Rotation of word and cropping
I'm trying to build a simple price-tag scanner and I've gotten reasonably far with regards to binarisation and general de-noising.
However, feeding an image like this to Tesseract doesn't yield very good results. Tesseract seems very sensitive to the amount of artifacts present in the picture, aside from what is to be recognised, as well as even slight skews on the text. Here's an example, where a ROI around a price has been selected and binarised:
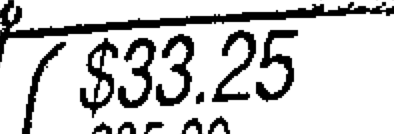
Asking Tesseract to OCR this image, is rather useless: flflflflfl.
However, if I could manage to somehow consistently deskew and crop to just the numbers, it's a whole different thing:
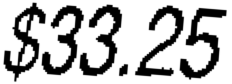
Now Tesseract provides a clean result: $33.25
In this case, because of the straight black line at the top, I could use a Hough transform and calculate the angle, in order to deskew the image, but there won't always be straight lines to use, so that won't work in general.
I could also use an ER filter to get just the text region, but then I'd get a rectangle without rotation and I'd still need to figure out how to crop/deskew again regardless.
So my question is, if there's some clever way to extract a relatively tight bounding box, a'la minAreaRect(), around just the number, in order to make presentable cutout to feed to Tesseract?

I don't know anything about the size of the characters unfortunately. They will be in all kinds of sizes and font types.