Is it possible to use neural nets for line detection?
Neural nets are known for their ability of error correction. Straight lines are often broken, contain small gaps. Using large parameter for these gaps in probabilistic Hough has the side effect that the line continues beyond its true ends. Did anybody try to solve this problem using NN? I have a good output from edge detector with lines as white dots on black background (1/0). Maybe it is possible not only correct gaps, but do full detection (slope, end coordinates)?
For those who are interested in this approach I can hint that David Marr in his classical book "Vision" proposed to use combination of Gauss distribution with Laplace operator for edge detection. Gauss provides blurring and Laplacian - gradient calculation. He used a convolutional net with the characteristic connections like a Mexican hat.
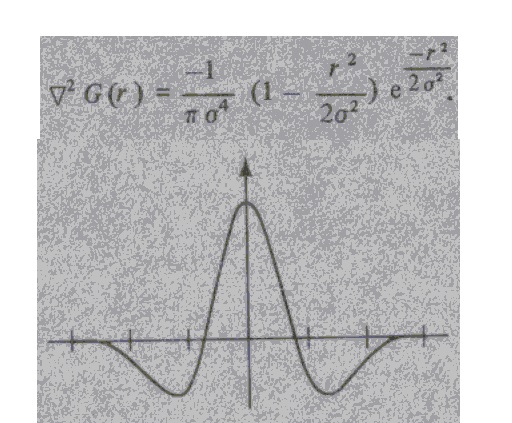
That is, each neuron supports itself and the nearest neighbours, but suppresses the more remote.
This is what Marr's filter does to Canny output from Rubik's cube.

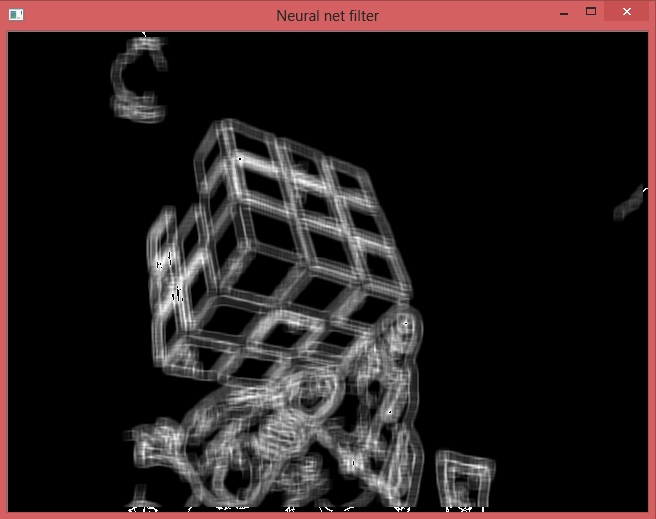 Looks like what is required. Now need to downsample it. How to do it correctly? Just take every second or third pixel or there are some tricky methods? I used this kernel:
Looks like what is required. Now need to downsample it. How to do it correctly? Just take every second or third pixel or there are some tricky methods? I used this kernel:
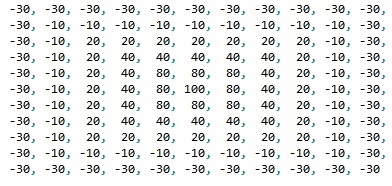
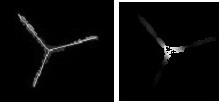
Another set of parameters shows off full power of the method. It restores true edges even if they are completely absent on Canny output. Note that it draws 3 lines where there are only 2. The most important - it restores the central dot where 3 edges come together. It is absent on source image too.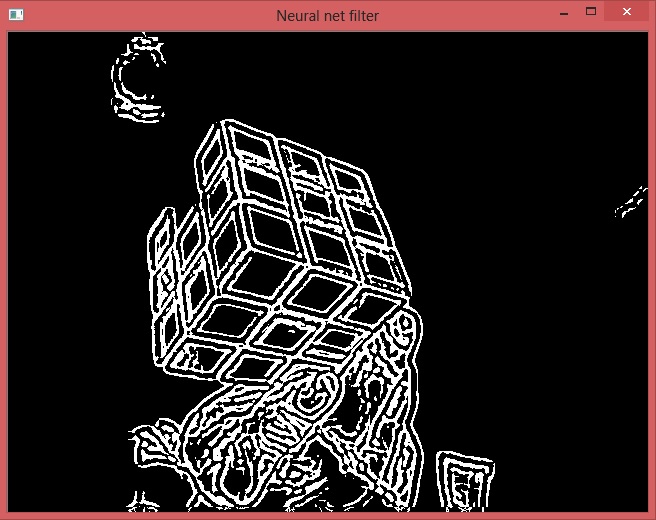
Look how the simple perceptron technology (see the answer) works for 3D corner detection.

There are 2 output neural patterns here because the angle range is 0 - 180. The upper image corresponds to the lower half of the input screen.
The last thing left. How to detect the central point where 3 lines come together? I think, it's time to introduce more complicated nets combining several standard solutions. I suggest convolution + recursion (RNN). The idea is to highlight all pixels of the same line by positive biofeedback. Then the brightness of their common end will get triple increase like this.
Any ideas how to do it better?


I think the complete automotive industry is solving this issue with deep learning and thus neural networks. The question will be if OpenCV will have support for these networks, which I haven't seen around yet. However there are tons of github repos out there doing exactly this!
This link to github reads: Monocular vehicle detection using SVM and Deep Learning classifiers I asked about a different task, not line following which is indeed very popular, say, in educational robotics. There is a rectangular object from which you extract edges. These edges will have defects - gaps. Need to correct them.
Ow i completely misunderstood your problem then :D That might indeed be another issue. Let me overthink this tonight :D
Also nowadays deep learning overshadowed everything. People forgot that there are different architectures with different abilities. Deep learning is hierarchical concept formation from examples. This task is of a different class - signal processing. I think, it may be implemented without learning whatsoever. Just need to determine the microstructure of the net. This is similar to various methods using kernel processing.
I agree, interesting idea. I have no idea if there are studies on line detection with DNN.
As lines are very easy to describe analytically, the classical methods like Hough transform and RANSAC work generally well and fast, even in presence of noise.
Another interesting method for line or shape detection in noisy images is the marked point process. Check the articles from the team of X. Descombes and J. Zerubia (link) at INRIA (Check here or here)
this seems to be some kind of "gedankenexperiment", once you have real-world constraints, even "done-on-a-napkin", it might look less feasible.
what would be the input ? a hd-image ? for sure not. you'd have to downsample, and at that stage already miss the gaps, you're trying to correct.
and the output ? (dnn's are usually some kind of pyramid, large data at the bottom, small data at the top (aka the "prediction") the larger you make that, the more expensive it gets.
but again, +1 for starting this discussion !
The solution for the problems with performance is convolution. CNN doesn't use connections of all-to-all so runs much faster. In principle, existing methods using kernel do the same, but I think that NN are slightly different. Standard programming is algorithmic so deterministic in the foundation. Neural nets are essentially probabilistic, based on Fuzzy Logic. So errors may be corrected automatically in the process of mainstream calculations.
To kbarni. Both RANSAC and another method which you provided require heavy computations. RANSAC will not catch a line of 50 dots in the image containing hundreds of other dots. The second one has such heavy math that even understanding the principle of operation requires substantial efforts. It includes statistical Student test among other things. This is clearly for overnight rather than real-time computing. I agree that Hough transform works fine, but it has a problem with lines which end up near some cloud of dots. To determine exact ends, you need to use Probabilistic Hough. When you increase the possible gap in the line, it starts to overshoot into such clouds. The error of line length may be up to 100%. In fact, only zero gap works without errors. Other values produce defects.
@ya_ocv_user, just curious, what kind of nn was used for the image above ?
This was a simple convolutional net with 2 layers. The first layer takes the gray image. The second layer has the same matrix. Activity of each neuron is calculated as weighted sum from its neighbours from 1 layer. I have posted the array of weights (kernel) in the question.