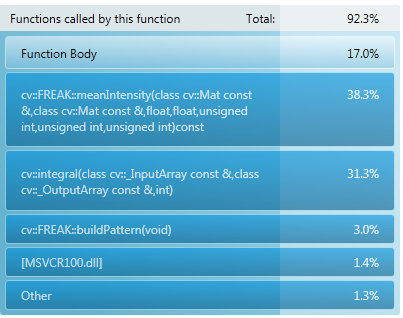
I have profiled it on Windows (with Visual Studio profiler), and here are some results:
Even at first sight, it is clear that the algorithm is highly optimized - most time is spent waiting for memory reads.
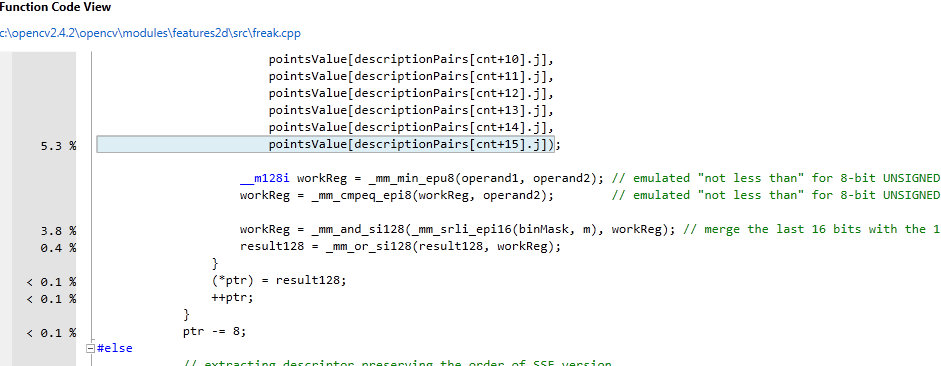
Some parts of it are optimzed with SSE, others will not get that much by SSE.
What you can do to improve it:
- declare the FREAK pattern static - you won't build it each time - you get 3% increase. Easy.
- parallelize keypoint finding (you will parallelize the 40% time spent in meanIntensity) It should be easy to do it
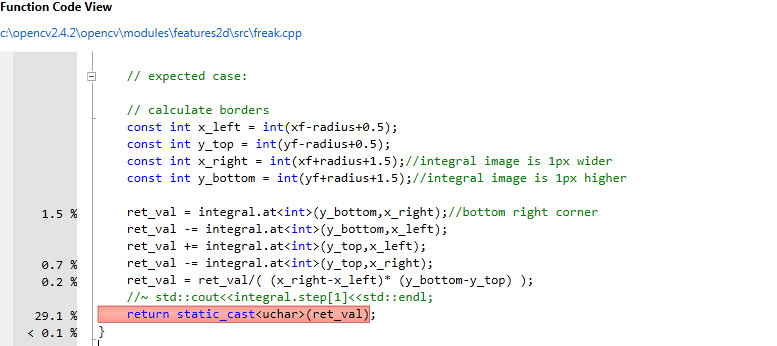
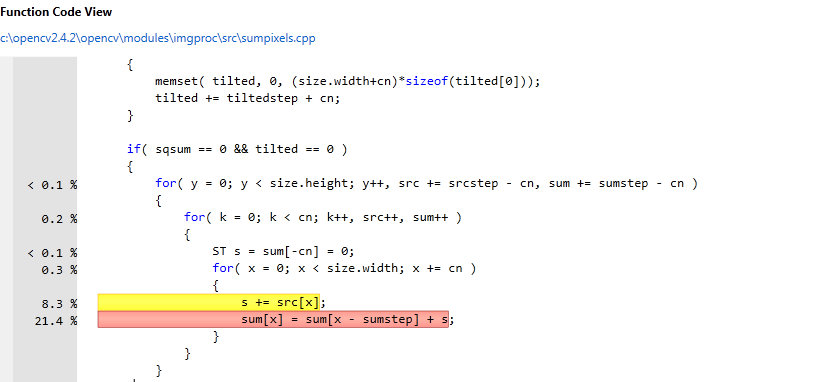
- try to find an algorithm for parallel integral image (not sure there is possible on generic architectures) - you will parallelize up to 32% of the computations.
- Find a faster algorithm for FREAK, or ways to more easily discard false key-points, to minimize calculations. It is probably the most rewarding and the most complex approach. Keep us in touch if you find something useful here!
- Write your own, faster, key-point extraction. It seems that everyone writes an extractor these days - ORB, FAST, SURF, SIFT, ASIFT, and many others. Just find one more :)