[OPENCV GPU] How can I convert GpuMat and Vector<Point2f> using HostMem? [closed]
Hello,
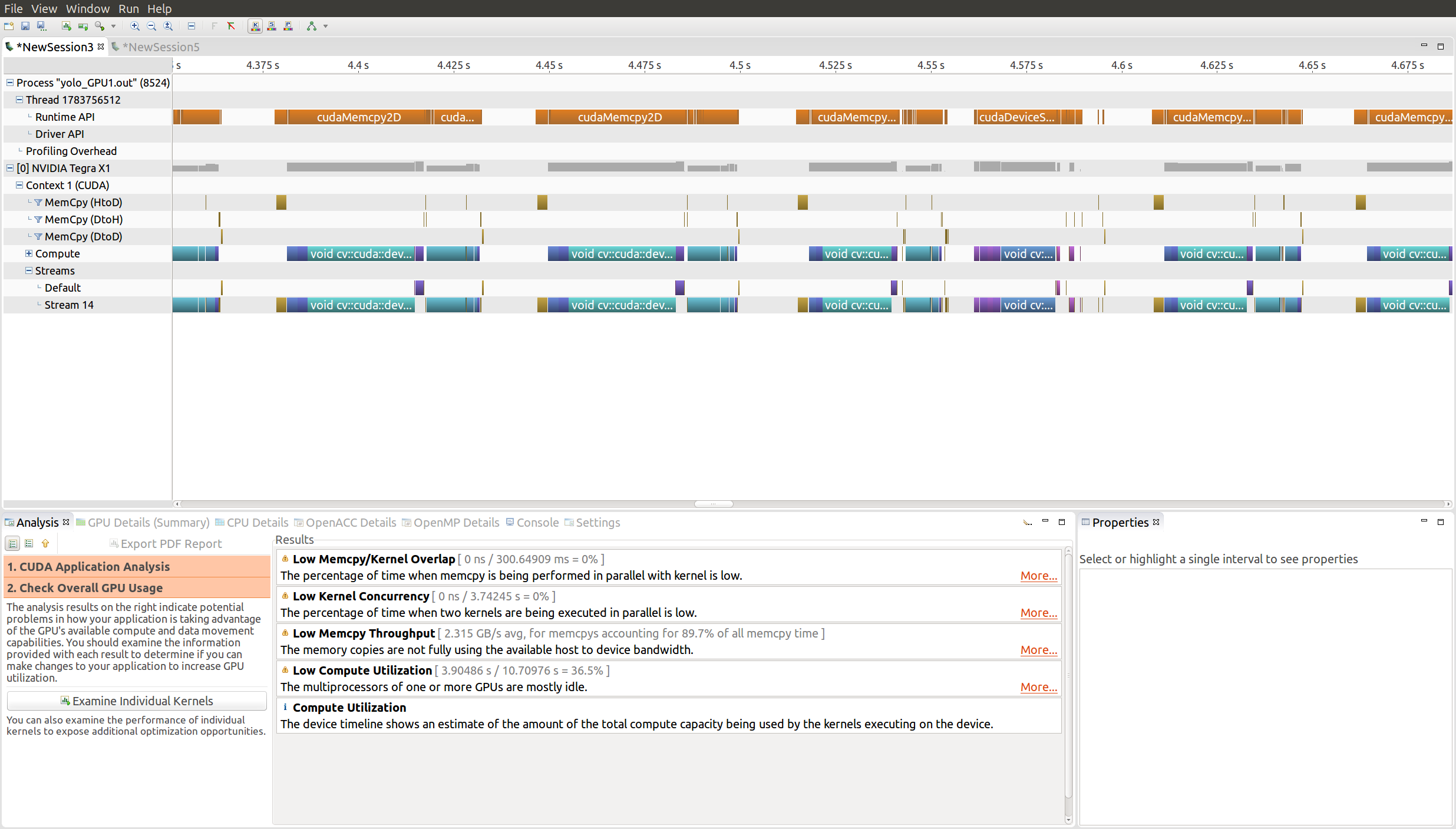
I manage to convert from GpuMat to Vector<point2f> by following this post. Now I am trying to optimize the code. I found that to reduce the time spent on the cudaMemCpy2D I have to pin the host buffer memory. In the following image you can see how cudaMemCpy2D is using a lot of resources at every frame:
In order to pin the host memory, I found the class:
cv::cuda::HostMem
However, when I do:
void download(const cuda::GpuMat& d_mat, vector<Point2f>& vec)
{
cv::Mat mat(1, vec.size(), CV_32FC2, (void*)&vec[0]);
cv::cuda::HostMem h_mat(mat);
d_mat.download(h_mat);
}
and then I run the function download and the vec is full with of points at 0,0:
std::vector of length 193, capacity 193 = {{x = 0, y = 0}, {x = 0, y = 0}, ... , {x = 0, y = 0}, {x = 0, y = 0}}
Is there anyone who can help me with this?
Thank you in advance.
Closed for the following reason
duplicate question by
JordiGC
close date 2019-12-02 06:17:37.881079
add a comment