Birdseye transform with getPerspectiveTransform

Hello I am currently working on creating a python software that tracks players on a soccer field. I got the player detection working with YoloV3 and was able to output quite a nice result with players centroids and boxes drawn. What i want to do now is translate the players position and project their centroids onto a png/jpg of a soccerfield. For this I inteded to use two arrays with refrence points one for the soccerfield-image and one for the source video. But my question now is how do I translate the coordinates of the centroids to the soccerfield image.
Similiar example:
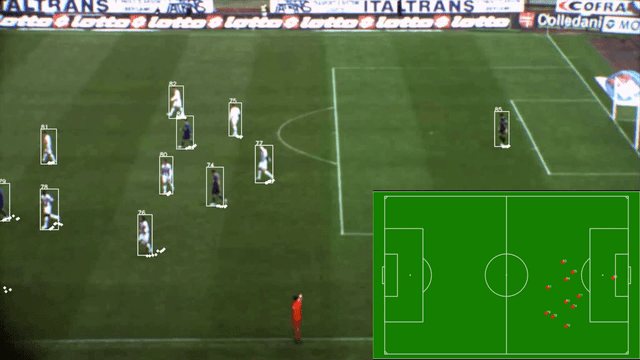
How the boxes and Markers are drawn:
def draw_labels_and_boxes(img, boxes, confidences, classids, idxs, colors, labels):
# If there are any detections
if len(idxs) > 0:
for i in idxs.flatten():
# Get the bounding box coordinates
x, y = boxes[i][0], boxes[i][1]
w, h = boxes[i][2], boxes[i][3]
# Draw the bounding box rectangle and label on the image
cv.rectangle(img, (x, y), (x + w, y + h), (255, 255, 255), 2)
cv.drawMarker (img, (int(x + w / 2), int(y + h / 2)), (x, y), 0, 20, 3)
return img
Boxes generated like this:
def generate_boxes_confidences_classids(outs, height, width, tconf):
boxes = []
confidences = []
classids = []
for out in outs:
for detection in out:
# print (detection)
# a = input('GO!')
# Get the scores, classid, and the confidence of the prediction
scores = detection[5:]
classid = np.argmax(scores)
confidence = scores[classid]
# Consider only the predictions that are above a certain confidence level
if confidence > tconf:
# TODO Check detection
box = detection[0:4] * np.array([width, height, width, height])
centerX, centerY, bwidth, bheight = box.astype('int')
# Using the center x, y coordinates to derive the top
# and the left corner of the bounding box
x = int(centerX - (bwidth / 2))
y = int(centerY - (bheight / 2))
# Append to list
boxes.append([x, y, int(bwidth), int(bheight)])
confidences.append(float(confidence))
classids.append(classid)
return boxes, confidences, classids

@jonas_he. U can't do video streaming on warpPerspective. It is called PitchBrain(the one on bottom right side screenshot). It is using by Deep Learning OpenCV. U don't needed Yolo3 and no rectangle and centroids too. U needed to do 2 colours one white and one black jersey.
How did u get PitchBrain?