Barcode style recognition

Hey there,
so we want to recognise , get the area, adjust the perspective and put it through the decoder.
, get the area, adjust the perspective and put it through the decoder.
Thats my first time for image processing, so after some playing around i went for canny edge detection, finding the contours and filtering them out as the dots in the part we need should all be close to each other in size and also are a lot in a specific area.
So while trying to get that to work i used 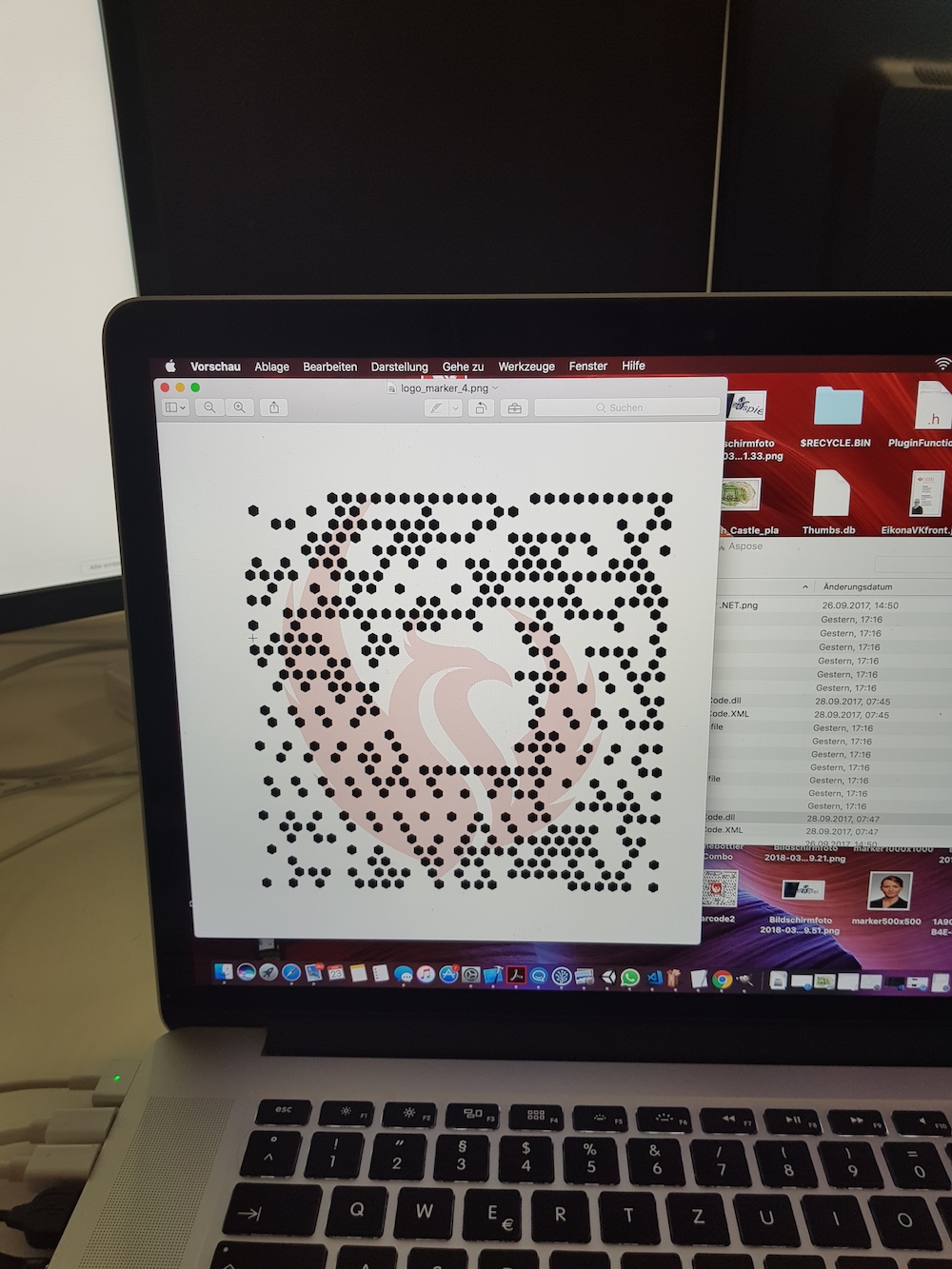 for testing and got to an
for testing and got to an 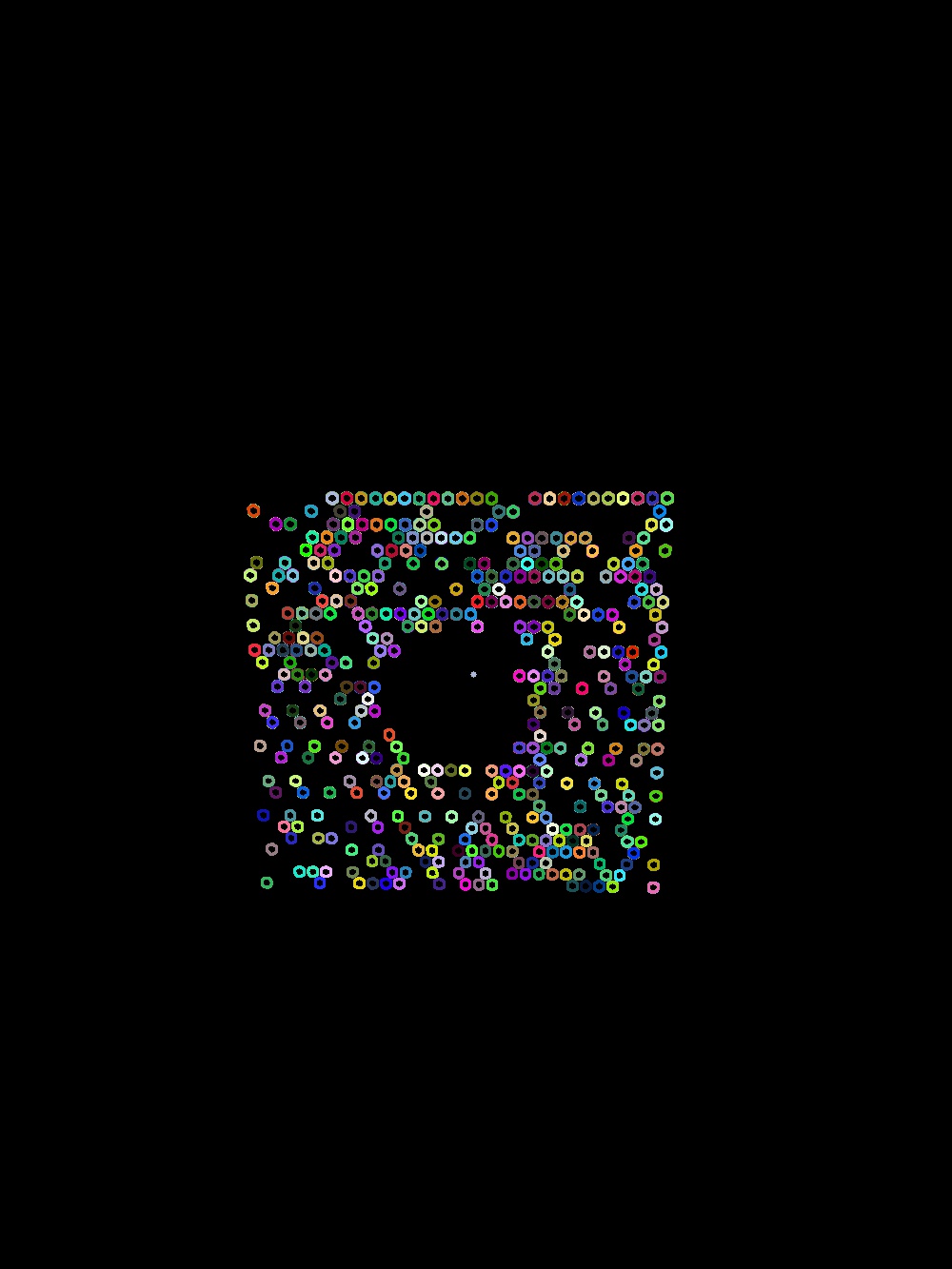 in a short time.
in a short time.
While ideally the area i want fills most of the screen that ofc wont happen too much and at that point i went to test with some other source images and what can i say its not working at all. Text messes it up totally, the lines you usually have when taking pictures of a monitor do and probably a lot else does.
So before trying to fix my code i'd appreciate some opinions on how you would start tackling the problem , what not to do or any other tipps
What im basically doing to filter out the contours is
checking if we have center of masses close by
averaging length and area of contours and taking only those that are like 50 - 150% around that ( tried different values)
center off all masses of rest of contours and calculating distance of each to complete center of mass and skipping the ones that are just far off
You might try searching the web for some research papers. Finding 1D (barcodes), stacked 1D codes, and 2D codes (per your example) in an otherwise busy image with conflicting patterns, is an area of study with a very long history of academic and commercial interest. This includes code detection, location, encoding identification, and start pattern recognition, at various resolutions, contrasts, saturation, distortion, noise and debris. The most successful common and modern codes are designed and printed to be visualized under a wide range of ambient conditions. Some use rotation/scale invariant methods. Some are designed to be re-assembled from fragments seen in multiple frames. Hope this helps.