The labelComponents algorithm is legacy and uses Nvidia's NPP library, graphcut api. Unfortunately this was removed by Nvidia in CUDA 8.0.
If you read the git log you for modules\cudalegacy\src\graphcuts.cpp you can see that it was moved from cuda to cudalegacy in Jan 2015, probably because of the removal of the above api.
If you look at the source for labelComponents, line 46 you can see that only the headers are included for versions of CUDA greater than or equal to 8, to allow OpenCv to compile with the legacy modules selected.
Because you are 100% that you need to process on the GPU I dug out some timing results I had for a CUDA CCL implementation I worked on at a previous company, to give you an indication of the performance increase that is achievable when performing CCL on the GPU.
The comparison was connectedComponentsWithStats and cvFindContours run on a laptop i7 vs against our ccl implementation on a gtx 980m with CUDA 8.0 (no cooperative groups).
Because CCL algorithms on the GPU are iterative the execution time is highly dependent on the type of image you are looking at. For example our CUDA implementation was only slightly faster on the below 1080p maze image
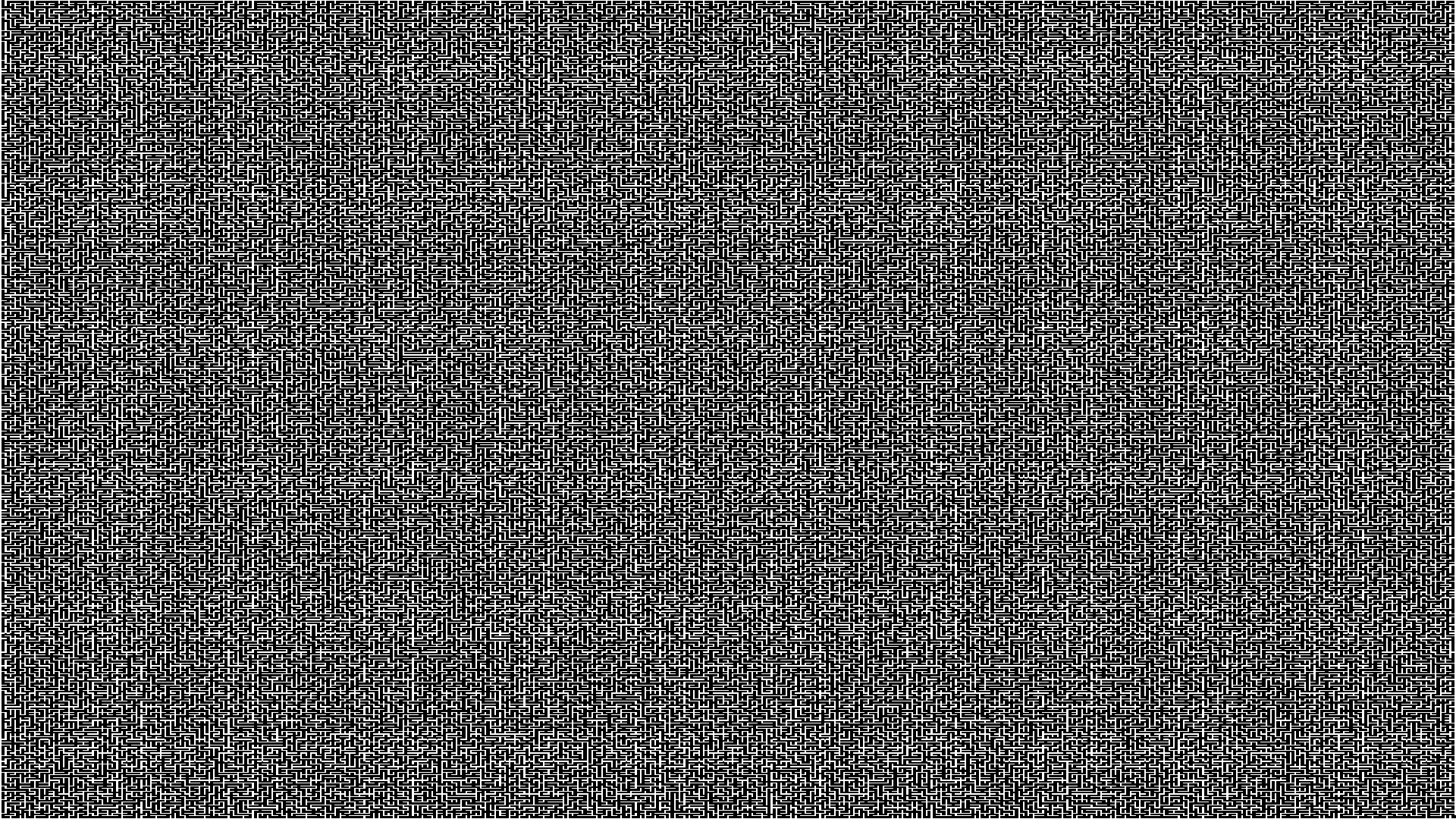
cvFindContours: 16.3ms
connectedComponentsWithStats: 4.5ms
customCCL: 3.9ms
however on the below classic foreground image (enlarged to 960x2240 to saturate the GPU)
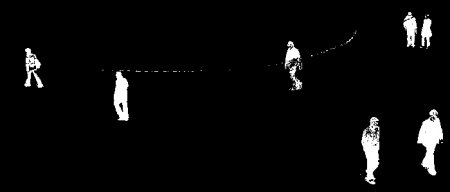
our implementation was over 2x faster
cvFindContours: 0.63ms
connectedComponentsWithStats: 3.2ms
customCCL: 1.4ms
however on this type of image you cvFindContours performs extremely efficiently
Our implementation of the CCL algorithm was competitive being significantly faster than ArrayFire's regions, mainly because it required fewer iterations to converge.