Probability of correct classification using LDA?
I recently asked a question here about how to use LDA. I had a lot of patient help from berak who showed me how to predict the label for a new image based on the closest value in my projection. One thing I would like to do though, is work out the probability of the prediction based on the clusters that my groups have formed. I tried this out with OpenCV + Python + scikit-learn and the results were very encouraging:
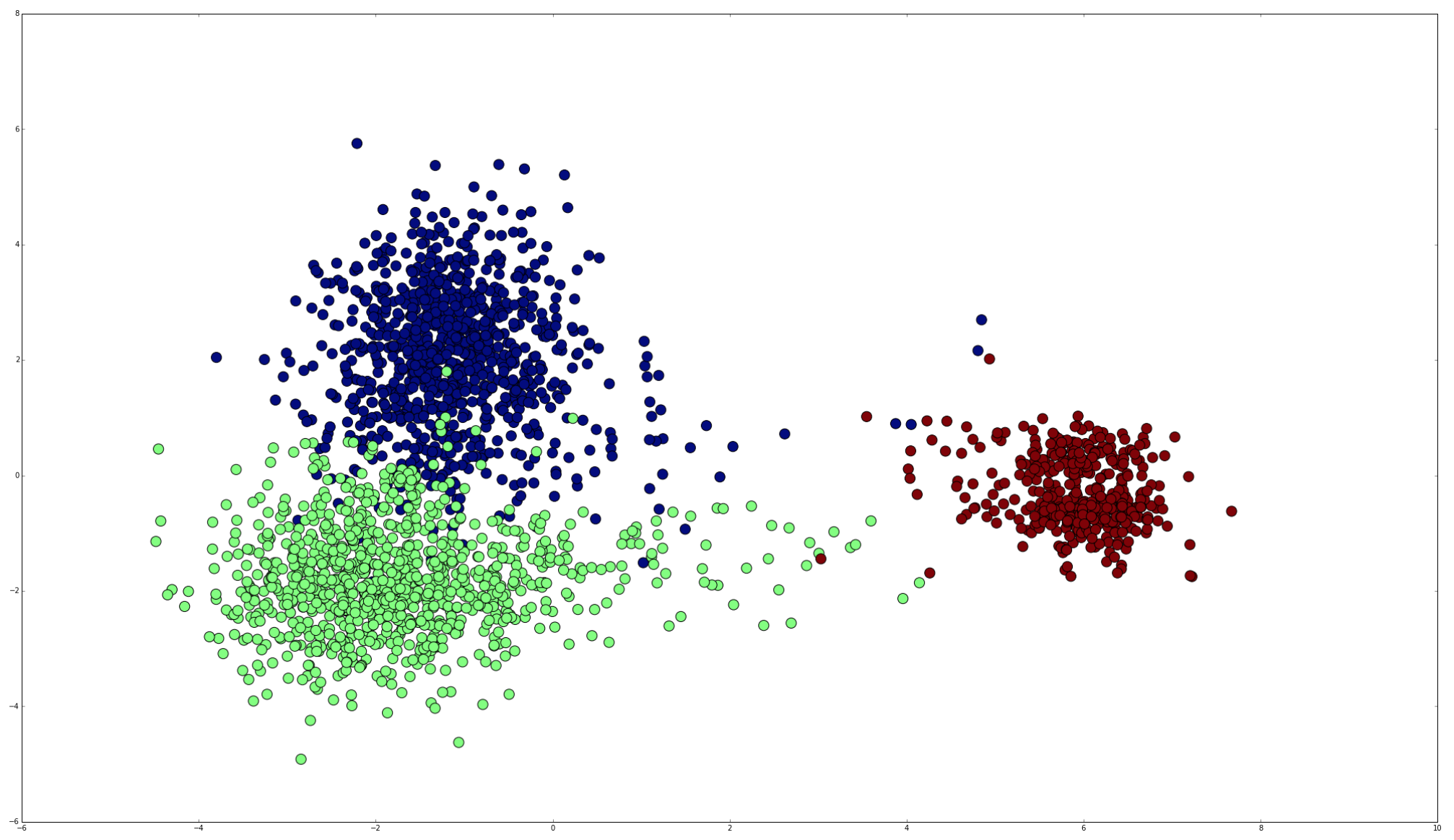
Does anyone know how to do something similar in C++ and OpenCV which is what my main program is written in? The main LDA functionality I have so far looks like this (thanks to all the help berak gave me):
Training Stage: Here, I have 3 different folders with my 3 tag types in them, I flatten out the first image to initialise my matrix, then keep pushing back on it with the flattened remaining images until I have a matrix where each row comes from a separate image of a tag.
cv::Mat initial_image = cv::imread("/Users/u5305887/Desktop/tags/I/0.jpg", 0);
cv::Mat trainData = initial_image.reshape (1, 1);
for (int i=1; i < 938; i++)
{
std::string filename = "/Users/u5305887/Desktop/tags/I/";
filename = filename + std::to_string(i);
filename = filename + ".jpg"
cv::Mat image = cv::imread(filename, 0)
cv::Mat flat_image = image.reshape(1,1);
trainData.push_back(flat_image);
}
for (int i=0; i < 977; i++)
{
std::string filename = "/Users/u5305887/Desktop/tags/O/";
filename = filename + std::to_string(i);
filename = filename + ".jpg"
cv::Mat image = cv::imread(filename, 0)
cv::Mat flat_image = image.reshape(1,1);
trainData.push_back(flat_image);
}
for (int i=0; i < 457; i++)
{
std::string filename = "/Users/u5305887/Desktop/tags/Q/";
filename = filename + std::to_string(i);
filename = filename + ".jpg"
cv::Mat image = cv::imread(filename, 0)
cv::Mat flat_image = image.reshape(1,1);
trainData.push_back(flat_image);
}
cv::Mat trainLabels = (Mat_<int>(1,2376) << 1, 1, 1, 1, 1, 1, 1); // 1D matrix of labels edited (deleted most in the list for brevity)
int C = 3; // 3 tag types
int num_components = (C-1);
cv::LDA lda(num_components);
lda.compute(trainData, trainLabels); // compute eigenvectors
Mat projected = lda.project(trainData);
Later, when I have a new tag, this is how berak advised me to predict it's type:
cv::Mat roi; // tag to classify
cv::Mat roi_flat = roi.reshape(1,1);
Mat proj_tag = lda.project(roi_flat)
int bestId = -1;
double bestDist = 999999999.9;
for (int i=0; i<projected.rows; i++)
{
double d = cv::norm( projected.row(i), proj_tag);
if (bestDist < d)
{
bestDist = d;
bestId = i;
}
}
int predicted = labels.at<int>(bestId);
Does anyone have advice on how I can work out the probability here instead so I can predict which tag type it should be based on the information about the clusters, rather than the nearest value (which may be an outlier)?
Just two random comments: 1) You don't have to initialise
trainDatawith the first image. Just start pushing back. Makes your code easier to understand if you loop from 0 everywhere. 2)std::string filename = "..."- you're copy-constructing a string fromconst char*here. Best do this:std::string filename("..."), or append 's' to make it a string literal (i.e."..."s).As for your main question, what about using the distance to each cluster center as a score? If that doesn't work so well, try training SVMs?
Thank-you for the advice about strings and how I can just push back on a Mat type from the beginning. That's really useful! I've decided to take your advice too and use an SVM on this :)