HOG calculation [closed]
I'm applying a research that includes HOG + SVM Is there any process is needed before using OpenCV HOG features extraction? In the research paper they are talking about some mask to be applied as a first step: 1D centered point discrete derivative mask [-1, 0, 1] and [-1, 0, 1]^-1 in one or both of the horizontal and vertical directions to obtain the gradient orientation and gradient magnitude. We can use the Eq. 1 and Eq.2 to calculate each pixel point's horizontal and vertical gradient value, respectively. And use the Eq. 3 and Eq. 4 to calculate pixel point's gradient magnitude value and gradient value, respectively.
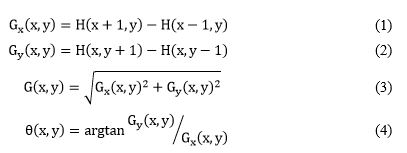
Then:
2) Orientation binning:
Each pixel within the cell casts a weighted vote for an orientation-based histogram channel based on the values found in the gradient computation. The histogram channels are evenly spread over 0 to 180 degrees or 0 to 360 degrees, depending on whether the gradient is 'unsigned' or 'signed'. In our study, we use the 'unsigned' and nine channels that evenly spread over 0 to 180 degrees to construct our histogram. As for the vote weight, pixel contribution can either be the gradient magnitude itself, or some function of the magnitude. We just use the gradient magnitude value as vote weight in our study.
3) Descriptor blocks:
In order to avoid for changes in illumination and contrast, the gradient strengths must be locally normalized, which requires grouping the cells together into larger, spatially connected blocks. The HOG descriptor is then the vector of the components of the normalized cell histograms from all of the block regions. These blocks typically overlap, meaning that each cell contributes more than once to the final descriptor. Every four cells (22) comprise one block in our study. For an image with size of 6464, we assume that each cell's size is 88, and the size of one block is 1616 since one block comprises four cells. Thus, we can consider that there are 49 blocks in an image since one block can be slid seven times in horizontal and vertical orientation, respectively. Meanwhile, there are nine channels in one cell and 36 features in one block. Thus, we can obtain the number of features is 1764 (3649) in a 6464 image that as shown as Figure 7.
So please is there anybody can help me in this task as I'm supposed to compare this to a new method of my own (in progress)..
unless that's some assignment(where you'd have to do anything manually), you would use opencv's builtin HogDescriptor here.
can you clarify ?
If you want to compare your method with the original HOG, you should use the original HOG implementation from the authors if available (maybe this one?).
You could also ask the original authors if they can provide the source code or the binaries.