best way to do the traincascade via the standalone tool [closed]
Hi all
I'm trying to train a classifier to detect cars shadows (rear view) and I am facing difficulties doing that, later I want to use the output to verify the possible car region via HOG+SVM (will worry about it later). I don't know exactly what is needed to do so as I'm using around 692 positive samples with 4400 negatives converted to gray, cropped exactly to the object (160x45). for training I'm using 600 pos, 3500 neg. My target dimensions: -w 60 -h 17
Positive samples are like (160x45):

Negative samlpes are like (160x45):

And this is the horrible result with only 1 correct catch (I made the rectangle height similar to the width to match the whole car):
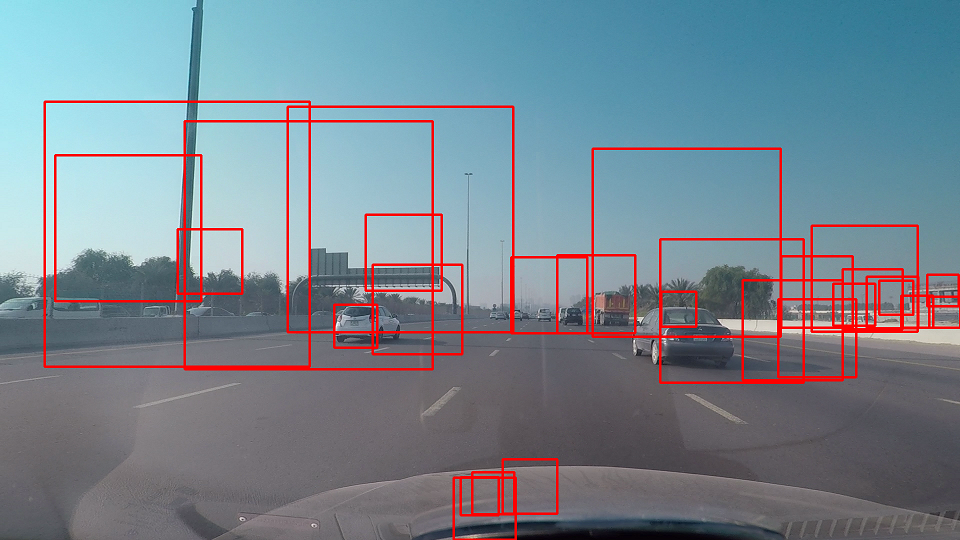
What exactly is wrong? Do I need more samples? Is it required to do histogram equalization (before or after)? Is it mandotary to use the annotation tool (I'm using cropped images so my pos.txt having things like pos/pos2.png 1 0 0 160 45)? Do my negative samples should be a full image or just peices matches the size of the positives? I'm so confused! Appreciate any help really
Thanks
Start by sharing some results that are not satisfactory. Secondly could you elaborate more on your end goal? Cascade classification might not what you be needing. You do not need to use the annotation tool at all.
Your positive set is completely random. Since boosting is internally basically trying to get an optimal seperation between positives and negatives, I am afraid your model is failing. Also your model detections are squared and your data rectangular. So you are using wrong
-wand-hparameters.So what do I have to do then? As per my investigation I found everybody is telling to get samples of the object in its many statuses. For the squared detection actually I'm making it like that, when I get the Rect vector I'm making the height equals the width before I plot the borders on the image so the
-wand-hare fine I suppose.Also I wonder if my positive and negative samples should be converted to grey scale and then have a histogram equalization?
Well let me wrap some things up
shadowobject is so versatile that I am afraid it will be impossible for the machine learning to find any common features. Can you explain why you want to track shadows?I am wondering if trying to detect cars, and then just based on that detection finding the shadows isn't much easier than what your are trying to do now.
The idea is getting the shadow locations, make the detected Rect as squared, resize to 64x64, then run a verification for that squared area via SVM traind with HOG from another samples of cars rear shot. I'm trying to replication the work of some other researchers in order to do some enhancements.
wow your explanation does not make sense. If I was to get the locations, I would go for the cars (a widely solved problem and take the lower bounds of the detection as shadow region)
Maybe you are right.. Can you provide me with the best opinion, method or ready code you came across? Note that the camera is moving and not fixed.