This forum is disabled, please visit https://forum.opencv.org
| | 1 | initial version |
Hi,
ORB is a binary descriptor and for the matching step you could use:
cv::Ptr<cv::DescriptorMatcher> matcher = cv::makePtr<cv::FlannBasedMatcher>(cv::makePtr<cv::flann::LshIndexParams>(12, 20, 2));cv::Ptr<DescriptorMatcher> matcher = cv::DescriptorMatcher::create("BruteForce-Hamming");Also, for small database size, the difference in processing time between a brute force approach and the FLANN library is very small (LSH matching very slow), and keep in mind that FLANN means Fast Library for Approximate Nearest Neighbors.
| | 2 | No.2 Revision |
Hi,
ORB is a binary descriptor and for the matching step you could use:
cv::Ptr<cv::DescriptorMatcher> matcher = cv::makePtr<cv::FlannBasedMatcher>(cv::makePtr<cv::flann::LshIndexParams>(12, 20, 2));cv::Ptr<DescriptorMatcher> matcher = cv::DescriptorMatcher::create("BruteForce-Hamming");Also, for small database size, the difference in processing time between a brute force approach and the FLANN library is very small (LSH matching very slow), and keep in mind that FLANN means Fast Library for Approximate Nearest Neighbors.
For floating point descriptors (SIFT or SURF for example), the distance between two descriptors is computed using the Euclidean distance:
For binary descriptors, the Euclidean distance can be "simplified" with the Hamming distance:
.
On modern CPU architecture, the two operations involved, xor and bits count is normally implemented in such a way that these operations are cheap in term of CPU time.
| | 3 | No.3 Revision |
Hi,
ORB is a binary descriptor and for the matching step you could use:
cv::Ptr<cv::DescriptorMatcher> matcher = cv::makePtr<cv::FlannBasedMatcher>(cv::makePtr<cv::flann::LshIndexParams>(12, 20, 2));cv::Ptr<DescriptorMatcher> matcher = cv::DescriptorMatcher::create("BruteForce-Hamming");Also, for small database size, the difference in processing time between a brute force approach and the FLANN library is very small (LSH matching very slow), and keep in mind that FLANN means Fast Library for Approximate Nearest Neighbors.
For floating point descriptors (SIFT or SURF for example), the distance between two descriptors is computed using the Euclidean distance:
For binary descriptors, the Euclidean distance can be "simplified" with the Hamming distance:
.
On modern CPU architecture, the two operations involved, xor and bits count is normally implemented in such a way that these operations are cheap in term of CPU time.
This seems to be the way that normHamming is implemented currently in OpenCV 3.0.
| | 4 | No.4 Revision |
Hi,
ORB is a binary descriptor and for the matching step you could use:
cv::Ptr<cv::DescriptorMatcher> matcher = cv::makePtr<cv::FlannBasedMatcher>(cv::makePtr<cv::flann::LshIndexParams>(12, 20, 2));cv::Ptr<DescriptorMatcher> matcher = cv::DescriptorMatcher::create("BruteForce-Hamming");Also, for small database size, the difference in processing time between a brute force approach and the FLANN library is very small (LSH matching very slow), and keep in mind that FLANN means Fast Library for Approximate Nearest Neighbors.
For floating point descriptors (SIFT or SURF for example), the distance between two descriptors is computed using the Euclidean distance:
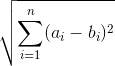
For binary descriptors, the Euclidean distance can be "simplified" with the Hamming distance:
.

On modern CPU architecture, the two operations involved, xor and bits count is normally implemented in such a way that these operations are cheap in term of CPU time.
This seems to be the way that normHamming is implemented currently in OpenCV 3.0.