This forum is disabled, please visit https://forum.opencv.org
| 2021-01-10 18:32:22 -0600 | received badge | ● Famous Question (source) |
| 2020-12-15 11:48:38 -0600 | received badge | ● Notable Question (source) |
| 2019-08-16 09:24:56 -0600 | received badge | ● Popular Question (source) |
| 2019-08-08 08:34:20 -0600 | received badge | ● Famous Question (source) |
| 2019-01-22 20:14:47 -0600 | received badge | ● Notable Question (source) |
| 2018-08-29 07:34:20 -0600 | received badge | ● Notable Question (source) |
| 2018-06-08 02:47:10 -0600 | received badge | ● Popular Question (source) |
| 2018-03-05 01:37:49 -0600 | received badge | ● Popular Question (source) |
| 2017-12-29 09:27:33 -0600 | received badge | ● Famous Question (source) |
| 2017-06-19 05:30:53 -0600 | received badge | ● Notable Question (source) |
| 2017-04-22 14:28:16 -0600 | marked best answer | Can a paper printed chessboard affect camera calibration? In calibrating my camera, I used a paper printed chessboard. I guess because of the nature of the paper, it is not "perfect" since there will be some crumples/wrinkles. In 15 images that I have used, below are 3 of the examples of the original image, and its undistorted version.
As you can see, there are some wrinkles at the paper (especially at the edge). Can this somehow greatly affects the camera matrix and distortion coefficients that will be calculated, or I am just being overly paranoid here? Thanks. |
| 2017-03-28 13:00:43 -0600 | received badge | ● Popular Question (source) |
| 2017-03-10 00:07:36 -0600 | commented answer | How is the basic pipeline of 3D reconstruction from more than two images? I have read a bit on that topic (I own that book). But I believe that is just for 3 images. How if the images are arbitrary? Any idea? I also have made some search and looks like OpenCV's solvePnP can be used, although I am not really sure how. Any links/keywords that I can try to look more? That would be very helpful. |
| 2017-02-13 01:39:51 -0600 | asked a question | How is the basic pipeline of 3D reconstruction from more than two images? I am doing 3D reconstruction using OpenCV with Python and I have already reconstructed the 3D structure from two images. Let us named the images as image_1 and image_2. So, I want to add another view from the third image, image_3. What I understood, it has to do with Bundle Adjustment, but I have a problem on understanding how things should be done. So, to make my pipeline more simple, I have decided to use the Python's sba module, which is explained as the wrapper for Lourakis' sparse bundle adjustment C library. Basically, what I understood is that I will need to pass the 3D points of a structure, and their corresponding 2D points from multiple images. For the example given with source code, it looks something like this: From the first to eighth column, this is what it represents:
The 5th, 6th, 7th, 8th column all have the same meaning as the 3rd and 4th column. As for my condition, I have made a 3D reconstruction called structure_1 from image_1 and image_2. Then I have also made a 3D reconstruction called structure_2 from image_2 and image_3. Then, consider that a point called point_1 is visible in image_1, image_2 and image_3. This means, I have two 3D points (from structure_1 and structure_2) for point_1. How should I make it as the example in the source code? The source code already has a 3D point from three views as shown in above snippet. |
| 2017-02-11 04:57:16 -0600 | marked best answer | What does the getOptimalNewCameraMatrix function does? For example, in this tutorial, I have some problems in understanding the
What does "free scaling parameter" means? I hope someone can give explanation and maybe some examples on this. Thanks. |
| 2016-12-26 18:59:00 -0600 | commented question | How to construct 3D representation of the scene with more than 2 images? My goal is more into trying to understand the essence of the SfM first. Because of that, I am not using the more complete library that already has the pipeline implemented. I also want to tweak a lot of stuff and experimenting. That is why I am using OpenCV since it is more general (has other CV algorithms) and I can try many things with it. Also, I am using mac and having problems to build the OpenCV with the SfM module. Or do you have any idea in what is the best library I can used to achieve my goal? |
| 2016-12-24 22:10:45 -0600 | asked a question | How to construct 3D representation of the scene with more than 2 images? From a video, I have took three images: i1, i2 and i3. The steps in getting the keypoints in each of the image are:
Then, from the corresponding keypoints in i1 and i2, I managed to build the 3d representation. So, using the same pipeline, of course I also managed to reconstruct the 3d representation from the corresponding keypoints in i2 and i3. So, I want to build a scene using these 2 reconstructed 3d scene. I have done a little bit of reading, and I stuck in some parts. So, I know I will need to call the |
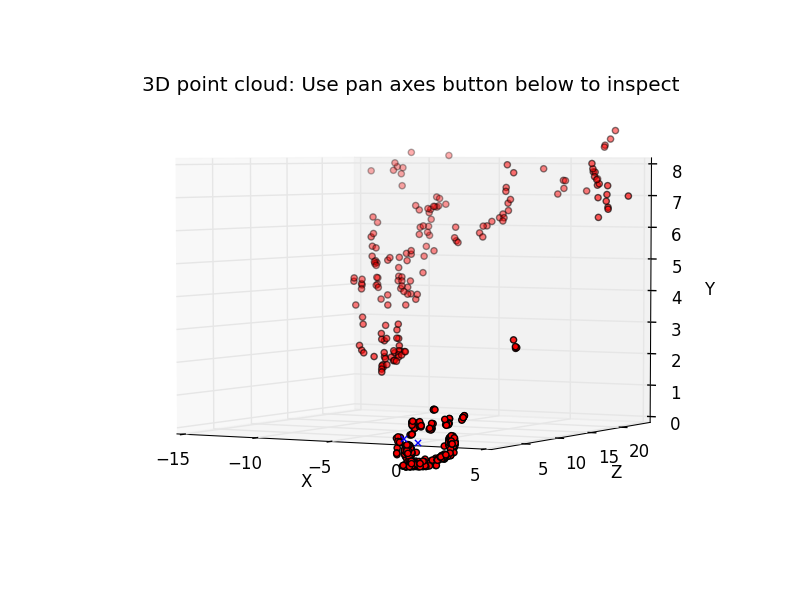
| 2016-12-16 05:33:19 -0600 | asked a question | 3D reconstruction (SfM) - confusion with camera's extrinsic parameter From two images (with known camera intrinsic parameter), I follow the usual pipeline to reconstruct its 3D points. In particular, I use the Below are the two images (with highlighted keypoints used for 3D reconstruction) and the reconstructed scene.
The two blue X marks above are camera 1 and camera 2 position (here, I have multiplied camera 2's translation with -1 to get a positive x value). |
| 2016-11-26 17:09:05 -0600 | asked a question | Undistort images or not before finding the Fundamental/Essential Matrix? I am quite confused right now. In order to find the Fundamental Matrix and the Essential Matrix, my common way is by first, undistort the images before did the other processes like detecting keypoints, matching the keypoints, find the Fundamental Matrix and then, the Essential Matrix. Is this correct? Can I not undistort the images in order to find the Fundamental Matrix and the Essential Matrix? Another question is, as for the function |
| 2016-11-14 22:59:48 -0600 | asked a question | Why findFundamentalMat gives different results for same but different orientation of points? Sorry if the title is kind of weird. It is quite hard to express the question of my problem. So, I am in the middle of a 3D reconstruction project. The pipeline is more or less the same with the standard pipeline where
and so on. The only different part is at step 2 where I use a Line Segment Detector and track it across frames. So, if I am using a keypoint detector, giving two frame of images, I will get two set of keypoints (each set corresponds to each frame). But as for my situation, I have four set of keypoints (each two set correspond to each frame since a line has a start point and an end point). In order to calculate the Fundamental matrix, I need to concatenate the two sets of point of each frame. One way is by just vertically concatenate it: The other way is by : Both will end up with a same shape. But fair enough, they produce a quite different results. From my observation, the The question is why is this? And which one supposed to be better? Below is sample code to give a view of this question: |
| 2016-09-18 23:56:32 -0600 | edited question | Problem with getOptimalNewCameraMatrix I want to calibrate a car video recorder and use it for 3D reconstruction with Structure from Motion (SfM). The original size of the pictures I have took with this camera is 1920x1080. Basically, I have been using the source code from the OpenCV tutorial for the calibration. But there are some problems and I would really appreciate any help. So, as usual (at least in the above source code), here is the pipeline:
In my case, since the image is too big (1920x1080), I have resized it to 640x320 and used it for the calibration (during SfM, I will also use this size of image, so, I don't think it would be any problem). And also, I have used a 9x6 chessboard corners for the calibration. Here, the problem arose. After a call to the
You can see the image in the undistorted image is at the bottom left. But, if I didn't call the So, I have two questions.
Below is my source code: |