The following remarks lead to solving the problem for @GilLevi:
REMARK 1:
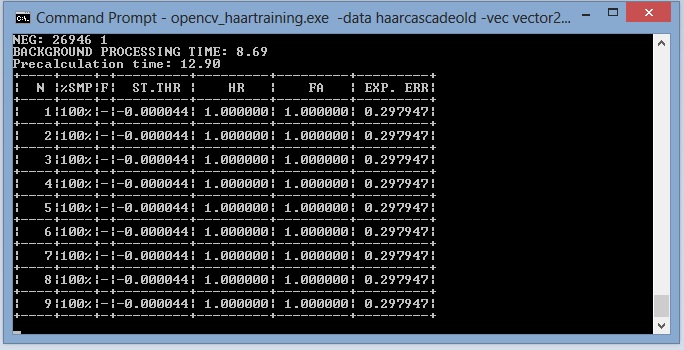
Isn't it more effective to translate the old C - interface? Or just the parts that communicate with your interface? As to your output, I have never seen a classifier doing this, reproducing the exact same information for several stages. However, are you aware that you ask your algorithm to find 24000 unique windows at each stage that can be classified as negatives and haven't been correctly classified before? I think this is a point which will, certainly in later stages, never been reached...
SUBSEQUENT QUESTION:
Can you please tell me how to change the parameters/number of images so it would not act this way?
REMARK 2:
Well for that you actually need to understand how the negatives get grabbed. Normally you have a supplied a list of negative images, with random sizes, but larger than the size of your model, which contain no objects. Next the algorithm performs a sliding window approach, making sure that each window is tested to be unique? This means that if two following windows are equal, the second one isn't used for training. At each stage, all negatives used and correctly classified get discarded, so new ones need to be found. Imagine doing this with 24.000 windows, will take a huge amount of time to find those unique negatives. Why not start with like npos 5000 nneg 5000 and look at your performance there?
SUBSEQUENT QUESTION:
I somehow managed to train a cascade using the new opencv_traincascade. It terminated after three days. Does that makes sense? by "my model", do you mean the parameters -w -h? it was set to -w 10 -h 10 and all the 24K negative images were larger than that.
REMARK 3:
It is possible if your 24000 negative images are actually larger than your model. It depends on what the last output was. Probably a stage reached your desired hit ratio versus a low false acceptance rate.
Yea I do mean that. Aha with such a small model, finding that much negatives would indeed be possible. So the training will be correct :)


Thanks @StevenPuttemans, Can you please tell me how to change the parameters/number of images so it would not act this way?
Thanks again @StevenPuttemans. I somehow managed to train a cascade using the new opencv_traincascade. It terminated after three days. Does that makes sense?
Thanks @StevenPuttemans, by "my model", do you mean the parameters -w -h? it was set to -w 10 -h 10 and all the 24K negative images were larger than that.
OK, @StevenPuttemans would you like to write an answer for the question for other people with similar problems?
Will copy my comments to a solution. You are welcome!