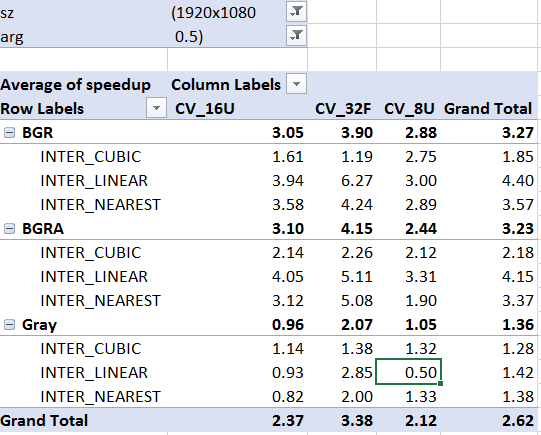
GPU vs CPU end to end latency for dynamic image resizing
I have currently used OpenCV and ImageMagick for some throughput benchmarking and I am not finding working with GPU to be much faster than CPUs. Our usecase on site is to resize dynamically to the size requested from a master copy based on a service call and trying to evaluate if having GPU makes sense to resize per service call dynamically.
Sharing the code I wrote for OpenCV. I am running the following function for all the images stored in a folder serially and Ultimately I am running N such processes to achieve X number of image resizes.I want to understand if my approach is incorrect to evaluate or if the usecase doesn't fit typical GPU usecases. And what exactly might be limiting GPU performance. I am not even maximizing the utilization to anywhere close to 100%
resizeGPU.cpp: {
cv::Mat::setDefaultAllocator(cv::cuda::HostMem::getAllocator (cv::cuda::HostMem::AllocType::PAGE_LOCKED));
auto t_start = std::chrono::high_resolution_clock::now();
Mat src = imread(input_file,CV_LOAD_IMAGE_COLOR);
auto t_end_read = std::chrono::high_resolution_clock::now();
if(!src.data){
std::cout<<"Image Not Found: "<< input_file << std::endl;
return;
}
cuda::GpuMat d_src;
d_src.upload(src,stream);
auto t_end_h2d = std::chrono::high_resolution_clock::now();
cuda::GpuMat d_dst;
cuda::resize(d_src, d_dst, Size(400, 400),0,0, CV_INTER_AREA,stream);
auto t_end_resize = std::chrono::high_resolution_clock::now();
Mat dst;
d_dst.download(dst,stream);
auto t_end_d2h = std::chrono::high_resolution_clock::now();
std::cout<<"read,"<<std::chrono::duration<double, std::milli>(t_end_read-t_start).count()<<",host2device,"<<std::chrono::duration<double, std::milli>(t_end_h2d-t_end_read).count()
<<",resize,"<<std::chrono::duration<double, std::milli>(t_end_resize-t_end_h2d).count()
<<",device2host,"<<std::chrono::duration<double, std::milli>(t_end_d2h-t_end_resize).count()
<<",total,"<<std::chrono::duration<double, std::milli>(t_end_d2h-t_start).count()<<endl;
}
calling function :
cv::cuda::Stream stream;
std::string dir_path="/home/gegupta/GPUvsCPU/";
const auto& directory_path = dir_path;
const auto& files = GetDirectoryFiles(directory_path);
for (const auto& file : files) {
std::string full_path = dir_path + file;
processUsingOpenCvGpu(full_path,stream);
}
resizeCPU.cpp:
auto t_start = std::chrono::high_resolution_clock::now();
Mat src = imread(input_file,CV_LOAD_IMAGE_COLOR);
auto t_end_read = std::chrono::high_resolution_clock::now();
if(!src.data){
std::cout<<"Image Not Found: "<< input_file << std::endl;
return;
}
Mat dst;
resize(src, dst, Size(400, 400),0,0, CV_INTER_AREA);
auto t_end_resize = std::chrono::high_resolution_clock::now();
std::cout<<"read,"<<std::chrono::duration<double, std::milli>(t_end_read-t_start).count()<<",resize,"<<std::chrono::duration<double, std::milli>(t_end_resize-t_end_read).count()
<<",total,"<<std::chrono::duration<double, std::milli>(t_end_resize-t_start).count()<<endl;
Compiling : g++ -std=c++11 resizeCPU.cpp -o resizeCPU pkg-config --cflags --libs opencv
I am running each program N number of times controlled by following code : runMultipleGPU.sh
#!/bin/bash
echo $1
START=1
END=$1
for (( c=$START; c<=$END; c++ ))
do
./resizeGPU "$c" &
done
wait
echo All done
Run : ./runMultipleGPU.sh <number_of_such_processes>
Those timers around lead to following aggregate data
No_processes resizeCPU resizeGPU memcpyGPU totalresizeGPU
1 1.51 0.55 2.13 2.68
10 5.67 0.37 2.43 2.80
15 6.35 2.30 12.45 14.75
20 6.30 2.05 10.56 12.61
30 8.09 4.57 23.97 ...