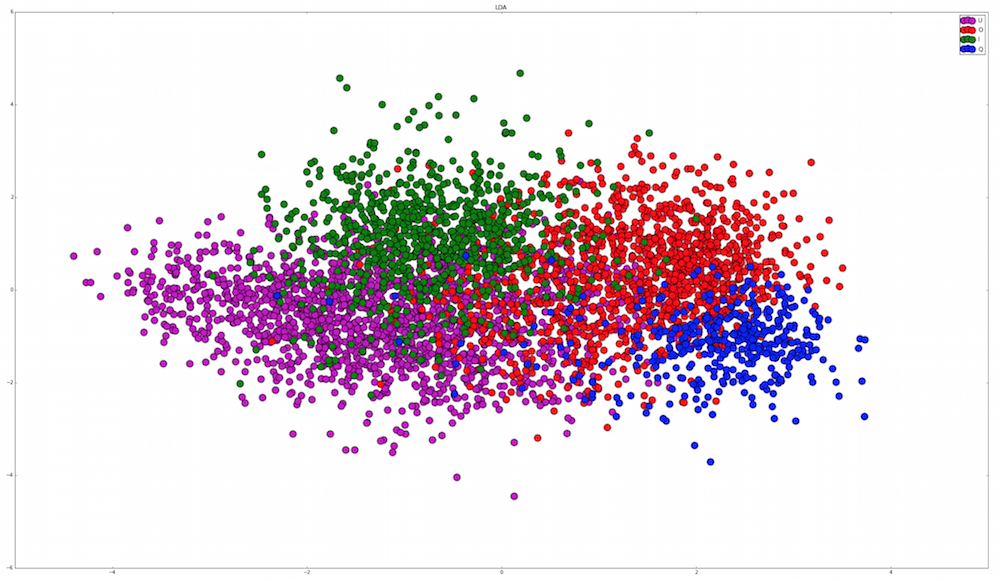
I've tried to use PCA and LDA on this data, LDA initially looked promising when I only trained it with easily lit tags, however once I include all tag types, the LDA looks a little less clear:
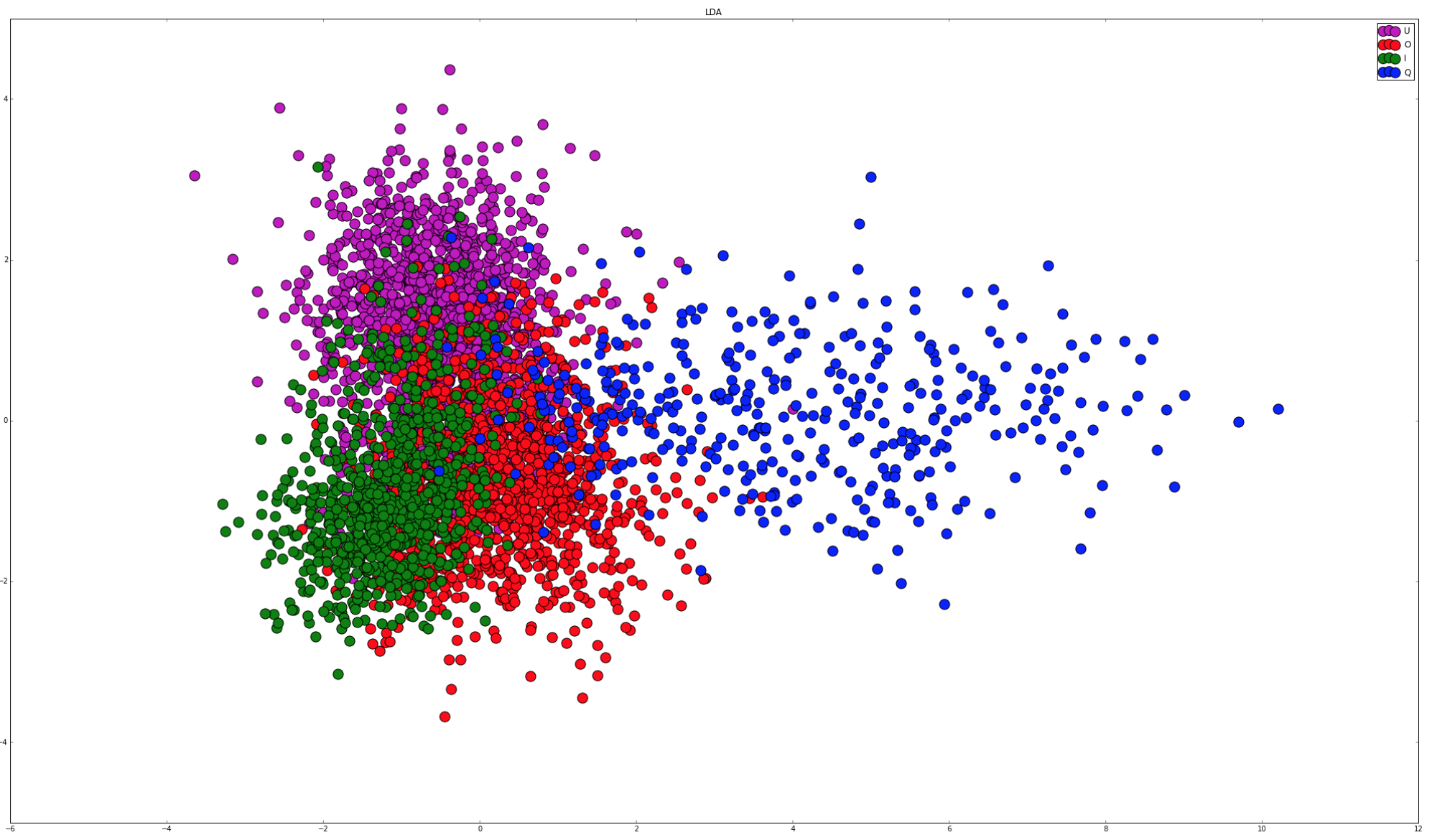
If I apply histogram equalisation to the tags, the queen tag seems to separate out reasonably well, and if I train an SVM with two classes (queen vs all others) it's 95% accurate.
I could train two SVMs where the first extracts the queen and then I use the other one to separate out the circles and rectangles. The problem is that there seems to be a fair bit of overlap between the LDA distributions of these shapes. Does anyone have any advice on other image processing, dimensionality reduction or machine learning techniques that I could try to separate these two groups?
How about using non-linear SVM kernels? They should be able to seperate those two clusters by projecting the data to another higher dimension space?
I've tried using an SVC with RBF kernel but that didn't seem to work any better unfortunately.