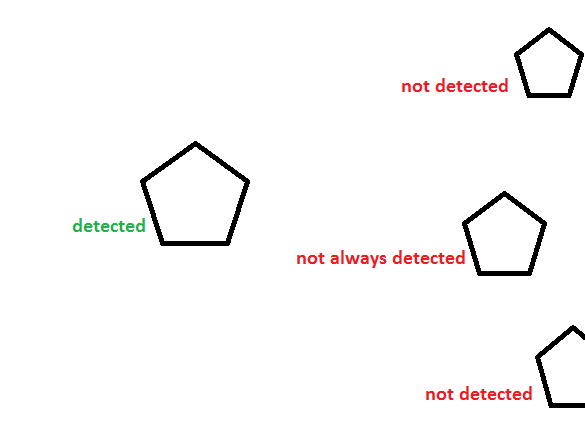
Okay lets respond to this, kind of my thing here!
- First off all please supply your full detection command. It highly depends on your model size and the scale range that you have defined for detections. Also add the command you used for cascade classifier sample creation and the training. Things can go wrong early but only noticable during processing.
- Detections not occuring on the edges even if the object is viewable --> means your training data had to many background information around the object and thus your model heavily depends on this. Avoid it by making bounding boxes that shear the edges of your actual object.
- The not detected one is due to the fact that it can only find full objects. There is simply no information for that one making it a complete different object.
As to the size of your model. Keep in mind that -w -h parameter define the smallest object size you can find. Therefore it is indeed better to train a smaller model to find smaller instances also. Reason is that upscaling an image introduces artifacts that screw up detections results, therefore the original input image is only downscaled and thus only larger or equal object to the object size will be found.
There is a reason why the standard Viola and Jones model has a 24x24 pixel model. It is a tradeoff between accuracy and the smallest face detection possible.